《Atomic Kotlin》中文版

以下信息来自 Atomic Kotlin 官网
《Atomic Kotlin》 及配套学习资源由 Bruce Eckel 和 Svetlana Isakova 合著。
- 为什么学习 Kotlin?
- JetBrains Connect, Episode 4 – “Why Kotlin?” with Bruce Eckel and Svetlana Isakova
- 2021 年 1 月 11 日:纸质书出版。
- 2020 年 12 月 9 日:电子书完成,并在 Leanpub 发布。
- 原以为本书已经完成了,但经过反复翻阅,我们最终发现了很多需要改进的地方,并根据 Kotlin 1.4 新增了一些资料。现在是真的完成了,这是印刷出来的版本。感谢你的耐心等候,希望你喜欢这本书!
印刷书封面:

第一部分:编程基础
编程有着惊人的诱惑力 — Vint Cerf
本节针对编程初学者。如果你已经是一个有经验的程序员,请跳到总结 1 和总结 2。
介绍
这本书面向初学者和有经验的程序员。
如果您没有编程知识,那么您是一个初学者,但是“有决心”是因为我们会给您足够的知识,让您自己摸索出来。完成学习后,您将对编程和Kotlin有扎实的基础。
如果您是有经验的程序员,请直接跳到总结 1和总结 2,然后从那里继续。
书名中的“Atomic”指的是原子作为最小的不可分割单位。在本书中,我们试图每章只介绍一个概念,因此这些章节无法再细分,因此我们将它们称为原子。
概念
所有编程语言都由特性组成。您可以将这些特性应用于产生结果。Kotlin非常强大,它不仅具有丰富的特性集,而且通常可以用多种方式表达这些特性。
如果所有内容都被过度迅速地介绍给您,您可能会觉得Kotlin“太复杂”。
本书试图避免让您感到不知所措。我们以仔细和有意识的方式教授语言,遵循以下原则:
- 小步和小胜。我们摆脱了章节的束缚。相反,我们将每个小步作为一个原子概念或简称为原子来呈现,它看起来像一个小章节。我们尽量每个原子只介绍一个新概念。一个典型的原子包含一个或多个小的可运行代码片段及其输出结果。
- 没有向前引用。在尽可能的情况下,我们避免说,“这些特性将在后面的原子中解释”。
- 没有引用其他编程语言。除非必要,否则我们不会这样做。一个你不了解的语言中的特性的类比并不有帮助。
- 展示而非叙述。我们更喜欢通过示例和输出来展示一个特性。看到代码中的特性比用语言描述更好。
- 实践优于理论。我们首先展示语言的机制,然后再解释这些特性的存在原因。这与“传统”教学相反,但通常效果更好。
如果您了解特性,就可以理解其含义。通常情况下,理解一页Kotlin代码比理解另一种语言中的等效代码要容易得多。
索引在哪里?
本书是使用Markdown编写的,并使用Leanpub生成。不幸的是,Markdown和Leanpub都不支持索引。然而,通过创建最小可能的章节(原子),每个原子只包含一个主题,目录就充当了一种索引的作用。此外,电子书版本允许在整本书中进行电子搜索。
交叉引用
书中对原子的引用如下所示:Introduction,在这种情况下,它指的是当前的原子。在各种电子书格式中,这将生成一个到该原子的超链接。
格式
在本书中:
- 斜体引入一个新的术语或概念,并有时强调一个想法。
等宽字体表示程序关键字、标识符和文件名。代码示例也使用这种字体,并在电子书版本中进行了着色。- 在散文中,我们在函数名后面加上空括号,例如
func()。这提醒读者他们正在查看一个函数。 - 为了使电子书在所有设备上易于阅读并允许用户增大字体大小,我们将代码清单的宽度限制在47个字符以内。有时这需要妥协,但我们认为结果是值得的。为了实现这些宽度,我们可能会删除许多格式样式中可能包含的空格,特别是我们使用两个空格缩进而不是标准的四个空格缩进。
试读本书
我们在AtomicKotlin.com提供了一本电子书的免费试读样本。样本包括前两个章节的全部内容,以及几个后续的原子。这样,您可以尝试阅读这本书,然后决定是否适合您。
完整的书籍以纸质书和电子书的形式出售。如果您喜欢我们在免费样本中所做的内容,请支持我们,通过购买您使用的内容来帮助我们继续工作。我们希望这本书对您有所帮助,并感谢您的支持。
在互联网时代,似乎不可能控制任何信息。您可能会在许多地方找到本书的电子版本。如果您目前无法购买本书并从这些网站下载了它,请“回报”。例如,一旦您学会了这门语言,帮助其他人学习它。或者以任何他们需要的方式帮助他人。也许将来您会变得更好,然后可以为本书付费。
练习和解答
《Kotlin原子》中的大多数原子都附带了一些小练习。为了加深您的理解,我们建议在阅读完原子后立即解决这些练习。大多数练习可以通过JetBrains IntelliJ IDEA集成开发环境(IDE)的Edu Tools插件自动检查,因此您可以查看自己的进度并在卡住时获得提示。
您可以在http://AtomicKotlin.com/exercises/找到以下链接。
要解决这些练习,按照以下教程安装带有Edu Tools插件的IntelliJ IDEA:
在课程中,您将找到所有练习的解答。如果您在解决练习时遇到困难,请查看提示或尝试偷看解答。我们仍然建议您自己实现它。
如果在设置和运行课程时遇到任何问题,请阅读故障排除指南。如果这不能解决您的问题,请按照指南中提到的方式联系支持团队。
如果您发现课程内容中的错误(例如,任务的测试产生错误的结果),请使用我们的问题跟踪器报告问题,这是预填充的表单。请注意,您需要登录到YouTrack。感谢您花时间帮助我们改进课程!
研讨会
您可以在AtomicKotlin.com找到关于实时研讨会和其他学习工具的信息。
会议
布鲁斯组织开放空间会议,例如Winter Tech Forum。订阅邮件列表,以便在AtomicKotlin.com上获得有关我们活动和演讲的信息。
支持我们
这是一个大项目。制作这本书和配套的支持材料需要时间和精力。如果您喜欢这本书,并希望看到更多类似的东西,请支持我们:
- 博客、推特等,告诉您的朋友。这是一次基层的营销活动,您所做的一切都将有所帮助。
- 购买本书的电子书或印刷版,请访问AtomicKotlin.com。
- 检查 AtomicKotlin.com 上的其他支持产品或活动。
关于我们
布鲁斯·埃克尔(Bruce Eckel)是《Java编程思想》和《C++编程思想》等多项屡获殊荣的著作的作者,他还写了其他关于计算机编程的书籍,包括《Atomic Scala》。他在世界各地进行了数百场演讲,并举办了类似Winter Tech Forum和开发者撤退等的替代性会议和活动。布鲁斯拥有应用物理学学士学位和计算机工程硕士学位。他的博客位于www.BruceEckel.com,他的咨询、培训和会议业务是Mindview LLC。
Svetlana Isakova起初是Kotlin编译器团队的成员,现在是JetBrains的开发者倡导者。她教授Kotlin,并在世界各地的会议上发表演讲,并且是书籍《Kotlin in Action》的合著者。
致谢
- Kotlin语言设计团队和贡献者。
- Leanpub的开发人员,使出版这本书变得更加容易。
献辞
为我敬爱的父亲E. Wayne Eckel。1924年4月1日-2016年11月23日。您首先教会我有关机器、工具和设计的知识。
为我的父亲Sergey Lvovich Isakov,他过早地离开了我们,我们将永远怀念他。
封面说明
Daniel Will-Harris根据Kotlin标志设计了封面。
为什么选择Kotlin?
我们将概述编程语言的历史发展,以便您了解Kotlin的定位以及为什么您可能想要学习它。对于初学者来说,本节介绍的一些主题可能现在看起来过于复杂。您可以随时跳过这一节,在阅读更多本书后再回来阅读。
程序必须为人类阅读而编写,而仅仅偶然为了机器执行。— Harold Abelson,《计算机程序的结构与解释》
编程语言设计是一条从满足机器需求到满足程序员需求的进化路径。
编程语言由语言设计师发明,并作为一种或多种用于使用该语言的工具的程序进行实现。实施者通常是语言设计师,至少在最初是这样。
早期的语言关注硬件限制。随着计算机变得更加强大,新的语言转向更复杂的编程,并强调可靠性。这些语言可以根据编程心理学选择功能。
每种编程语言都是一系列的实验。从历史上看,编程语言设计是一连串猜测和假设的历程,试图使程序员更具生产力。其中一些实验失败,一些稍微成功,一些非常成功。
我们从每种新语言的实验中学到了很多。有些语言解决的问题后来被发现是次要的而不是必要的,或者环境发生了变化(处理器速度更快、内存更便宜、对编程和语言的理解更深入),那个问题变得不那么重要甚至不重要。如果这些思想过时了而语言没有发展,那么它就会被淡出使用。
最初的程序员直接使用表示处理器机器指令的数字进行工作。这种方法产生了许多错误,并创建了汇编语言以用助记符操作码(程序员更容易记住和阅读的单词)替换数字,以及其他有用的工具。然而,汇编语言指令和机器指令之间仍然存在一对一的对应关系,程序员需要编写每一行汇编代码。此外,每个计算机处理器都使用自己独特的汇编语言。
在汇编语言中开发程序非常昂贵。高级语言通过从低级汇编语言中创建一层抽象来解决这个问题。
编译器和解释器
Kotlin是编译而不是解释的。解释语言的指令由一个独立的程序,称为解释器,直接执行。相比之下,编译语言的源代码会被转换为不同的表示形式,作为自己的程序运行,可以直接在硬件处理器上运行,也可以在模拟处理器的虚拟机上运行:
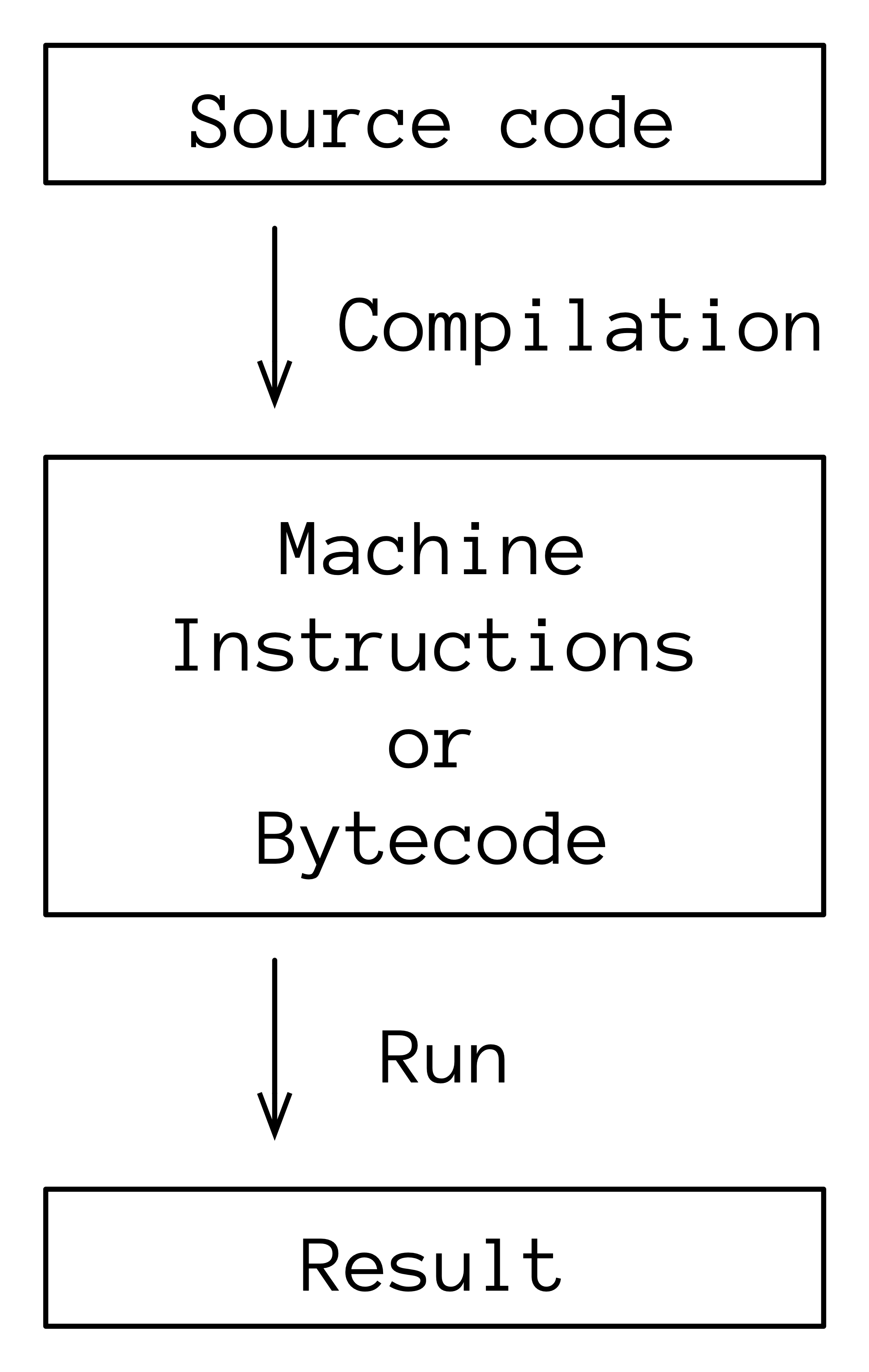
诸如C、C++、Go和Rust之类的语言编译成在底层硬件的中央处理器(CPU)上直接运行的机器代码。而Java和Kotlin等语言编译成字节码,它是一种中间级格式,不直接在硬件CPU上运行,而是在虚拟机上运行,虚拟机是一个执行字节码指令的程序。Kotlin的JVM版本运行在Java虚拟机(JVM)上。
可移植性是虚拟机的一个重要优点。相同的字节码可以在每台安装了虚拟机的计算机上运行。虚拟机可以针对特定硬件进行优化以解决速度问题。JVM包含多年的这种优化,并已在许多平台上实施。
在编译时,编译器会检查代码以发现编译时错误(IntelliJ IDEA和其他开发环境会在您输入代码时突出显示这些错误,以便您可以快速发现和修复任何问题)。如果没有编译时错误,源代码将被编译成字节码。
运行时错误在编译时无法检测到,因此只有在运行程序时才会出现。通常,运行时错误更难发现,修复起来更加昂贵。静态类型语言(如Kotlin)会尽可能多地在编译时发现错误,而动态语言会在运行时执行安全检查(某些动态语言可能不执行太多的安全检查)。
影响 Kotlin 的编程语言
Kotlin从许多编程语言中汲取了想法和特性,而这些编程语言又受到了早期编程语言的影响。了解一些编程语言的历史可以让我们更好地理解 Kotlin 的由来。这里选择的语言是因为它们对后续语言产生了影响。这些语言最终启发了 Kotlin 的设计,有时是通过成为一种要避免的示例。
FORTRAN: FORmula TRANslation(1957)
Fortran是为科学家和工程师设计的,其目标是更容易地编写方程式。经过精心调试和测试的 Fortran 库仍然在今天使用,但通常会进行“封装”,以便从其他语言调用它们。
LISP: LISt Processor(1958)
LISP不是针对特定应用程序,而是体现了基本的编程概念;它是计算机科学家使用的语言,也是第一种函数式编程语言(您将在本书中学习函数式编程)。LISP 的强大和灵活性换来的是效率问题:在早期计算机上运行 LISP 通常代价太高,直到最近几十年,机器速度才足够快,才出现了 LISP 的复兴。例如,GNU Emacs 编辑器完全是用 LISP 编写的,并且可以使用 LISP 进行扩展。
ALGOL: ALGOrithmic Language(1958)
可以说是 1950 年代最有影响力的语言,因为它引入了在许多后续语言中仍然存在的语法。例如,C 及其派生语言都是“类 ALGOL”语言。
COBOL: COmmon Business-Oriented Language(1959)
COBOL是为业务、财务和行政数据处理而设计的。它具有类似英语的语法,并且旨在具有自解释和高可读性。尽管这种意图通常失败了,COBOL 因为错误的点号引入的 bug 而出了名——但美国国防部强制在大型机上广泛采用了 COBOL,并且至今仍在运行(并需要维护)。
BASIC: Beginners' All-purpose Symbolic Instruction Code(1964)
BASIC 是早期使编程变得简单易学的尝试之一。尽管非常成功,但它的功能和语法有限,因此对于需要学习更复杂语言的人来说只有一定的帮助。它主要是一种解释型语言,这意味着要运行它,您需要原始的程序代码。尽管如此,许多有用的程序都是用 BASIC 编写的,尤其是作为微软的“Office”产品的脚本语言。BASIC 甚至可以被认为是第一个“开放”的编程语言,因为人们制作了许多变种。
Simula 67,最早的面向对象语言(1967)
模拟通常涉及许多相互交互的“对象”。不同的对象具有不同的特征和行为。当时存在的语言在模拟方面使用起来很笨拙,因此开发了 Simula(另一种“类 ALGOL”语言),以提供直接支持创建模拟对象。事实证明,这些思想对于通用编程也非常有用,这就是面向对象(OO)语言的起源。
Pascal(1970)
Pascal通过限制语言,使其可以实现为单通道编译器,从而提高了编译速度。该语言强制程序员以特定方式组织代码,并对程序组织施加了一些笨拙且不太可读的约束。随着处理器变得更快、内存更便宜和编译器技术的改进,这些约束的影响变得过于昂贵。
Pascal的一种实现,Borland的Turbo Pascal,最初适用于 CP/M 机器,然后转移到早期的 MS-DOS(Windows 的前身),后来演变为适用于 Windows 的 Delphi 语言。通过将所有内容放入内存,Turbo Pascal 在性能较差的机器上编译速度极快,极大改善了编程体验。Turbo Pascal 的创建者 Anders Hejlsberg 后来设计了 C# 和 TypeScript。
Pascal 的发明者 Niklaus Wirth 还创建了后续的语言:Modula、Modula-2 和 Oberon。正如名称所示,Modula 侧重于将程序分解为模块,以实现更好的组织和更快的编译。大多数现代语言支持分离编译和某种形式的模块系统。
C(1972)
尽管出现了越来越多的高级语言,程序员仍然在编写汇编语言。这通常被称为系统编程,因为它是在操作系统级别进行的,但它还包括针对专用物理设备的嵌入式编程。这不仅费时费力(Bruce在他的职业生涯开始时就编写过嵌入式系统的汇编语言),而且不可移植——汇编语言只能在编写它的处理器上运行。C 被设计为一种“高级汇编语言”,仍然与硬件紧密相关,以至于很少需要编写汇编语言。更重要的是,C 程序可以在任何具有 C 编译器的处理器上运行。C 将程序与处理器分离,解决了一个巨大而昂贵的问题。因此,以前的汇编语言程序员在 C 中可以大大提高生产力。C语言非常有效,以至于最近的一些语言(尤其是Go和Rust)仍然试图取代它成为系统编程的首选语言。
Smalltalk(1972年)
Smalltalk从一开始就被设计成纯粹的面向对象语言。通过作为一个实验平台和展示快速应用开发的工具,Smalltalk在推动面向对象和语言理论方面取得了显著进展。然而,在Smalltalk诞生时,编程语言仍然是专有的,购买一个Smalltalk系统可能需要花费成千上万的价格。它是一种解释型语言,因此需要一个Smalltalk环境来运行程序。直到编程世界已经发展了很久之后,开源的Smalltalk实现才出现。Smalltalk程序员为后来的C++和Java等面向对象语言做出了重要贡献。
C++:更好的C语言与对象(1983年)
Bjarne Stroustrup创建C++的原因是他想要一个更好的C语言,并且希望能够支持他在使用Simula-67时遇到的面向对象的构造。Bruce曾在C++标准委员会任职八年,并撰写了三本关于C++的书籍,包括《Thinking in C++》。
与C的向后兼容性是C++设计的基本原则之一,因此可以几乎不修改地将C代码编译为C++代码。这为程序员提供了一条简便的迁移路径,他们可以继续使用C进行编程,享受C++的好处,并在保持生产力的同时逐步尝试C++的特性。大多数对C++的批评可以追溯到与C的向后兼容性的约束。
C语言的一个问题是内存管理。程序员必须首先获取内存,然后在使用该内存的操作中运行,最后释放内存。忘记释放内存会导致内存泄漏,可能会消耗掉可用内存并使进程崩溃。最初的C++版本在这个领域做出了一些创新,包括使用构造函数确保正确初始化。语言的后续版本在内存管理方面进行了重大改进。
Python:友好而灵活(1990年)
Python的设计者Guido Van Rossum根据他对“面向所有人的编程”的启发创建了这门语言。他对Python社区的培育使其在编程界赢得了友好和支持性最强的声誉。Python是最早的开源语言之一,几乎在所有平台上都有实现,包括嵌入式系统和机器学习。它的动态性和易用性使其非常适合自动化处理小型重复任务,同时其特性也支持开发大型复杂程序。
Python是一门真正的“草根”语言;它从未有过推广它的公司,而其粉丝们的态度是从不推动该语言,而只是帮助任何想学习它的人。这门语言不断改进,近年来其受欢迎程度飙升。
Python可能是第一门将函数式和面向对象编程结合起来的主流语言。它在自动内存管理方面领先于Java(通常无需自己分配或释放内存),并且可以在多个平台上运行程序。
Haskell(1990年):纯函数式编程
受专有语言Miranda(1985年)的启发,Haskell作为一个开放标准被创建,用于纯函数式编程的研究,尽管它也被用于产品开发。Haskell的语法和思想影响了许多后来的语言,包括Kotlin。
Java(1995年):虚拟机和垃圾回收
詹姆斯·高斯林(James Gosling)和他的团队被派任务为一台电视机顶盒编写代码。他们决定不使用C++,而是创建了Java语言。当时,Sun Microsystems公司大力推广这种免费语言(这在当时还是一个新概念),以试图在新兴的互联网领域占据主导地位。
这种被视为互联网主导时机的压力使Java语言设计承受了很大的压力,结果导致了大量的缺陷(《Thinking in Java》一书揭示了这些缺陷,以便读者能够应对它们)。甲骨文公司(Oracle)的布赖恩·戈茨(Brian Goetz),目前是Java的首席开发人员,尽管面临着继承的限制,但在Java方面取得了显著而令人惊讶的改进。尽管Java非常成功,但Kotlin的一个重要设计目标是修复Java的缺陷,以便程序员能够更加高效。
Java的成功源于两个创新功能:虚拟机和垃圾回收。其他语言也提供了这些功能,例如LISP、Smalltalk和Python都具有垃圾回收功能,UCSD Pascal在虚拟机上运行,但它们从未被认为适用于主流语言。Java改变了这一点,并因此使程序员的工作效率显著提高。
虚拟机是语言和硬件之间的中间层。语言不需要为特定处理器生成机器代码;它只需要生成在虚拟机上运行的中间语言(字节码)。虚拟机需要处理能力,在Java之前被认为是不切实际的。Java虚拟机(JVM)催生了Java的口号“一次编写,到处运行”。此外,其他语言可以更容易地通过针对JVM开发;例如Groovy是一种类似Java的脚本语言,Clojure是一种LISP的变种。
垃圾回收解决了忘记释放内存或难以确定何时不再使用某个存储单元的问题。由于内存泄漏,许多项目被大大延迟甚至取消。尽管垃圾回收在一些之前的语言中已经存在,但人们认为它会产生无法接受的开销,直到Java证明了其实用性。
JavaScript(1995年):名字上的Java而已
最初的Web浏览器只是从Web服务器复制和显示页面。Web浏览器的数量不断增加,成为需要语言支持的新的编程平台。Java希望成为这种语言,但对于这个工作来说过于笨拙。JavaScript最初被称为LiveScript,并内置于NetScape Navigator中,这是最早的Web浏览器之一。将其改名为JavaScript是NetScape的一种营销策略,因为这种语言与Java只有模糊的相似之处。
随着Web的发展,JavaScript变得非常重要。然而,JavaScript的行为如此不可预测,以至于道格拉斯·克罗克福德(Douglas Crockford)写了一本名为《JavaScript权威指南》的书,他在其中以嬉笑怒骂的方式展示了这门语言的所有问题,以便程序员可以避免它们。ECMAScript委员会的后续改进使得JavaScript对于最初的JavaScript程序员来说几乎无法识别。它现在被认为是一门稳定而成熟的语言。
WebAssembly(WASM)是从JavaScript衍生出来的一种Web浏览器的字节码。它通常比JavaScript运行速度更快,并且可以由其他语言生成。截至目前,Kotlin团队正在努力将WASM作为一个目标添加到语言中。
C#(2000年):针对.NET的Java
C#的设计目标是在.NET(Windows)平台上提供与Java相似的重要功能,同时使设计者摆脱遵循Java语言的限制。其结果包括许多对Java的改进。例如,C#引入了扩展函数(extension functions)的概念,这在Kotlin中被广泛使用。C#也比Java更具有函数式编程的特性。许多C#的特性显然影响了Kotlin的设计。
Scala(2003年):可伸缩的编程语言
Martin Odersky创建了Scala,以在Java虚拟机上运行:借助JVM的工作成果,与Java程序进行交互,并可能取代Java。作为一名研究人员,Odersky和他的团队将Scala作为一个实验语言的平台,尤其是那些未包含在Java中的语言特性。
这些实验是有启发性的,其中一些实验以修改的形式出现在了Kotlin中。例如,重定义像+这样的运算符以在特殊情况下使用被称为运算符重载。这在C++中被包括进去了,但在Java中却没有。Scala增加了运算符重载的功能,但也允许您通过组合任意字符序列来发明新的运算符。这往往会产生令人困惑的代码。Kotlin中包含了一种有限的运算符重载形式,但您只能重载已经存在的运算符。
Scala还是一种对象-函数混合语言,类似于Python,但更注重纯函数和严格对象。这帮助启发了Kotlin也成为一种对象-函数混合语言的选择。
与Scala类似,Kotlin也在JVM上运行,但与Scala相比,它与Java的交互更加容易。此外,Kotlin还支持JavaScript、Android操作系统,并能为其他平台生成本机代码。
《Atomic Kotlin》是根据《Atomic Scala》(http://www.AtomicScala.com)中的思想和内容发展而来的。
Groovy(2007年):一种动态JVM语言
动态语言因其比静态语言更具交互性和简洁性而具有吸引力。在JVM上产生更具动态编程体验的尝试已经有很多,包括Jython(Python)和Clojure(一种Lisp方言)。Groovy是第一个被广泛接受的实现。
乍看之下,Groovy似乎是Java的清理版本,提供了更愉快的编程体验。大多数Java代码在Groovy中可以不作任何修改地运行,因此Java程序员可以迅速提高生产力,然后学习更复杂的功能,这些功能相比Java提供了显著的编程改进。
Kotlin中处理空值问题的运算符?.和?:最早出现在Groovy中。
有许多Groovy的特性在Kotlin中是可以辨认出来的。其中一些特性也出现在其他语言中,这可能更加推动它们被包含在Kotlin中。
为什么选择Kotlin?(引入于2011年,1.0版本于2016年发布)
正如C++最初意图成为“更好的C语言”,Kotlin最初的目标是成为“更好的Java”。但它已经在这个目标之外显著发展。
Kotlin在实践中从其他编程语言中选择了最成功和最有帮助的特性,这些特性经过了实地测试,并被证明特别有价值。
因此,如果您来自另一种语言,您可能会在Kotlin中认出该语言的一些特性。这是有意为之的:Kotlin通过利用经过测试的概念来最大化生产力。
可读性
在语言设计中,可读性是一个主要目标。Kotlin的语法简洁明了,对于大多数情况而言不需要冗长的仪式,但仍能表达复杂的思想。
工具支持
Kotlin来自JetBrains,这是一家专注于开发者工具的公司。它具有一流的工具支持,并且许多语言特性都是针对工具设计的。
多范式
Kotlin支持多种编程范式,并在本书中温和地引入了这些范式:
- 命令式编程
- 函数式编程
- 面向对象编程
多平台
Kotlin的源代码可以编译为不同的目标平台:
- JVM。源代码编译为JVM字节码(
.class文件),可以在任何Java虚拟机(JVM)上运行。 - Android。Android有自己的运行时环境,称为ART(前身为Dalvik)。Kotlin源代码编译为Dalvik可执行格式(
.dex文件)。 - JavaScript,用于在Web浏览器中运行。
- 本机二进制文件,通过生成特定平台和CPU的机器代码。
本书专注于语言本身,并以JVM作为唯一的目标平台。一旦掌握了该语言,您可以将Kotlin应用于不同的应用程序和目标平台。
Kotlin的两个特性
本章并不假定您是一名程序员,这样就很难解释Kotlin相对于其他选择的大部分优势。然而,有两个主题非常有影响力,可以在这个早期阶段进行解释:Java互操作性和表示“无值”的问题。
无缝的Java互操作性
作为“更好的C语言”,C++必须与C的语法保持向后兼容,但Kotlin并不需要与Java的语法保持向后兼容,它只需要与JVM配合工作。这使得Kotlin设计者能够创建一个更清晰、更强大的语法,避免了Java中的视觉噪声和复杂性。
为了成为“更好的Java语言”,尝试Kotlin的体验必须是愉快和无摩擦的,因此Kotlin能够与现有的Java项目轻松集成。您可以编写一个小小的Kotlin功能模块,并将其插入到现有的Java代码中。Java代码甚至不知道Kotlin代码的存在,它只是看起来像更多的Java代码。
公司通常会通过使用某种语言构建一个独立的程序来研究新语言。理想情况下,这个程序是有益但不是必需的,因此如果项目失败,可以以最小的损失终止它。并不是每个公司都愿意为这种类型的实验投入必要的资源。由于Kotlin可以与现有的Java系统无缝集成(并受益于该系统的测试),因此尝试Kotlin以查看是否适合变得非常廉价甚至免费。
此外,为Kotlin创建的JetBrains公司提供了IntelliJ IDEA的“Community”(免费)版本,其中包括对Java和Kotlin的支持以及轻松集成两者的能力。它甚至还提供了一个工具,将Java代码(大部分)重写为Kotlin代码。
附录B介绍了Java互操作性。
表示空值
Kotlin的一个特别有益的功能是解决了一个棘手的编程问题。
当有人给您一本字典,并要求您查找一个不存在的单词时,您会怎么做?您可以通过为未知单词编造定义来保证结果。更有用的方法是简单地说:“这个单词没有定义。”这展示了编程中的一个重要问题:如何表示未初始化的存储空间或操作的结果的“无值”?
*空引用(null reference)*是由Tony Hoare于1965年为ALGOL语言发明的,他后来称其为“我一生中价值数十亿美元的错误”。其中一个问题是它过于简单,有时仅仅告诉一个房间是空的是不够的;您可能需要知道它为空的原因。这导致了第二个问题:实现。出于效率考虑,通常只是一个特殊的值,可以适应少量内存,并且何不使用已经为该信息分配的内存呢?
原始的C语言不会自动初始化存储空间,这引发了许多问题。C++通过将新分配的存储空间设置为全零来改善了情况。因此,如果数值没有初始化,它就是一个数值零。这看起来并不那么糟糕,但它允许未初始化的值悄悄地通过漏洞滑入(新的C和C++编译器经常对此发出警告)。更糟糕的是,如果一个存储空间是一个指针,用于指示(“指向”)另一个存储空间,那么一个空指针将指向内存中的位置零,而这几乎肯定不是您想要的。
Java通过在运行时报告这些未初始化值的访问错误来防止访问未初始化值。尽管这可以发现未初始化值,但它并没有解决问题,因为您只能通过运行程序来验证您的程序不会崩溃。Java代码中有大量此类错误,程序员浪费了大量时间来查找它们。
Kotlin通过在程序运行之前,在编译时阻止可能导致空错误的操作,解决了这个问题。这是Java程序员接受Kotlin时最受欢迎的单一特性。这个特性可以最大程度地减少或消除Java的空错误。
多种好处
我们在这里能够解释的两个特性(无需更多的编程知识)对您是否是Java程序员都有很大的影响。如果Kotlin是您的第一种语言,并且您最终参与需要更多程序员的项目,那么招募众多现有的Java程序员进入Kotlin会更加容易。
Kotlin还有许多其他好处,但在您了解更多编程知识之前,我们无法对其进行解释。这就是本书的余下部分的目的。
语言通常是出于热情而选择的,而不是理性... 我正在努力使Kotlin成为一种因为理由而受人喜爱的语言。 ——Andrey Breslav,Kotlin首席语言设计师。
Hello, World!
“Hello, world!”是一个常用的程序,用于演示编程语言的基本语法。
我们将分几个步骤来开发这个程序,以便您了解它的组成部分。
首先,让我们来看一个什么也不做的空程序:
// HelloWorld/EmptyProgram.kt
fun main() {
// 程序代码在这里...
}
这个示例以一个注释开始,注释是Kotlin忽略的说明性文本。//(两个正斜杠)表示从注释开始一直到当前行的结尾:
// 单行注释
Kotlin会忽略//和之后的所有内容,直到行尾。在下一行,Kotlin会重新开始解析代码。
本书中每个示例的第一行都是一个注释,以源代码文件所在的子目录名称开头(在这里是HelloWorld),后面跟着文件的名称:EmptyProgram.kt。每个小节的示例子目录与该小节的名称相对应。
关键字是语言保留的特殊单词,具有特定的含义。关键字fun是函数的缩写。函数是一组可以使用该函数名称执行的代码(我们在整本书中都会详细介绍函数)。函数的名称跟在fun关键字后面,所以在这个例子中是main()(在散文中,我们会在函数名称后面加上括号)。
main()实际上是一个函数的特殊名称,它表示Kotlin程序的“入口点”。Kotlin程序可以有许多具有不同名称的函数,但是在执行程序时,main()函数会自动被调用。
参数列表跟在函数名称后面,并由括号括起来。在这里,我们没有将任何内容传递给main(),所以参数列表是空的。
函数体位于参数列表之后。它以左大括号({)开始,以右大括号(})结束。函数体包含语句和表达式。语句产生一个效果,而表达式则产生一个结果。
EmptyProgram.kt在函数体中没有任何语句或表达式,只有一个注释。
让我们通过在main()的函数体中添加一行代码来显示“Hello, world!”:
// HelloWorld/HelloWorld.kt
fun main() {
println("Hello, world!")
}
/* Output:
Hello, world!
*/
显示问候语的代码行以println()开头。与main()类似,println()是一个函数。这行代码调用了该函数,从而执行函数体。你需要给出函数名称,后面跟着括号,括号中包含一个或多个参数。在本书中,当在文中提到函数时,我们在名称后面加上括号,以提醒读者它是一个函数。在这里,我们写作println()。
println()接受一个参数,该参数是一个String(字符串)。你可以通过将字符放在引号内来定义一个String。
在显示参数后,println()将光标移到新的一行,因此后续的输出将出现在下一行。你也可以使用print(),它将光标保留在同一行。
与某些语言不同,你在Kotlin中不需要在表达式的末尾加上分号。只有在一行上放置多个表达式时才需要分号(这种做法是不鼓励的)。
在本书的一些示例中,我们在列表结束时显示输出结果,放在一个多行注释内。多行注释以/*(斜杠后跟星号)开头,并继续——包括换行符(我们称之为换行符)——直到*/(星号后跟斜杠)结束注释:
/* 这是一个多行注释
不关心
换行符 */
可以在注释的结束标记*/之后的同一行上添加代码,但这样会导致混淆,所以人们通常不这样做。
注释提供了从代码中无法直接得出的信息。如果注释只是重复代码的含义,它们会变得很烦人,人们会开始忽略它们。当代码发生变化时,程序员经常忘记更新注释,因此明智地使用注释是一种好的实践,主要用于突出你的代码中棘手的方面。
练习和解答可在 www.AtomicKotlin.com 上找到。
var 和 val
当标识符保存数据时,您必须决定它是否可以重新赋值。
您创建标识符来引用程序中的元素。对于数据标识符来说,最基本的决策是它是否可以在程序执行过程中更改其内容,或者是否只能被赋值一次。这由两个关键字控制:
var,代表变量,意味着您可以重新赋值其内容。val,代表值,意味着您只能初始化它;不能重新赋值。
您可以像这样定义一个var:
var 标识符 = 初始化值
var关键字后面是标识符,等号和初始化值。标识符以字母或下划线开头,后跟字母、数字和下划线。区分大小写(因此thisvalue和thisValue是不同的)。
这里是一些var定义的示例:
// VarAndVal/Vars.kt
fun main() {
var whole = 11 // [1]
var fractional = 1.4 // [2]
var words = "Twas Brillig" // [3]
println(whole)
println(fractional)
println(words)
}
/* 输出:
11
1.4
Twas Brillig
*/
在本书中,我们使用带有注释的方括号标记行号,以便我们可以在文本中引用它们,如下所示:
- [1] 创建一个名为
whole的var,并将11存储在其中。 - [2] 在
var fractional中存储“分数”1.4。 - [3] 在
var words中存储一些文本(String)。
请注意,println()可以将任何单个值作为参数。
正如名称“变量”所暗示的那样,var是可变的。也就是说,您可以更改存储在var中的数据。我们说var是可变的:
// VarAndVal/AVarIsMutable.kt
fun main() {
var sum = 1
sum = sum + 2
sum += 3
println(sum)
}
/* 输出:
6
*/
赋值语句sum = sum + 2获取sum的当前值,加上2,并将结果重新赋值给sum。
赋值语句sum += 3与sum = sum + 3的意思相同。+=运算符获取sum中存储的先前值,并将其增加3,然后将新的结果赋值回sum。
更改var中存储的值是表示变化的一种有用方式。然而,当程序的复杂性增加时,如果您的标识符表示的值不能更改,即不能重新分配,您的代码将更清晰、更安全、更易于理解。我们使用val关键字而不是var来指定一个不可变的标识符。val只能在创建时被赋值一次:
val identifier = initialization
val关键字来自于"value",表示不可变的、不能改变的内容。选择使用val而不是var是一个很好的选择。在本节的开始处,Vars.kt示例可以使用val进行重写:
// VarAndVal/Vals.kt
fun main() {
val whole = 11
// whole = 15 // Error // [1]
val fractional = 1.4
val words = "Twas Brillig"
println(whole)
println(fractional)
println(words)
}
/* 输出:
11
1.4
Twas Brillig
*/
- [1] 一旦你初始化了一个
val,你就不能重新分配它。如果我们尝试将whole重新分配给一个不同的数字,Kotlin会报错,显示“Val cannot be reassigned.”(不能重新分配val)。
选择描述性的名称作为你的标识符可以使你的代码更易于理解,并且通常减少了对注释的需求。在Vals.kt中,你无法知道whole代表什么。如果你的程序将数字11存储为表示喝咖啡的时间,那么如果你将其命名为coffeetime,那么对其他人来说更明显,如果它是coffeeTime(遵循Kotlin的风格,我们将首字母小写)。
var在程序运行时数据必须发生变化时很有用。这听起来像是一个常见的要求,但实际上在实践中可以避免。通常情况下,如果你使用val,你的程序更容易扩展和维护。然而,在极少数情况下,使用val无法解决问题的复杂性。因此,Kotlin给你提供了使用var的灵活性。然而,当你花费更多时间使用val时,你会发现几乎不需要使用var,而且没有var的程序更安全可靠。
练习和解答可以在www.AtomicKotlin.com找到。
数据类型
数据可以有不同的类型。
为了解决一个数学问题,你写了一个表达式:
5.9 + 6
你知道将这些数字相加会产生另一个数字。Kotlin也知道这一点。你知道其中一个是一个小数(5.9),Kotlin将其称为Double,而另一个是一个整数(6),Kotlin将其称为Int。你知道结果是一个小数。
类型(也称为数据类型)告诉Kotlin你打算如何使用这些数据。类型提供了一组值,从中表达式可以取得其值。类型定义了可以对数据执行的操作,数据的含义以及如何存储该类型的值。
Kotlin使用类型来验证你的表达式是否正确。在上面的表达式中,Kotlin创建了一个新的Double类型的值来保存结果。
Kotlin试图适应你的需求。如果你要求它执行违反类型规则的操作,它会产生一个错误消息。例如,尝试将一个String和一个数字相加:
// DataTypes/StringPlusNumber.kt
fun main() {
println("Sally" + 5.9)
}
/* Output:
Sally5.9
*/
类型告诉Kotlin如何正确地使用它们。在这种情况下,类型规则告诉Kotlin如何将一个数字添加到一个String中:通过连接这两个值并创建一个String来保存结果。
现在尝试将String和Double相乘,将StringPlusNumber.kt中的+改为*:
"Sally" * 5.9
这种方式的类型组合对Kotlin来说没有意义,因此它会给出一个错误。
在var和val中,我们存储了几种类型的值。Kotlin根据我们使用它们的方式推断出了类型。这被称为类型推断。
我们可以更明确地指定类型:
val identifier: Type = initialization
你首先使用val或var关键字,然后是标识符,冒号,类型,一个等号和初始化值。所以,不必像这样写:
val n = 1
var p = 1.2
你可以这样写:
val n: Int = 1
var p: Double = 1.2
我们告诉Kotlin n 是一个 Int 类型, p 是一个 Double 类型,而不是让它推断类型。
以下是Kotlin的一些基本类型:
// DataTypes/Types.kt
fun main() {
val whole: Int = 11 // [1]
val fractional: Double = 1.4 // [2]
val trueOrFalse: Boolean = true // [3]
val words: String = "A value" // [4]
val character: Char = 'z' // [5]
val lines: String = """Triple quotes let
you have many lines
in your string""" // [6]
println(whole)
println(fractional)
println(trueOrFalse)
println(words)
println(character)
println(lines)
}
/* Output:
11
1.4
true
A value
z
Triple quotes let
you have many lines
in your string
*/
- [1]
Int数据类型是一个 整数,它只能保存整数。 - [2] 要保存小数,使用
Double。 - [3]
Boolean数据类型只能保存两个特殊值true和false。 - [4]
String保存字符序列。你可以使用双引号的String赋值。 - [5]
Char保存一个字符。 - [6] 如果你有多行和/或特殊字符,可以用三重双引号括起来(这是一个 三重引号字符串)。
Kotlin使用类型推断来确定混合类型的含义。例如,在加法中混合使用Int和Double时,Kotlin会决定结果值的类型:
// DataTypes/Inference.kt
fun main() {
val n = 1 + 1.2
println(n)
}
/* Output:
2.2
*/
当使用类型推断将Int与Double相加时,Kotlin确定结果 n 是一个 Double 类型,并确保它遵循 Double 的所有规则。
Kotlin的类型推断是其为程序员做工作的策略的一部分。如果省略类型声明,Kotlin通常可以推断出类型。
练习和解答可以在www.AtomicKotlin.com找到。
函数
函数就像是一个小程序,它有自己的名称,可以通过从另一个函数调用该名称来执行(调用)。
函数将一组活动组合在一起,是组织程序和重用代码的最基本方法。
你将信息传递给函数,函数使用该信息来计算并产生结果。函数的基本形式是:
fun 函数名(参数1: 类型1, 参数2: 类型2, ...): 返回类型 {
代码行
return 结果
}
参数1 和 参数2 是参数:你传递给函数的信息。每个参数都有一个标识符名称(参数1,参数2),后跟一个冒号和该参数的类型。参数列表的闭合括号后跟一个冒号和函数产生的结果类型。函数体中的代码行被括在大括号中。return 关键字后面的表达式是函数完成时产生的结果。
参数是你定义传递到函数中的内容,它是占位符。参数值是你实际传递给函数的实际值。
名称、参数和返回类型的组合称为函数签名。
以下是一个名为 multiplyByTwo() 的简单函数示例:
// Functions/MultiplyByTwo.kt
fun multiplyByTwo(x: Int): Int { // [1]
println("Inside multiplyByTwo") // [2]
return x * 2
}
fun main() {
val r = multiplyByTwo(5) // [3]
println(r)
}
/* 输出:
Inside multiplyByTwo
10
*/
- [1] 注意
fun关键字、函数名称以及由单个参数组成的参数列表。这个函数接受一个Int参数并返回一个Int。 - [2] 这两行是函数的主体。最后一行将其计算结果
x * 2的值作为函数的结果返回。 - [3] 这一行通过合适的参数调用函数,并将结果捕获到
val r中。函数调用模仿了其声明的形式:函数名称,后面跟在括号内的参数。
通过调用函数来执行函数代码,使用函数名称 multiplyByTwo() 作为该代码的缩写。这就是为什么函数是编程中最基本的简化和代码重用形式。你还可以将函数视为具有可替代值(参数)的表达式。
println() 也是一个函数调用,它恰好是由 Kotlin 提供的。我们将 Kotlin 定义的函数称为库函数。
如果函数不提供有意义的结果,它的返回类型是 Unit。如果你愿意,可以显式指定 Unit,但 Kotlin 允许你省略它:
// Functions/SayHello.kt
fun sayHello() {
println("Hallo!")
}
fun sayGoodbye(): Unit {
println("Auf Wiedersehen!")
}
fun main() {
sayHello()
sayGoodbye()
}
/* 输出:
Hallo!
Auf Wiedersehen!
*/
sayHello() 和 sayGoodbye() 都返回 Unit,但 sayHello() 省略了显式声明。main() 函数也返回 Unit。
如果一个函数只有一个单独的表达式,你可以使用等号后跟表达式的简化语法:
fun 函数名(参数1: 类型1, 参数2: 类型2, ...): 返回类型 = 表达式
用大括号包围的函数体称为块主体。使用等号语法的函数体称为表达式主体。
在这里,multiplyByThree() 使用了表达式主体:
// Functions/MultiplyByThree.kt
fun multiplyByThree(x: Int): Int = x * 3
fun main() {
println(multiplyByThree(5))
}
/* 输出:
15
*/
这是一种说法 return x * 3 在块主体内的简短版本。
Kotlin 推断带有表达式主体的函数的返回类型:
// Functions/MultiplyByFour.kt
fun multiplyByFour(x: Int) = x * 4
fun main() {
val result: Int = multiplyByFour(5)
println(result)
}
/* 输出:
20
*/
Kotlin 推断 multiplyByFour() 返回一个 Int。
Kotlin 只能推断表达式主体的返回类型。如果函数有一个块主体,并且你省略了其类型,那么函数将返回 Unit。
- -
在编写函数时,选择有描述性的名称。这样可以使代码更易于阅读,通常可以减少对代码注释的需求。在本书中,函数名称可能并不总是像我们希望的那样描述性,因为我们受到了行宽的限制。
练习和解答可在 www.AtomicKotlin.com 找到。
if 表达式
if表达式用于进行选择。
关键字 if 会测试一个表达式,以查看它是否为 true 或 false,并根据结果执行相应的操作。一个真或假的表达式被称为 布尔表达式,这个概念来源于数学家 George Boole,他发明了这些表达式背后的逻辑。以下是使用 >(大于)和 <(小于)符号的示例:
// IfExpressions/If1.kt
fun main() {
if (1 > 0)
println("It's true!")
if (10 < 11) {
println("10 < 11")
println("ten is less than eleven")
}
}
/* 输出:
It's true!
10 < 11
ten is less than eleven
*/
在 if 后的括号中的表达式必须评估为 true 或 false。如果为 true,则执行后续的表达式。要执行多行代码,将它们放在花括号内。
我们可以在一个地方创建布尔表达式,并在另一个地方使用它:
// IfExpressions/If2.kt
fun main() {
val x: Boolean = 1 >= 1
if (x)
println("It's true!")
}
/* 输出:
It's true!
*/
因为 x 是布尔类型,所以可以直接使用 if(x) 来测试。
布尔运算符 >= 返回 true,如果操作符左侧的表达式大于等于右侧的表达式。同样,<= 返回 true,如果左侧的表达式小于等于右侧的表达式。
else 关键字允许处理 true 和 false 两种情况:
// IfExpressions/If3.kt
fun main() {
val n: Int = -11
if (n > 0)
println("It's positive")
else
println("It's negative or zero")
}
/* 输出:
It's negative or zero
*/
else 关键字只能与 if 结合使用。你不仅限于单个检查,你可以通过组合 else 和 if 来测试多个组合:
// IfExpressions/If4.kt
fun main() {
val n: Int = -11
if (n > 0)
println("It's positive")
else if (n == 0)
println("It's zero")
else
println("It's negative")
}
/* 输出:
It's negative
*/
在这里,我们使用 == 来检查两个数字是否相等。!= 用于测试不等式。
通常的模式是从 if 开始,后面跟着所需数量的 else if 子句,最后以最终的 else 结束,用于处理不符合所有先前测试的情况。当 if 表达式变得越来越大和复杂时,你可能会改用 when 表达式。when 表达式将在本书后面的 when 表达式 部分中进行描述。
“非”运算符 ! 用于测试布尔表达式的相反情况:
// IfExpressions/If5.kt
fun main() {
val y: Boolean = false
if (!y)
println("!y is true")
}
/* 输出:
!y is true
*/
要将 if(!y) 转化为口语,可以说 “if not y”。
整个 if 是一个表达式,因此它可以产生一个结果:
// IfExpressions/If6.kt
fun main() {
val num = 10
val result = if (num > 100) 4 else 42
println(result)
}
/* 输出:
42
*/
在这里,我们将整个 if 表达式产生的值存储在一个中间标识符中,称为 result。如果条件满足,则第一个分支产生 result。如果不满足条件,则 else 值变为 result。
让我们练习创建函数。以下是一个接受布尔参数的函数:
// IfExpressions/TrueOrFalse.kt
fun trueOrFalse(exp: Boolean): String {
if (exp)
return "It's true!" // [1]
return "It's false" // [2]
}
fun main() {
val b = 1
println(trueOrFalse(b < 3))
println(trueOrFalse(b >= 3))
}
/* 输出:
It's true!
It's false
*/
布尔参数 exp 被传递给函数 trueOrFalse()。如果参数作为表达式传递,比如 b < 3,那么表达式会首先被求值,然后将结果传递给函数。trueOrFalse() 测试 exp,如果结果为 true,则执行 [1] 行,否则执行 [2] 行。
- [1]
return表示,“离开函数并以此值作为函数的结果”。请注意,return可以出现在函数中的任何位置,不必在结尾处。
与前面的示例不同,你可以使用 else 关键字将结果作为表达式生成:
// IfExpressions/OneOrTheOther.kt
fun oneOrTheOther(exp: Boolean): String =
if (exp)
"True!" // 不需要 'return'
else
"False"
fun main() {
val x = 1
println(oneOrTheOther(x == 1))
println(oneOrTheOther(x == 2))
}
/* 输出:
True!
False
*/
在 trueOrFalse() 中使用了两个表达式,而 oneOrTheOther() 是一个单一表达式。该表达式的结果成为函数的结果,因此 if 表达式成为函数体。
练习和解答可在 www.AtomicKotlin.com 找到。
字符串模板
字符串模板是一种以编程方式生成
String的方法。
如果在标识符名称前面放置 $,字符串模板将会将该标识符的内容插入到字符串中:
// StringTemplates/StringTemplates.kt
fun main() {
val answer = 42
println("Found $answer!") // [1]
println("printing a $1") // [2]
}
/* 输出:
Found 42!
printing a $1
*/
- [1]
$answer替换为answer的值。 - [2] 如果
$后面的内容不能被识别为程序标识符,什么特殊的事情都不会发生。
你也可以使用连接(+)将值插入到 String 中:
// StringTemplates/StringConcatenation.kt
fun main() {
val s = "hi\n" // \n 是换行字符
val n = 11
val d = 3.14
println("first: " + s + "second: " +
n + ", third: " + d)
}
/* 输出:
first: hi
second: 11, third: 3.14
*/
将表达式放在 ${} 中会对其进行求值。返回值会被转换为一个 String 并插入到结果字符串中:
// StringTemplates/ExpressionInTemplate.kt
fun main() {
val condition = true
println(
"${if (condition) 'a' else 'b'}") // [1]
val x = 11
println("$x + 4 = ${x + 4}")
}
/* 输出:
a
11 + 4 = 15
*/
- [1]
if(condition) 'a' else 'b'被求值,结果被替换整个${}表达式。
当一个 String 必须包含特殊字符(如引号)时,你可以使用 \(反斜杠)对该字符进行转义,或者使用三引号的字符串字面值:
// StringTemplates/TripleQuotes.kt
fun main() {
val s = "value"
println("s = \"$s\".")
println("""s = "$s".""")
}
/* 输出:
s = "value".
s = "value".
*/
使用三引号,你可以以与单引号 String 相同的方式插入表达式的值。
练习和解答可在 www.AtomicKotlin.com 找到。
数字类型
不同类型的数字以不同的方式存储。
如果你创建一个标识符并给它赋一个整数值,Kotlin 会推断它的类型为 Int:
// NumberTypes/InferInt.kt
fun main() {
val million = 1_000_000 // 推断为 Int
println(million)
}
/* 输出:
1000000
*/
为了提高可读性,在数字值中,Kotlin 允许在数字之间使用下划线。
基本的数学运算符与大多数编程语言中可用的一样:加法(+)、减法(-)、除法(/)、乘法(*)和模运算(%),它会产生整数除法的余数:
// NumberTypes/Modulus.kt
fun main() {
val numerator: Int = 19
val denominator: Int = 10
println(numerator % denominator)
}
/* 输出:
9
*/
整数除法会截断其结果:
// NumberTypes/IntDivisionTruncates.kt
fun main() {
val numerator: Int = 19
val denominator: Int = 10
println(numerator / denominator)
}
/* 输出:
1
*/
如果运算会对结果四舍五入,输出会是 2。
运算的优先级遵循基本算术规则:
// NumberTypes/OpOrder.kt
fun main() {
println(45 + 5 * 6)
}
/* 输出:
75
*/
乘法操作 5 * 6 首先进行,然后是加法 45 + 30。
如果你想先进行 45 + 5,可以使用括号:
// NumberTypes/OpOrderParens.kt
fun main() {
println((45 + 5) * 6)
}
/* 输出:
300
*/
现在让我们来计算 体重指数(BMI),它是以千克为单位的体重除以身高的平方。如果你的 BMI 小于 18.5,你体重过轻。在 18.5 到 24.9 之间是正常体重。BMI 为 25 及以上则是超重。此示例还展示了在函数的参数不能放在一行上时的首选格式化风格:
// NumberTypes/BMIMetric.kt
fun bmiMetric(
weight: Double,
height: Double
): String {
val bmi = weight / (height * height) // [1]
return if (bmi < 18.5) "体重过轻"
else if (bmi < 25) "正常体重"
else "超重"
}
fun main() {
val weight = 72.57 // 160 磅
val height = 1.727 // 68 英寸
val status = bmiMetric(weight, height)
println(status)
}
/* 输出:
正常体重
*/
- [1] 如果你移除了括号,你会先将
weight除以height,然后再将该结果乘以height。这会得到一个更大的数字,但是答案是错误的。
bmiMetric() 使用 Double 类型来表示体重和身高。Double 可以存储非常大和非常小的浮点数。
下面是使用英制单位的版本,使用 Int 参数表示:
// NumberTypes/BMIEnglish.kt
fun bmiEnglish(
weight: Int,
height: Int
): String {
val bmi =
weight / (height * height) * 703.07 // [1]
return if (bmi < 18.5) "体重过轻"
else if (bmi < 25) "正常体重"
else "超重"
}
fun main() {
val weight = 160
val height = 68
val status = bmiEnglish(weight, height)
println(status)
}
/* 输出:
体重过轻
*/
为什么结果与使用 Double 的 bmiMetric() 不同?当你将一个整数除以另一个整数时,Kotlin 会生成一个整数结果。在整数除法中处理余数的标准方式是 截断,也就是“截掉并抛弃”(没有四舍五入)。所以,如果你将 5 除以 2,会得到 2,7/10 会得到 0。当 Kotlin 在表达式 [1] 中计算 bmi 时,它将 160 除以 68 * 68 得到 0。然后它将 0 乘以 703.07 得到 0。
为了避免这个问题,将 703.07 移到计算的开头。这样会强制计算为 Double 类型:
val bmi = 703.07 * weight / (height * height)
在 bmiMetric() 中使用的 Double 参数可以防止这个问题。尽早将计算转换为所需类型,以保持准确性。
所有编程语言都有一个限制,不能存储超过整数范围的值。Kotlin 的 Int 类型
可以在 -231 到 +231-1 之间取值,这是 Int 32 位表示的限制。如果你对两个足够大的 Int 进行求和或乘法,你将会溢出结果:
// NumberTypes/IntegerOverflow.kt
fun main() {
val i: Int = Int.MAX_VALUE
println(i + i)
}
/* 输出:
-2
*/
Int.MAX_VALUE 是一个预定义的值,表示 Int 可以持有的最大值。
溢出会产生一个明显错误的结果,因为它既是负数,又比我们预期的要小得多。当 Kotlin 检测到潜在溢出时,会发出警告。
防止溢出是你作为开发者的责任。Kotlin 并不能在编译时总是检测到溢出,也不会阻止溢出,因为那会产生不可接受的性能影响。
如果你的程序包含大数字,你可以使用 Long,它可以容纳从 -263 到 +263-1 的值。要定义一个 Long 类型的 val,你可以显式地指定类型,或者在数字字面值末尾加上 L,告诉 Kotlin 将该值视为 Long:
// NumberTypes/LongConstants.kt
fun main() {
val i = 0 // 推断为 Int
val l1 = 0L // L 创建 Long
val l2: Long = 0 // 显式类型
println("$l1 $l2")
}
/* 输出:
0 0
*/
通过使用 Long,我们防止了 IntegerOverflow.kt 中的溢出问题:
// NumberTypes/UsingLongs.kt
fun main() {
val i = Int.MAX_VALUE
println(0L + i + i) // [1]
println(1_000_000 * 1_000_000L) // [2]
}
/* 输出:
4294967294
1000000000000
*/
在 [1] 和 [2] 中使用数值字面值会强制进行 Long 计算,也会产生 Long 类型的结果。L 出现的位置并不重要。如果其中一个值是 Long,则结果表达式也是 Long。
尽管它们可以容纳比 Int 大得多的值,但 Long 仍然有大小限制:
// NumberTypes/BiggestLong.kt
fun main() {
println(Long.MAX_VALUE)
}
/* 输出:
9223372036854775807
*/
Long.MAX_VALUE 是 Long 可以容纳的最大值。
练习和解答可在 www.AtomicKotlin.com 找到。
布尔类型
if表达式 展示了“非”操作符!,它会对布尔值进行取反。本节介绍更多的布尔代数知识。
我们从“与”和“或”操作符开始:
&&(与):仅当操作符左侧和右侧的布尔表达式都为true时,产生true。||(或):当操作符左侧或右侧的表达式为true时,或两者都为true时,产生true。
在这个例子中,我们根据 hour 判断一个商店是开还是关:
// Booleans/Open1.kt
fun isOpen1(hour: Int) {
val open = 9
val closed = 20
println("营业时间:$open - $closed")
val status =
if (hour >= open && hour <= closed) // [1]
true
else
false
println("是否开门:$status")
}
fun main() = isOpen1(6)
/* 输出:
营业时间:9 - 20
是否开门:false
*/
main() 是一个单一的函数调用,因此我们可以使用表达式体,就像 函数 中描述的那样。
在 [1] 中的 if 表达式检查 hour 是否在开门时间和关门时间之间,因此我们使用布尔 &&(与)将这些表达式组合在一起。
if 表达式可以被简化。表达式 if(cond) true else false 的结果就是 cond:
// Booleans/Open2.kt
fun isOpen2(hour: Int) {
val open = 9
val closed = 20
println("营业时间:$open - $closed")
val status = hour >= open && hour <= closed
println("是否开门:$status")
}
fun main() = isOpen2(6)
/* 输出:
营业时间:9 - 20
是否开门:false
*/
让我们反过来,检查商店当前是否关门。逻辑运算符“或” || 当至少满足一个条件时产生 true:
// Booleans/Closed.kt
fun isClosed(hour: Int) {
val open = 9
val closed = 20
println("营业时间:$open - $closed")
val status = hour < open || hour > closed
println("是否关门:$status")
}
fun main() = isClosed(6)
/* 输出:
营业时间:9 - 20
是否关门:true
*/
布尔运算符可以在简洁的表达式中实现复杂的逻辑。然而,事情很容易变得混乱。追求可读性,明确指明你的意图。
下面是一个复杂的布尔表达式的例子,不同的评估顺序会产生不同的结果:
// Booleans/EvaluationOrder.kt
fun main() {
val sunny = true
val hoursSleep = 6
val exercise = false
val temp = 55
// [1]:
val happy1 = sunny && temp > 50 ||
exercise && hoursSleep > 7
println(happy1)
// [2]:
val sameHappy1 = (sunny && temp > 50) ||
(exercise && hoursSleep > 7)
println(sameHappy1)
// [3]:
val notSame =
(sunny && temp > 50 || exercise) &&
hoursSleep > 7
println(notSame)
}
/* 输出:
true
true
false
*/
布尔表达式是 sunny、temp > 50、exercise 和 hoursSleep > 7。我们将 happy1 理解为:“天晴 并且 温度大于 50 或者 我已经锻炼并且睡了超过 7 小时。”但是 && 在 || 前还是后,哪一个运算符的优先级更高呢?
[1] 中的表达式使用了 Kotlin 的默认评估顺序。这产生了与 [2] 中的表达式相同的结果,因为没有括号,逻辑“与”先于逻辑“或”进行计算。[3] 中的表达式使用括号产生了不同的结果。在 [3] 中,只有在睡眠超过 7 小时时我们才会感到高兴。
练习和解答可在 www.AtomicKotlin.com 找到。
使用 while 循环
计算机非常适合处理重复的任务。
最基本的重复形式使用 while 关键字。这会根据控制的布尔表达式是否为 true 来重复一个代码块:
while (布尔表达式) {
// 要重复的代码
}
布尔表达式在循环开始时被评估一次,然后在每次进入代码块之前再次评估。
// RepetitionWithWhile/WhileLoop.kt
fun condition(i: Int) = i < 100 // [1]
fun main() {
var i = 0
while (condition(i)) { // [2]
print(".")
i += 10 // [3]
}
}
/* 输出:
..........
*/
- [1] 比较运算符
<产生一个布尔结果,因此 Kotlin 推断condition()的结果类型为布尔。 - [2]
while的条件表达式表示:“只要condition()返回true,就重复执行代码块中的语句。” - [3]
+=运算符将10添加到i并将结果赋值给i(i必须是var才能这样工作)。这等效于:
i = i + 10
还有一种使用 while 的方式,与 do 关键字一起使用:
do {
// 要重复的代码
} while (布尔表达式)
将 WhileLoop.kt 重写为使用 do-while 会产生:
// RepetitionWithWhile/DoWhileLoop.kt
fun main() {
var i = 0
do {
print(".")
i += 10
} while (condition(i))
}
/* 输出:
..........
*/
while 和 do-while 之间的唯一区别在于,do-while 的代码块始终至少执行一次,即使布尔表达式最初产生 false。在 while 循环中,如果条件在第一次时为 false,则代码块永远不会执行。在实践中,do-while 比 while 更少见。
所有算术操作都可以使用短版的赋值运算符:+=、-=、*=、/= 和 %=。这里使用了 -= 和 %=:
// RepetitionWithWhile/AssignmentOperators.kt
fun main() {
var n = 10
val d = 3
print(n)
while (n > d) {
n -= d
print(" - $d")
}
println(" = $n")
var m = 10
print(m)
m %= d
println(" % $d = $m")
}
/* 输出:
10 - 3 - 3 - 3 = 1
10 % 3 = 1
*/
为了计算两个自然数的整数除法的余数,我们首先使用了 while 循环,然后使用了余数运算符。
将一个数加 1 和减 1 是如此常见,以至于它们都有自己的增量和减量运算符:++ 和 --。你可以将 i += 1 替换为 i++:
// RepetitionWithWhile/IncrementOperator.kt
fun main() {
var i = 0
while (i < 4) {
print(".")
i++
}
}
/* 输出:
....
*/
实际上,while 循环不常用于遍历一系列数字。取而代之的是使用 for 循环。这将在下一个部分中介绍。
练习和解答可在 www.AtomicKotlin.com 找到。
循环与范围
for关键字用于对序列中的每个值执行一系列代码块。
值的集合可以是整数范围、String,或者在本书后面将会介绍的项目集合。in 关键字表示你正在遍历值:
for (v in values) {
// 使用 v 做一些操作
}
每次循环迭代,v 都会被赋予 values 中的下一个元素。
下面是一个 for 循环,重复一个动作固定次数:
// LoopingAndRanges/RepeatThreeTimes.kt
fun main() {
for (i in 1..3) {
println("Hey $i!")
}
}
/* 输出:
Hey 1!
Hey 2!
Hey 3!
*/
输出显示索引 i 接收了范围从 1 到 3 的每个值。
范围是由一对端点定义的值间隔。有两种基本方法来定义范围:
// LoopingAndRanges/DefiningRanges.kt
fun main() {
val range1 = 1..10 // [1]
val range2 = 0 until 10 // [2]
println(range1)
println(range2)
}
/* 输出:
1..10
0..9
*/
- [1] 使用
..语法会将两个边界都包含在结果范围内。 - [2]
until排除了结束点。输出显示10不是范围的一部分。
显示范围会生成可读性良好的格式。
下面的代码将从 10 到 100 的数字求和:
// LoopingAndRanges/SumUsingRange.kt
fun main() {
var sum = 0
for (n in 10..100) {
sum += n
}
println("sum = $sum")
}
/* 输出:
sum = 5005
*/
你可以以相反的顺序遍历范围。你还可以使用 step 值来改变默认的间隔值 1:
// LoopingAndRanges/ForWithRanges.kt
fun showRange(r: IntProgression) {
for (i in r) {
print("$i ")
}
print(" // $r")
println()
}
fun main() {
showRange(1..5)
showRange(0 until 5)
showRange(5 downTo 1) // [1]
showRange(0..9 step 2) // [2]
showRange(0 until 10 step 3) // [3]
showRange(9 downTo 2 step 3)
}
/* 输出:
1 2 3 4 5 // 1..5
0 1 2 3 4 // 0..4
5 4 3 2 1 // 5 downTo 1 step 1
0 2 4 6 8 // 0..8 step 2
0 3 6 9 // 0..9 step 3
9 6 3 // 9 downTo 3 step 3
*/
- [1]
downTo生成递减范围。 - [2]
step改变了间隔。在这里,范围的步长为 2,而不是默认的 1。 - [3]
until也可以与step一起使用。注意这如何影响输出。
在每种情况下,数字序列形成一个等差数列。showRange() 接受一个 IntProgression 参数,这是一种内置类型,包括了 Int 范围。注意,每行输出的注释中出现的 IntProgression 的 String 表示形式通常与传递给 showRange() 的范围不同 - IntProgression 将输入转化为一个等效的常见形式。
你还可以生成一个字符范围。以下 for 循环从 a 遍历到 z:
// LoopingAndRanges/ForWithCharRange.kt
fun main() {
for (c in 'a'..'z') {
print(c)
}
}
/* 输出:
abcdefghijklmnopqrstuvwxyz
*/
你可以遍历整数和字符等整数量的元素范围,但不能遍历浮点数值。
使用方括号可以通过索引访问字符。因为在 String 中我们从零开始计算字符,所以 s[0] 会选择 String s 的第一个字符。选择 s.lastIndex 会产生最后一个索引号:
// LoopingAndRanges/IndexIntoString.kt
fun main() {
val s = "abc"
for (i in 0..s.lastIndex) {
print(s[i] + 1)
}
}
/* 输出:
bcd
*/
有时候人们将 s[0] 描述为“第零个字符”。
字符存储为与其 ASCII 代码 对应的数字,因此将整数添加到字符会产生一个新的字符,其对应新的代码值:
// LoopingAndRanges/AddingIntToChar.kt
fun main() {
val ch: Char = 'a'
println(ch + 25)
println(ch < 'z')
}
/* 输出:
z
true
*/
第二个 println() 显示你可以比较字符代码。
for 循环可以直接遍历 String:
// LoopingAndRanges/IterateOverString.kt
fun main() {
for (ch in "Jnskhm ") {
print(ch + 1)
}
}
/* 输出:
Kotlin!
*/
ch 依次接收每个字符。
在下面的示例中,函数 hasChar() 遍历字符串 s 并测试它是否包含给定的字符 ch。在函数中间的 return 在答案找到时停止函数:
// LoopingAndRanges/HasChar.kt
fun hasChar(s: String, ch: Char): Boolean {
for (c in s) {
if (c == ch) return true
}
return false
}
fun main() {
println(hasChar("kotlin", 't'))
println(hasChar("kotlin", 'a'))
}
/* 输出:
true
false
*/
下一部分将展示 hasChar() 是不必要的,你可以使用内置的语法来替代。
如果你只是想要重复一个动作固定次数,可以使用 repeat() 替代 for 循环:
// LoopingAndRanges/RepeatHi.kt
fun main() {
repeat(2) {
println("hi!")
}
}
/* 输出:
hi!
hi!
*/
repeat() 是标准库函数,不是关键字。你将在本书后面看到它是如何被创建的。
练习和解答可在 www.AtomicKotlin.com 找到。
in 关键字
in关键字用于测试一个值是否在一个范围内。
// InKeyword/MembershipInRange.kt
fun main() {
val percent = 35
println(percent in 1..100)
}
/* 输出:
true
*/
在 布尔类型 中,你学会了显式检查边界:
// InKeyword/MembershipUsingBounds.kt
fun main() {
val percent = 35
println(0 <= percent && percent <= 100)
}
/* 输出:
true
*/
0 <= x && x <= 100 在逻辑上等同于 x in 0..100。IntelliJ IDEA 建议自动将第一种形式替换为第二种形式,因为第二种形式更易于阅读和理解。
in 关键字用于迭代和成员关系检查。在 for 循环的控制表达式中的 in 表示迭代,否则 in 用于成员关系检查:
// InKeyword/IterationVsMembership.kt
fun main() {
val values = 1..3
for (v in values) {
println("iteration $v")
}
val v = 2
if (v in values)
println("$v is a member of $values")
}
/* 输出:
iteration 1
iteration 2
iteration 3
2 is a member of 1..3
*/
in 关键字不限于范围。你还可以检查一个字符是否是一个 String 的一部分。以下示例使用 in 替代了前面一篇文章中的 hasChar() 函数:
// InKeyword/InString.kt
fun main() {
println('t' in "kotlin")
println('a' in "kotlin")
}
/* 输出:
true
false
*/
在本书后面,你会看到 in 也适用于其他类型。
在这里,in 测试一个字符是否属于一个字符范围:
// InKeyword/CharRange.kt
fun isDigit(ch: Char) = ch in '0'..'9'
fun notDigit(ch: Char) =
ch !in '0'..'9' // [1]
fun main() {
println(isDigit('a'))
println(isDigit('5'))
println(notDigit('z'))
}
/* 输出:
false
true
true
*/
- [1]
!in用于检查值是否不属于一个范围。
你可以创建一个 Double 范围,但只能用它来检查成员关系:
// InKeyword/FloatingPointRange.kt
fun inFloatRange(n: Double) {
val r = 1.0..10.0
println("$n in $r? ${n in r}")
}
fun main() {
inFloatRange(0.999999)
inFloatRange(5.0)
inFloatRange(10.0)
inFloatRange(10.0000001)
}
/* 输出:
0.999999 in 1.0..10.0? false
5.0 in 1.0..10.0? true
10.0 in 1.0..10.0? true
10.0000001 in 1.0..10.0? false
*/
浮点数范围只能使用 .. 创建,因为 until 意味着排除一个浮点数作为端点,这是没有意义的。
你可以检查一个 String 是否属于一组 String 的范围:
// InKeyword/StringRange.kt
fun main() {
println("ab" in "aa".."az")
println("ba" in "aa".."az")
}
/* 输出:
true
false
*/
这里 Kotlin 使用字母比较。
练习和解答可在 www.AtomicKotlin.com 找到。
表达式与语句
语句 和 表达式 是大多数编程语言中最小的有用代码片段。
两者之间有基本的区别:语句具有影响,但不产生结果。而表达式总是产生结果。
由于它不产生结果,所以语句必须改变其周围的状态才能有用。另一种表达这个观点的方式是“语句是为了其副作用而调用的”(即它除了产生结果之外的其他操作)。可以这样记忆:
语句改变状态。
“表达”的一个定义是“挤压或挤出”,就像“从橙子中挤出果汁”。因此:
表达式表达。
也就是说,它产生了一个结果。
在 Kotlin 中,for 循环是一个语句。你不能将它赋值,因为它没有结果:
// ExpressionsStatements/ForIsAStatement.kt
fun main() {
// 不能这样做:
// val f = for(i in 1..10) {}
// 编译器错误信息:
// for is not an expression, and
// only expressions are allowed here
}
for 循环用于其副作用。
表达式产生一个值,可以赋值或作为另一个表达式的一部分使用,而语句始终是顶级元素。
每个函数调用都是一个表达式。即使函数返回 Unit,并且仅用于其副作用,结果仍然可以被赋值:
// ExpressionsStatements/UnitReturnType.kt
fun unitFun() = Unit
fun main() {
println(unitFun())
val u1: Unit = println(42)
println(u1)
val u2 = println(0) // 类型推断
println(u2)
}
/* 输出:
kotlin.Unit
42
kotlin.Unit
0
kotlin.Unit
*/
Unit 类型包含一个称为 Unit 的单一值,你可以直接返回,就像在 unitFun() 中看到的那样。调用 println() 也会返回 Unit。val u1 捕获了 println() 的返回值,并明确声明为 Unit,而 u2 使用了类型推断。
if 创建一个表达式,因此可以将其结果赋值:
// ExpressionsStatements/AssigningAnIf.kt
fun main() {
val result1 = if (11 > 42) 9 else 5
val result2 = if (1 < 2) {
val a = 11
a + 42
} else 42
val result3 =
if ('x' < 'y')
println("x < y")
else
println("x > y")
println(result1)
println(result2)
println(result3)
}
/* 输出:
x < y
5
53
kotlin.Unit
*/
第一行输出是 x < y,即使 result3 直到 main() 结尾才被显示出来。这是因为评估 result3 调用了 println(),而这个评估是在定义 result3 时发生的。
注意,a 在 result2 的代码块中被定义。最后一个表达式的结果成为 if 表达式的结果;在这里,它是 11 和 42 的和。但是 a 呢?一旦离开代码块(移到花括号外部),你就无法访问 a。它是临时的,一旦退出该块的作用域,就会被丢弃。
递增操作符 i++ 也是一个表达式,尽管看起来像是一个语句。Kotlin 遵循 C 类似语言使用的方法,并提供了两个版本的递增和递减操作符,具有稍微不同的语义。前缀操作符出现在操作数之前,就像 ++i,并在递增发生后返回值。你可以将其理解为“首先执行递增,然后返回结果值”。后缀操作符放在操作数之后,就像 i++,并在递增发生前返回 i 的值。你可以将其理解为“首先产生结果,然后执行递增”。
// ExpressionsStatements/PostfixVsPrefix.kt
fun main() {
var i = 10
println(i++)
println(i)
var j = 20
println(++j)
println(j)
}
/* 输出:
10
11
21
21
*/
递减操作符也有两个版本:--i 和 i--。在其他表达式中使用递增和递减操作符是不鼓励的,因为它可能产生令人困惑的代码:
// ExpressionsStatements/Confusing.kt
fun main() {
var i = 1
println(i++ + ++i)
}
试着猜猜输出会是什么,然后进行验证。
练习和解答可在 www.AtomicKotlin.com 找到。
总结 1
本部分总结和回顾了从Hello, World!开始到Expressions & Statements结束的各个小节。
如果你是有经验的程序员,这应该是你的第一个小节。新手程序员应该阅读本小节,并完成练习,以复习第一部分的内容。
如果有任何不清楚的地方,请查阅相关主题的小节(小节标题对应了各个小节的名称)。
你好,世界!
Kotlin 支持 // 单行注释和 /*-*/ 多行注释。程序的入口点是函数 main():
// Summary1/Hello.kt
fun main() {
println("你好,世界!")
}
/* 输出:
你好,世界!
*/
本书中每个示例的第一行都是一个注释,包含了该章节的子目录名称,后跟 / 和文件名。你可以通过 AtomicKotlin.com 找到所有提取的代码示例。
println() 是一个标准库函数,它接受一个 String 参数(或可以转换为 String 的参数)。println() 在显示其参数后将光标移动到新行,而 print() 则将光标保留在同一行上。
Kotlin 不需要在表达式或语句的末尾使用分号。分号只在单行上分隔多个表达式或语句时才是必需的。
var 和 val,数据类型
要创建一个不可更改的标识符,请使用 val 关键字,后跟标识符名称、冒号和该值的类型。然后添加等号和要分配给该 val 的值:
val 标识符: 类型 = 初始化
一旦为 val 分配了值,就不能重新分配。
Kotlin 的类型推断通常可以根据初始化值自动确定类型,从而产生更简单的定义:
val 标识符 = 初始化
以下两者都是有效的:
val 二月天数 = 28
val 三月天数: Int = 31
var(变量)定义看起来与此类似,使用 var 而不是 val:
var 标识符1 = 初始化
var 标识符2: 类型 = 初始化
与 val 不同,你可以修改 var,因此以下内容是合法的:
var 花费小时数 = 20
花费小时数 = 25
然而,类型不能改变,所以如果你说:
花费小时数 = 30.5
Kotlin 在定义 花费小时数 时推断为 Int 类型,因此不会接受更改为浮点值。
函数
函数是命名的子例程:
fun 函数名(参数1: 类型1, 参数2: 类型2, ...): 返回类型 {
// 代码行...
return 结果
}
fun 关键字后跟函数名和带有参数列表的括号。每个参数必须具有显式类型,因为 Kotlin 无法推断参数类型。函数本身具有类型,与 var 或 val 一样定义(冒号后跟类型)。函数的类型是返回结果的类型。
函数签名后跟花括号内的函数体。return 语句提供函数的返回值。
当函数由单个表达式组成时,可以使用简写语法:
fun 函数名(参数1: 类型1, 参数2: 类型2, ...): 返回类型 = 结果
这种形式称为表达式体。使用等号和表达式,而不是花括号。你可以省略返回类型,因为 Kotlin 会推断它。
以下是一个生成其参数的立方值的函数以及一个向 String 添加感叹号的函数:
// Summary1/BasicFunctions.kt
fun 立方(x: Int): Int {
return x * x * x
}
fun 感叹(s: String) = s + "!"
fun main() {
println(立方(3))
println(感叹("流行"))
}
/* 输出:
27
流行!
*/
立方() 具有块体,包含了显式的 return 语句。感叹() 是表达式体,生成函数的返回值。Kotlin 推断 感叹() 的返回类型为 String。
布尔值
为了进行布尔代数运算,Kotlin 提供了诸如以下操作符:
!(非)逻辑否定值(将true转换为false,反之亦然)。&&(与)仅在两个条件都为true时返回true。||(或)如果至少有一个条件为true,则返回true。
// Summary1/Booleans.kt
fun main() {
val 开门时间 = 9
val 关门时间 = 20
println("营业时间:$开门时间 - $关门时间")
val 当前时间 = 6
println("当前时间:" + 当前时间)
val 是否营业 = 当前时间 >= 开门时间 && 当前时间 <= 关门时间
println("营业中:" + 是否营业)
println("不营业:" + !是否营业)
val 是否关门 = 当前时间 < 开门时间 || 当前时间 > 关门时间
println("关门了:" + 是否关门)
}
/* 输出:
营业时间:9 - 20
当前时间:6
营业中:false
不营业:true
关门了:true
*/
是否营业 的初始化使用 && 测试两个条件是否都为 true。第一个条件 当前时间 >= 开门时间 为 false,因此整个表达式的结果变为 false。是否关门 的初始化使用 ||,当至少有一个条件为 true 时返回 true。表达式 当前时间 < 开门时间 为 true,因此整个表达式为 true。
if 表达式
由于 if 是一个表达式,它会产生一个结果。此结果可以分配给 var 或 val。在这里,你还可以看到使用 else 关键字:
// Summary1/IfResult.kt
fun main() {
val 结果 = if (99 < 100) 4 else 42
println(结果)
}
/* 输出:
4
*/
if 表达式的任何分支都可以是由花括号括起来的多行代码块:
// Summary1/IfExpression.kt
fun main() {
val 活动 = "游泳"
val 小时 = 10
val 是否营业 = if (
活动 == "游泳" ||
活动 == "滑冰") {
val 开门时间 = 9
val 关门时间 = 20
println("营业时间:" +
开门时间 + " - " + 关门时间)
小时 >= 开门时间 && 小时 <= 关门时间
} else {
false
}
println(是否营业)
}
/* 输出:
营业时间:9 - 20
true
*/
在代码块内定义的值(例如 开门时间)在该代码块的作用域之外不可访问。因为它们在 if 表达式中被全局定义,所以 活动 和 小时 在 if 表达式内部是可访问的。
if 表达式的结果是所选分支的最后一个表达式的结果。在这里,它是 小时 >= 开门时间 && 小时 <= 关门时间,它的结果是 true。
字符串模板
你可以使用字符串模板在 String 内插入值。在标识符名称之前使用 $:
// Summary1/StrTemplates.kt
fun main() {
val 答案 = 42
println("找到 $答案!") // [1]
val 条件 = true
println(
"${if (条件) 'a' else 'b'}") // [2]
println("打印 a $1") // [3]
}
/* 输出:
找到 42!
a
打印 a $1
*/
- [1]
$答案用答案中包含的值进行替换。 - [2]
${if(条件) 'a' else 'b'}评估并用${}内部表达式的结果进行替换。 - [3] 如果
$后面跟的是不可识别为程序标识符的任何内容,则不会发生任何特殊情况。
使用三重引号的 String 存储多行文本或带有特殊字符的文本:
// Summary1/ThreeQuotes.kt
fun json(问题: String, 答案: Int) = """{
"question" : "$问题",
"answer" : $答案
}"""
fun main() {
println(json("终极问题", 42))
}
/* 输出:
{
"question" : "终极问题",
"answer" : 42
}
*/
你无需在三重引号的 String 内转义特殊字符,比如 "(在普通 String 中,你可以写 \" 来插入双引号)。与普通 String 一样,你可以在三重引号的 String 内部使用 $ 插入标识符或表达式。
数值类型
Kotlin 提供整数类型(Int、Long)和浮点数类型(Double)。默认情况下,整数常数是 Int 类型,如果你附加了 L,则为 Long 类型。如果常数包含小数点,则为 Double 类型:
// Summary1/NumberTypes.kt
fun main() {
val n = 1000 // Int
val l = 1000L // Long
val d = 1000.0 // Double
println("$n $l $d")
}
/* 输出:
1000 1000 1000.0
*/
Int 可以存储介于 -231 和 +231-1 之间的值。整数值可能会溢出;例如,将任何值加到 Int.MAX_VALUE 上会产生溢出:
// Summary1/Overflow.kt
fun main() {
println(Int.MAX_VALUE + 1)
println(Int.MAX_VALUE + 1L)
}
/* 输出:
-2147483648
2147483648
*/
在第二个 println() 语句中,我们将 1 后面附加了 L,将整个表达式的类型强制为 Long,从而避免了溢出。(Long 可以存储介于 -263 和 +263-1 之间的值)。
当你将一个 Int 除以另一个 Int 时,Kotlin 会产生一个 Int 结果,并截断任何余数。因此,1/2 会产生 0。如果涉及到 Double,则 Int 会在操作之前被提升为 Double,因此 1.0/2 会产生 0.5。
你可能期望以下代码中的 d1 产生 3.4:
// Summary1/Truncation.kt
fun main() {
val d1: Double = 3.0 + 2 / 5
println(d1)
val d2: Double = 3 + 2.0 / 5
println(d2)
}
/* 输出:
3.0
3.4
*/
由于计算顺序的原因,实际上不会这样。Kotlin 首先将 2 除以 5,整数运算得到 0,从而得到了 3.0 的结果。但是对于 d2,由于计算顺序的相同,得到了预期的结果。将 2.0 除以 5 得到 0.4。由于我们将其与 Double (0.4) 相加,3 被提升为 Double,从而产生了 3.4。
理解计算顺序有助于你解释程序的运行方式,无论是逻辑操作(布尔表达式)还是数学运算。如果你不确定计算顺序,可以使用括号来强制表达你的意图。这也使得阅读你的代码的人可以清楚地理解。
使用 while 进行循环
while 循环在控制的布尔表达式产生 true 时继续执行:
while (布尔表达式) {
// 要重复的代码
}
布尔表达式在循环开始时被评估一次,在每次迭代之前再次评估。
// Summary1/While.kt
fun testCondition(i: Int) = i < 100
fun main() {
var i = 0
while (testCondition(i)) {
print(".")
i += 10
}
}
/* 输出:
..........
*/
Kotlin 推断 testCondition() 的结果类型为 Boolean。
所有数学运算都有短版本的赋值运算符(+=、-=、*=、/=、%=)。Kotlin 还支持增量和减量运算符 ++ 和 --,无论是前缀形式还是后缀形式。
while 可以与 do 关键字一起使用:
do {
// 要重复的代码
} while (布尔表达式)
重写 While.kt:
// Summary1/DoWhile.kt
fun main() {
var i = 0
do {
print(".")
i += 10
} while (testCondition(i))
}
/* 输出:
..........
*/
while 和 do-while 之间的唯一区别是 do-while 的主体始终至少执行一次,即使布尔表达式第一次产生 false。
循环与范围
许多编程语言通过逐步遍历整数来索引可迭代对象。Kotlin 的 for 允许你直接从可迭代对象(如范围和 String)中获取元素。例如,以下 for 循环会选择字符串 "Kotlin" 中的每个字符:
// Summary1/StringIteration.kt
fun main() {
for (c in "Kotlin") {
print("$c ")
// c += 1 // 错误:
// 不能重新分配 val
}
}
/* 输出:
K o t l i n
*/
c 既不能显式定义为 var 也不能定义为 val,Kotlin 会自动将其设为 val,并推断其类型为 Char(你可以显式提供类型,但实际上很少这样做)。
你可以使用范围来遍历整数值:
// Summary1/RangeOfInt.kt
fun main() {
for (i in 1..10) {
print("$i ")
}
}
/* 输出:
1 2 3 4 5 6 7 8 9 10
*/
使用 .. 创建的范围包含两个边界,但使用 until 排除顶部端点:1 until 10 等同于 1..9。你可以使用 step 来指定增量值:1..21 step 3。
in 关键字
提供 for 循环迭代的同一个 in 也允许你检查一个值是否属于范围。如果测试值不在范围内,!in 返回 true:
// Summary1/Membership.kt
fun inNumRange(n: Int) = n in 50..100
fun notLowerCase(ch: Char) = ch !in 'a'..'z'
fun main() {
val i1 = 11
val i2 = 100
val c1 = 'K'
val c2 = 'k'
println("$i1 ${inNumRange(i1)}")
println("$i2 ${inNumRange(i2)}")
println("$c1 ${notLowerCase(c1)}")
println("$c2 ${notLowerCase(c2)}")
}
/* 输出:
11 false
100 true
K true
k false
*/
in 也可以用于测试浮点数范围中的成员资格,尽管这样的范围只能使用 .. 而不是 until 来定义。
表达式与语句
在大多数编程语言中,最小的有用代码片段要么是一个语句,要么是一个表达式。它们之间有一个基本的区别:
- 语句改变状态。
- 表达式表达。
也就是说,表达式产生结果,而语句则不会。因为语句不返回任何东西,所以语句必须改变其周围环境的状态(也就是创建一个副作用)才能做任何有用的事情。
在 Kotlin 中,几乎所有的东西都是表达式:
val hours = 10
val minutesPerHour = 60
val minutes = hours * minutesPerHour
在每种情况下,= 右侧的所有内容都是一个表达式,它产生一个结果,然后将其赋值给左侧的标识符。
像 println() 这样的函数似乎不会产生结果,但因为它们仍然是表达式,所以它们必须返回一些东西。Kotlin 为这些函数提供了特殊的 Unit 类型:
// Summary1/UnitReturn.kt
fun main() {
val result = println("返回 Unit")
println(result)
}
/* 输出:
返回 Unit
kotlin.Unit
*/
经验丰富的程序员在完成本节练习后,可以前往总结 2。
练习和解答可以在 www.AtomicKotlin.com 找到。
第二部分:对象入门
对象是许多现代编程语言的基础,包括Kotlin。
在面向对象object-oriented(OO)的编程语言中,你会在解决问题时找到“名词”,然后将这些名词转化为对象。对象保存数据并执行操作。面向对象的语言创建和使用对象。
Kotlin不仅仅是面向对象的,它还是一种函数式语言。函数式语言关注你执行的操作(“动词”)。Kotlin是一种混合的面向对象和函数式语言。
- 本节介绍面向对象编程的基础知识。
- 第四部分:函数式编程介绍了函数式编程。
- 第五部分:面向对象编程详细介绍了面向对象编程。
到处都是对象
对象使用属性(
val和var)存储数据,并使用函数执行与此数据相关的操作。
一些定义:
- 类:为基本上是新数据类型的内容定义属性和函数。类也被称为用户定义类型。
- 成员:类的属性或函数。
- 成员函数:仅适用于特定类对象的函数。
- 创建对象:创建类的
val或var。也称为该类的实例化。
因为类定义了状态和行为,我们甚至可以将内置类型(如 Double 或 Boolean)的实例称为对象。
考虑 Kotlin 的 IntRange 类:
// ObjectsEverywhere/IntRanges.kt
fun main() {
val r1 = IntRange(0, 10)
val r2 = IntRange(5, 7)
println(r1)
println(r2)
}
/* 输出:
0..10
5..7
*/
我们创建了两个 IntRange 类的对象(实例)。每个对象在内存中有自己的存储空间。IntRange 是一个类,但是从 0 到 10 的特定范围 r1 是一个与范围 r2 不同的对象。
IntRange 对象有许多操作可用。有些操作很简单,比如 sum(),而其他操作则需要更多的理解才能使用。如果尝试调用需要参数的操作,IDE 将要求提供这些参数。
要了解特定的成员函数,可以在 Kotlin 文档 中查找。注意页面右上角的放大镜图标。点击该图标,然后在搜索框中键入 IntRange。从搜索结果中点击 kotlin.ranges > IntRange。您将看到 IntRange 类的文档。您可以学习该类的所有成员函数(应用程序编程接口,API)。尽管现在大部分内容您可能不会理解,但习惯于在 Kotlin 文档中查找信息是有帮助的。
IntRange 是一种对象,而对象的一个定义特性是你可以对其执行操作。我们不再说“执行一个操作”,而是说调用一个成员函数。要为对象调用成员函数,请从对象标识符开始,然后是一个点,然后是操作的名称:
// ObjectsEverywhere/RangeSum.kt
fun main() {
val r = IntRange(0, 10)
println(r.sum())
}
/* 输出:
55
*/
因为 sum() 是为 IntRange 定义的成员函数,所以通过 r.sum() 来调用它。这会将 IntRange 中的所有数字相加。
早期的面向对象语言使用“发送消息”这个短语来描述为对象调用成员函数的操作。有时你仍然会看到这种术语。
类可以有许多操作(成员函数)。通过包含名为代码补全的功能的集成开发环境(IDE),可以轻松地探索类。例如,如果在 IntelliJ IDEA 中在对象标识符后键入 .s,它将显示以 s 开头的该对象的所有成员:
代码补全
尝试在其他对象上使用代码补全。例如,您可以反转一个 String 或将所有字符转换为小写:
// ObjectsEverywhere/Strings.kt
fun main() {
val s = "AbcD"
println(s.reversed())
println(s.toLowerCase())
}
/* 输出:
DcbA
abcd
*/
您还可以轻松将 String 转换为整数,然后再转换回去:
// ObjectsEverywhere/Conversion.kt
fun main() {
val s = "123"
println(s.toInt())
val i = 123
println(i.toString())
}
/* 输出:
123
123
*/
在本书后面,我们将讨论处理将 String 转换为不正确整数值的情况的策略。
您还可以从一种数值类型转换为另一种。为了避免混淆,数值类型之间的转换是显式的。例如,您可以通过调用 i.toLong() 将 Int i 转换为 Long,或者通过 i.toDouble() 转换为 Double:
// ObjectsEverywhere/NumberConversions.kt
fun fraction(numerator: Long, denom: Long) =
numerator.toDouble() / denom
fun main() {
val num = 1
val den = 2
val f = fraction(num.toLong(), den.toLong())
println(f)
}
/* 输出:
0.5
*/
良好定义的类对程序员来说易于理解,并产生易于阅读的代码。
练习和解答可以在 www.AtomicKotlin.com 找到。
创建类
您不仅可以使用预定义的类型如
IntRange和String,还可以创建自己的对象类型。
事实上,在面向对象编程中,创建新类型是其中的主要活动。您可以通过定义类来创建新类型的对象。
对象是解决问题的一部分。首先,将对象视为表达概念。作为第一个近似值,如果在问题中发现一个“事物”,则在解决方案中将该事物表示为对象。
假设您想要创建一个程序来管理动物园中的动物。基于它们的行为、需求、与其他动物相处的方式以及与其他动物争斗的方式,对不同类型的动物进行分类是有意义的。每种动物的特定之处都包含在该动物对象的分类中。Kotlin 使用 class 关键字来创建新类型的对象:
// CreatingClasses/Animals.kt
// 创建一些类:
class Giraffe
class Bear
class Hippo
fun main() {
// 创建一些对象:
val g1 = Giraffe()
val g2 = Giraffe()
val b = Bear()
val h = Hippo()
// 每个对象都是独特的:
println(g1)
println(g2)
println(h)
println(b)
}
/* 输出:
Giraffe@28d93b30
Giraffe@1b6d3586
Hippo@4554617c
Bear@74a14482
*/
要定义一个类,从 class 关键字开始,然后是新类的标识符。类名必须以字母(A-Z,大小写不限)开头,但可以包括数字和下划线等内容。按照惯例,我们将类名的第一个字母大写,并将所有 val 和 var 的第一个字母小写。
Animals.kt 首先定义了三个新类,然后创建了这些类的四个对象(也称为实例)。
Giraffe 是一个类,但生活在博茨瓦纳的特定五岁雄性长颈鹿是一个对象。每个对象与其他所有对象都不同,因此我们给它们命名为 g1 和 g2。
注意最后四行输出的相当神秘。@ 之前的部分是类名,@ 之后的数字是对象在计算机内存中的位置。是的,尽管其中包含一些字母,但它是一个数字,被称为“十六进制表示法”。您程序中的每个对象都有自己独特的地址。
在这里定义的类(Giraffe、Bear 和 Hippo)尽可能简单:整个类定义只有一行。更复杂的类使用大括号({ 和 })来创建包含该类特性和行为的类体。
在类内部定义的函数属于该类。在 Kotlin 中,我们称这些为类的成员函数。一些面向对象的语言(如 Java)选择将它们称为方法,这个术语来自早期的面向对象语言(如 Smalltalk)。为了强调 Kotlin 的函数性质,设计者选择舍弃了术语方法,因为一些初学者发现这种区分令人困惑。相反,整个语言中都使用术语函数。
如果不会引起歧义,我们将只说“函数”。如果必须进行区分:
- 成员函数属于类。
- 顶层函数独立存在,不属于任何类。
这里,bark() 属于 Dog 类:
// CreatingClasses/Dog.kt
class Dog {
fun bark() = "yip!"
}
fun main() {
val dog = Dog()
}
在 main() 中,我们创建了一个 Dog 对象,并将其赋值给 val dog。Kotlin 发出了一个警告,因为我们从未使用过 dog。
成员函数使用对象名调用(调用),后面跟一个 .(点号),然后是函数名和参数列表。在这里,我们调用 meow() 函数并显示结果:
// CreatingClasses/Cat.kt
class Cat {
fun meow() = "mrrrow!"
}
fun main() {
val cat = Cat()
// 为 'cat' 调用 'meow()':
val m1 = cat.meow()
println(m1)
}
/* 输出:
mrrrow!
*/
成员函数作用于类的特定实例。在调用 meow() 时,必须使用对象调用它。在调用过程中,meow() 可以访问该对象的其他成员。
在调用成员函数时,Kotlin 通过在内部传递一个引用来跟踪感兴趣的对象。这个引用在成员函数内部可以通过关键字 this 使用。
成员函数可以通过命名这些元素来特殊访问类内的其他元素。您还可以使用 this 显式地限定对这些元素的访问。在这里,exercise() 通过使用和不使用限定调用 speak():
// CreatingClasses/Hamster.kt
class Hamster {
fun speak() = "Squeak! "
fun exercise() =
this.speak() + // 使用 'this' 限定
speak() + // 不使用 'this'
"Running on wheel"
}
fun main() {
val hamster = Hamster()
println(hamster.exercise())
}
/* 输出:
Squeak! Squeak! Running on wheel
*/
在 exercise() 中,我们首先使用显式的 this 调用 speak(),然后省略了限定。
有时您会看到包含不必要显式 this 的代码。那种代码通常来自于知道另一种语言的程序员,其中 this 要么是必需的,要么是其风格的一部分。不必要地使用一个特性会让读者困惑,他们会花时间来弄清楚您为什么这么做。我们建议避免不必要地使用 this。
在类外部,您必须使用 hamster.exercise() 和 hamster.speak()。
练习和解答可以在 www.AtomicKotlin.com 找到。
属性
属性是属于类的
var或val。
定义属性可以在类内部维护状态。维护状态是创建类的主要原因,而不仅仅是编写一个或多个独立函数。
var 属性可以重新赋值,而 val 属性则不能。每个对象都有自己的属性存储:
// Properties/Cup.kt
class Cup {
var percentFull = 0
}
fun main() {
val c1 = Cup()
c1.percentFull = 50
val c2 = Cup()
c2.percentFull = 100
println(c1.percentFull)
println(c2.percentFull)
}
/* 输出:
50
100
*/
在类内部定义 var 或 val 属性的方式与在函数内部定义它们的方式非常相似。然而,var 或 val 将成为该类的一部分,您必须通过点表示法来引用它,即在对象和属性名称之间放置一个点。您可以在每次引用 percentFull 时看到点表示法的用法。
percentFull 属性表示相应的 Cup 对象的状态。c1.percentFull 和 c2.percentFull 包含不同的值,显示每个对象都有自己的存储。
成员函数可以在其对象内部引用属性,而无需使用点表示法(即限定):
// Properties/Cup2.kt
class Cup2 {
var percentFull = 0
val max = 100
fun add(increase: Int): Int {
percentFull += increase
if (percentFull > max)
percentFull = max
return percentFull
}
}
fun main() {
val cup = Cup2()
cup.add(50)
println(cup.percentFull)
cup.add(70)
println(cup.percentFull)
}
/* 输出:
50
100
*/
add() 成员函数试图将 increase 添加到 percentFull,但确保它不会超过 100%。
在类外部,您必须限定类的属性和成员函数。
您可以定义顶层属性:
// Properties/TopLevelProperty.kt
val constant = 42
var counter = 0
fun inc() {
counter++
}
定义顶层 val 是安全的,因为它不能被修改。然而,定义可变(var)的顶层属性被认为是一种反模式。随着程序变得越来越复杂,正确推理共享可变状态变得越来越困难。如果代码库中的每个人都可以访问 var counter,您无法保证它会正确地发生变化:尽管 inc() 将 counter 增加一,但程序的其他某个部分可能将 counter 减少十,导致出现难以理解的错误。最好将可变状态限制在类内部。在限制可见性中,您将看到如何使其真正隐藏。
说 var 可以更改,而 val 不能更改是一种过于简单化的说法。打个比方,将 house 视为 val,而位于 house 内部的 sofa 视为 var。您可以修改 sofa,因为它是 var。但是,您不能重新分配 house,因为它是 val:
// Properties/ChangingAVal.kt
class House {
var sofa: String = ""
}
fun main() {
val house = House()
house.sofa = "Simple sleeper sofa: $89.00"
println(house.sofa)
house.sofa = "New leather sofa: $3,099.00"
println(house.sofa)
// 不能重新分配 val 到新的 House:
// house = House()
}
/* 输出:
Simple sleeper sofa: $89.00
New leather sofa: $3,099.00
*/
尽管 house 是 val,但其对象可以修改,因为 class House 中的 sofa 是 var。将 house 定义为 val 只会防止将其重新分配给新对象。
如果将属性定义为 val,则不能重新分配它:
// Properties/AnUnchangingVar.kt
class Sofa {
val cover: String = "Loveseat cover"
}
fun main() {
var sofa = Sofa()
// 不允许:
// sofa.cover = "New cover"
// 重新分配一个 var:
sofa = Sofa()
}
尽管 sofa 是 var,但其对象无法修改,因为 class Sofa 中的 cover 是 val。然而,sofa 可以重新分配给新对象。
我们谈到了诸如 house 和 sofa 之类的标识符,好像它们是对象一样。实际上,它们是对象的引用。看待这一点的一种方式是观察两个标识符可以引用同一个对象:
// Properties/References.kt
class Kitchen {
var table: String = "Round table"
}
fun main() {
val kitchen1 = Kitchen()
val kitchen2 = kitchen1
println("kitchen1: ${kitchen1.table}")
println("kitchen2: ${kitchen2.table}")
kitchen1.table = "Square table"
println("kitchen1: ${kitchen1.table}")
println("kitchen2: ${kitchen2.table}")
}
/* 输出:
kitchen1: Round table
kitchen2: Round table
kitchen1: Square table
kitchen2: Square table
当 kitchen1 修改 table 时,kitchen2 也会看到修改。kitchen1.table 和 kitchen2.table 显示相同的输出。
请记住,var 和 val 控制的是引用,而不是对象。var 允许您将引
用重新绑定到不同的对象,而 val 则会防止您这样做。
可变性意味着对象可以更改其状态。在上述示例中,class House 和 class Kitchen 定义了可变对象,而 class Sofa 定义了不可变对象。
练习和解答可以在 www.AtomicKotlin.com 找到。
构造函数
通过向 构造函数 传递信息,您可以初始化一个新对象。
每个对象都是一个隔离的世界。程序是对象的集合,因此正确初始化每个单独的对象解决了初始化问题的大部分内容。Kotlin 包括用于确保正确对象初始化的机制。
构造函数类似于一个特殊的成员函数,用于初始化新对象。构造函数的最简单形式是单行类定义:
// Constructors/Wombat.kt
class Wombat
fun main() {
val wombat = Wombat()
}
在 main() 中,调用 Wombat() 创建了一个 Wombat 对象。如果您来自其他面向对象的语言,您可能会期望在这里使用 new 关键字,但在 Kotlin 中,new 是多余的,因此被省略了。
您可以使用参数列表向构造函数传递信息,就像调用函数一样。在这里,Alien 构造函数接受一个参数:
// Constructors/Arg.kt
class Alien(name: String) {
val greeting = "Poor $name!"
}
fun main() {
val alien = Alien("Mr. Meeseeks")
println(alien.greeting)
// alien.name // Error // [1]
}
/* 输出:
Poor Mr. Meeseeks!
*/
创建 Alien 对象需要提供参数(尝试不提供参数)。name 在构造函数内部初始化了 greeting 属性,但在构造函数外部无法访问它 - 尝试取消注释第 [1] 行。
如果您希望构造函数参数在类体外部可访问,请在参数列表中将其定义为 var 或 val:
// Constructors/VisibleArgs.kt
class MutableNameAlien(var name: String)
class FixedNameAlien(val name: String)
fun main() {
val alien1 =
MutableNameAlien("Reverse Giraffe")
val alien2 =
FixedNameAlien("Krombopolis Michael")
alien1.name = "Parasite"
// 不能这样做:
// alien2.name = "Parasite"
}
这些类定义没有显式的类体 - 类体是隐含的。
当将 name 定义为 var 或 val 时,它将成为一个属性,因此可以在构造函数外部访问。val 构造函数参数无法更改,而 var 构造函数参数是可变的。
您的类可以有多个构造函数参数:
// Constructors/MultipleArgs.kt
class AlienSpecies(
val name: String,
val eyes: Int,
val hands: Int,
val legs: Int
) {
fun describe() =
"$name with $eyes eyes, " +
"$hands hands and $legs legs"
}
fun main() {
val kevin =
AlienSpecies("Zigerion", 2, 2, 2)
val mortyJr =
AlienSpecies("Gazorpian", 2, 6, 2)
println(kevin.describe())
println(mortyJr.describe())
}
/* 输出:
Zigerion with 2 eyes, 2 hands and 2 legs
Gazorpian with 2 eyes, 6 hands and 2 legs
*/
在 复杂构造函数 中,您将看到构造函数还可以包含复杂的初始化逻辑。
如果在预期 String 的地方使用对象,则 Kotlin 会调用对象的 toString() 成员函数。如果您没有编写这个函数,您仍然会得到一个默认的 toString():
// Constructors/DisplayAlienSpecies.kt
fun main() {
val krombopulosMichael =
AlienSpecies("Gromflomite", 2, 2, 2)
println(krombopulosMichael)
}
/* 示例输出:
AlienSpecies@4d7e1886
*/
默认的 toString() 并不是很有用 - 它会产生类名和对象的物理地址(这在不同的程序执行之间会有所不同)。您可以定义自己的 toString():
// Constructors/Scientist.kt
class Scientist(val name: String) {
override fun toString(): String {
return "Scientist('$name')"
}
}
fun main() {
val zeep = Scientist("Zeep Xanflorp")
println(zeep)
}
/* 输出:
Scientist('Zeep Xanflorp')
*/
override 是一个我们新学的关键字。在这里它是必需的,因为 toString() 已经有了一个定义,即产生原始结果的定义。override 告诉 Kotlin 我们实际上确实想要用我们自己的定义替换默认的 toString()。override 的明确性可以澄清代码并防止错误。
在对象的内容以方便的形式显示的 toString() 对于查找和修复编程错误很有用。为了简化调试过程,IDE 提供了调试器,允许您观察程序执行的每个步骤,并查看您的对象的内部。
练习和解答可以在 www.AtomicKotlin.com 找到。
限制可见性
如果您将一段代码放置了几天或几周,然后再回来看,您可能会发现更好的编写方式。
这是重构的主要动机之一,重构会重写现有的代码,使其更易读、更易理解,从而更易于维护。
在这种改变和改进代码的欲望中存在一种紧张关系。消费者(客户程序员)需要代码的某些方面保持稳定。您想要进行更改,而他们希望保持不变。
这在库中尤其重要。库的使用者不希望为库的新版本重写代码。但是,库的创建者必须有自由进行修改和改进的权利,并确保客户端代码不会受到这些更改的影响。
因此,软件设计中的一个主要考虑因素是:
将可能发生更改的内容与保持不变的内容分开。
为了控制可见性,Kotlin 和其他一些语言提供了访问修饰符。库的创建者使用修饰符 public、private、protected 和 internal 来决定客户程序员可以访问什么内容和不可以访问什么内容。本部分涵盖了 public 和 private,并简要介绍了 internal。我们将在本书的后续部分解释 protected。
诸如 private 之类的访问修饰符出现在类、函数或属性的定义之前。访问修饰符仅控制对该特定定义的访问。
public 定义可以被客户程序员访问,因此对该定义的更改会直接影响客户端代码。如果您不提供修饰符,您的定义将自动为 public,因此 public 在技术上是多余的。出于清晰起见,有时您仍然会指定 public。
private 定义是隐藏的,只能从同一个类的其他成员访问。更改或甚至删除 private 定义不会直接影响客户程序员。
private 类、顶级函数和顶级属性只能在同一个文件内访问:
// Visibility/RecordAnimals.kt
private var index = 0 // [1]
private class Animal(val name: String) // [2]
private fun recordAnimal( // [3]
animal: Animal
) {
println("Animal #$index: ${animal.name}")
index++
}
fun recordAnimals() {
recordAnimal(Animal("Tiger"))
recordAnimal(Animal("Antelope"))
}
fun recordAnimalsCount() {
println("$index animals are here!")
}
您可以从 RecordAnimals.kt 的其他函数和类中访问 private 的顶级属性([1])、类([2])和函数([3])。Kotlin 阻止您从另一个文件中访问 private 的顶级元素,告诉您它在文件中是 private 的:
// Visibility/ObserveAnimals.kt
fun main() {
// 无法访问在其他文件中声明的 private 成员。
// 类是私有的:
// val rabbit = Animal("Rabbit")
// 函数是私有的:
// recordAnimal(rabbit)
// 属性是私有的:
// index++
recordAnimals()
recordAnimalsCount()
}
/* 输出:
Animal #0: Tiger
Animal #1: Antelope
2 animals are here!
*/
隐私性在类的成员中最常用:
// Visibility/Cookie.kt
class Cookie(
private var isReady: Boolean // [1]
) {
private fun crumble() = // [2]
println("crumble")
public fun bite() = // [3]
println("bite")
fun eat() { // [4]
isReady = true // [5]
crumble()
bite()
}
}
fun main() {
val x = Cookie(false)
x.bite()
// 无法访问私有成员:
// x.isReady
// x.crumble()
x.eat()
}
/* 输出:
bite
crumble
bite
*/
- [1]
private属性,在包含的类外部无法访问。 - [2]
private成员函数。 - [3]
public成员函数,可供任何人访问。 - [4] 没有访问修饰符表示为
public。 - [5] 只有相同类的成员可以访问
private成员。
private 关键字意味着除了同一类的其他成员外,没有人可以访问该成员。其他类无法访问 private 成员,因此就好像您还将该类与自己和协作者隔离开来。使用 private,您可以自由更改该成员,而不必担心它是否会影响同一包中的另一个类。作为库设计者,您通常会尽可能将事物设置为 private,仅向客户程序员公开函数和类。
对于类的任何辅助函数(helper function)来说,如果要确保不会在包的其他地方意外使用它,可以将其设置为 private,从而禁止自己在更改或删除该函数时使用它。
在类内部存在的 private 属性也是如此。除非必须公开底层实现(这比您可能认为的要少),否则将属性设置为 private。但是,仅因为类内部的引用是 private,并不意味着其他对象不能对同一对象拥有 public 引用:
// Visibility/MultipleRef.kt
class Counter(var start: Int) {
fun increment() {
start += 1
}
override fun toString() = start.toString()
}
class CounterHolder(counter: Counter) {
private val ctr = counter
override fun toString() =
"CounterHolder: " + ctr
}
fun main() {
val c = Counter(11) // [1]
val ch = CounterHolder(c) // [2]
println(ch)
c.increment() // [3]
println(ch)
val ch2 = CounterHolder(Counter(9)) // [4]
println(ch2)
}
/* 输出:
CounterHolder: 11
CounterHolder: 12
CounterHolder: 9
*/
- [1]
c现在在创建CounterHolder对象的范围内。 - [2] 将
c作为参数传递给CounterHolder构造函数,意味着新的CounterHolder现在引用与c相同的Counter对象。 - [3] 在
ch内部被假定为private的Counter仍然可以通过c进行操作。 - [4]
Counter(9)除了在CounterHolder内部没有其他引用,因此除了ch2之外,没有任何东西可以访问或修改它。
维护单个对象的多个引用称为别名,可能会产生令人惊讶的行为。
模块
与本书中的小示例不同,实际程序通常很大。将这些程序分成一个或多个模块可能会有所帮助。模块是代码库的逻辑独立部分。将项目分成模块的方式取决于构建系统(例如 Gradle 或 Maven),这超出了本书的范围。
internal 定义仅在定义它的模块内部可访问。internal 处于 private 和 public 之间 - 当 private 过于严格但不想要元素成为 public API 的一部分时,使用它是合适的。本书的示例和练习中未使用 internal。
模块是一个更高级的概念。下一节将介绍包,这可以实现更精细的结构。库通常是一个由多个包组成的单一模块,因此 internal 元素在库内部是可用的,但对该库的使用者是不可访问的。
练习和解答可以在 www.AtomicKotlin.com 找到。
包
编程中的一个基本原则是 DRY 缩写:不要重复自己。
多个相同的代码片段在进行修复或改进时需要进行维护。因此,复制代码不仅是额外的工作,而且每次复制都会引发出错的机会。
import 关键字从其他文件中重用代码。使用 import 的一种方法是指定类、函数或属性的名称:
import packagename.ClassName
import packagename.functionName
import packagename.propertyName
包是一组相关联的代码。每个包通常被设计用于解决特定问题,通常包含多个函数和类。例如,我们可以从 kotlin.math 库中导入数学常数和函数:
// Packages/ImportClass.kt
import kotlin.math.PI
import kotlin.math.cos // 余弦函数
fun main() {
println(PI)
println(cos(PI))
println(cos(2 * PI))
}
/* 输出:
3.141592653589793
-1.0
1.0
*/
有时您想要使用多个具有相同名称的第三方库,这些库包含相同名称的类或函数。as 关键字允许您在导入时更改名称:
// Packages/ImportNameChange.kt
import kotlin.math.PI as circleRatio
import kotlin.math.cos as cosine
fun main() {
println(circleRatio)
println(cosine(circleRatio))
println(cosine(2 * circleRatio))
}
/* 输出:
3.141592653589793
-1.0
1.0
*/
如果库的名称选择不当或过长,as 是很有用的。
您可以在代码的主体中完全限定一个导入。在下面的示例中,由于使用了显式的包名,代码可能变得不太可读,但是每个元素的来源绝对清晰:
// Packages/FullyQualify.kt
fun main() {
println(kotlin.math.PI)
println(kotlin.math.cos(kotlin.math.PI))
println(kotlin.math.cos(2 * kotlin.math.PI))
}
/* 输出:
3.141592653589793
-1.0
1.0
*/
要从一个包中导入所有内容,可以使用星号:
// Packages/ImportEverything.kt
import kotlin.math.*
fun main() {
println(E)
println(E.roundToInt())
println(E.toInt())
}
/* 输出:
2.718281828459045
3
2
*/
kotlin.math 包中包含一个方便的 roundToInt() 函数,它会将 Double 值四舍五入到最近的整数,与 toInt() 不同,后者仅截断小数点后的部分。
为了重用代码,您可以使用 package 关键字创建一个包。package 语句必须是文件中的第一个非注释语句。package 后面是您的包的名称,按惯例全部小写:
// Packages/PythagoreanTheorem.kt
package pythagorean
import kotlin.math.sqrt
class RightTriangle(
val a: Double,
val b: Double
) {
fun hypotenuse() = sqrt(a * a + b * b)
fun area() = a * b / 2
}
您可以随意为源代码文件命名,不像 Java 需要文件名与类名相同。
Kotlin 允许您为包选择任何名称,但是认为包名与包含包文件的目录名称相同是一个很好的做法(这对本书中的示例并不总是适用)。
现在,通过使用 import,pythagorean 包中的元素可以使用了:
// Packages/ImportPythagorean.kt
import pythagorean.RightTriangle
fun main() {
val rt = RightTriangle(3.0, 4.0)
println(rt.hypotenuse())
println(rt.area())
}
/* 输出:
5.0
6.0
*/
在本书的其余部分,对于任何在 main() 之外定义的函数、类等,我们都会使用 package 语句,以防止与书中的其他文件发生命名冲突,但通常我们不会在仅包含 main() 的文件中使用 package 语句。
练习和解答可以在 www.AtomicKotlin.com 找到。
测试
持续测试对于快速程序开发至关重要。
如果更改代码的某一部分会导致其他代码出现问题,您的测试会立即显示问题。如果您无法立即找出问题,更改会累积起来,您将无法确定哪个更改引起了问题。您将花费更多的时间来追踪问题。
测试是一项至关重要的实践,因此我们在早期引入它,并在本书的其余部分中使用它。通过这种方式,您将习惯将测试作为编程过程的标准部分。
使用 println() 来验证代码正确性是一种薄弱的方法——您必须每次都仔细检查输出,并有意识地确保它是正确的。
为了简化在使用本书时的体验,我们创建了自己的小型测试系统。目标是采用最小的方法:
- 显示表达式的预期结果。
- 提供输出,以便在所有测试成功时,您仍然知道程序正在运行。
- 在您的实践中早早地形成测试的概念。
虽然对于本书非常有用,但我们的测试系统并不是工作场所的测试系统。他人花费了很长时间和精力来创建这些测试系统。例如:
- JUnit 是最受欢迎的 Java 测试框架之一,可以轻松地从 Kotlin 中使用。
- Kotest 是专为 Kotlin 设计的,并利用了 Kotlin 的语言特性。
- Spek 框架 提供了一种不同形式的测试,称为规范测试。
要使用我们的测试框架,首先必须进行import。框架的基本元素是 eq(等于)和 neq(不等于):
// Testing/TestingExample.kt
import atomictest.*
fun main() {
val v1 = 11
val v2 = "Ontology"
// 'eq' 表示 "等于":
v1 eq 11
v2 eq "Ontology"
// 'neq' 表示 "不等于"
v2 neq "Epistimology"
// [Error] Epistimology != Ontology
// v2 eq "Epistimology"
}
/* 输出:
11
Ontology
Ontology
*/
atomictest 包的代码位于 附录 A: AtomicTest。我们并不打算让您现在理解 AtomicTest.kt 中的所有内容,因为它使用了一些在本书后面才会出现的功能。
为了产生整洁、舒适的外观,AtomicTest 使用了 Kotlin 的一个特性,您尚未见过:即在文本样式中以 a function b 的形式写一个函数调用 a.function(b)。这被称为中缀表示法。只有使用 infix 关键字定义的函数才能以这种方式被调用。AtomicTest.kt 定义了 TestingExample.kt 中使用的 infix eq 和 neq:
expression eq expected
expression neq expected
eq 和 neq 是为 AtomicTest 定义的基本(中缀)函数——它真的是一个最小化的测试系统。当您在示例中放置 eq 和 neq 表达式时,您将同时创建一个测试和一些控制台输出。通过运行程序,您可以验证程序的正确性。
AtomicTest 中还有第二个工具。trace 对象用于捕获输出,以供稍后进行比较:
// Testing/Trace1.kt
import atomictest.*
fun main() {
trace("line 1")
trace(47)
trace("line 2")
trace eq """
line 1
47
line 2
"""
}
将结果添加到 trace 类似于一个函数调用,因此您可以将 println() 效果地替换为 trace()。
在之前的内容中,我们显示了输出并依赖于人类视觉检查以捕获任何差异。这是不可靠的;即使在我们一遍又一遍地检查代码的书中,我们也发现视觉检查无法被信任地发现错误。从现在开始,我们很少使用带有注释的输出块,因为 AtomicTest 将为我们执行所有操作。然而,有时当这会产生更有用的效果时,我们仍然会包含带有注释的输出块。
通过在本书的其余部分看到在测试中使用测试的好处,您应该能够将测试融入到您的编程过程中。当您看到没有测试的代码时,您可能会开始感到不安。您甚至可能会认为没有测试的代码在本质上是错误的。
测试作为编程的一部分
测试在将其内置到软件开发过程中时效果最佳。编写测试确保您获得预期的结果。许多人主张在编写实现代码之前编写测试——在编写代码使其通过之前,您首先使测试失败。这种称为测试驱动开发(Test Driven Development,TDD)的技术是一种确保您真正测试您认为要测试的内容的方法。您可以在维基百科上找到更完整的 TDD 描述(搜索“Test Driven Development”)。
编写可测试的代码还有另一个好处——它改变了您编写代码的方式。您可以仅仅在控制台上显示结果。但是在测试思维中,您会想知道,“我将如何测试这个?”当您创建一个函数时,您会决定应该从函数中返回一些东西,即使只是为了测试该结果。只处理输入并生成输出的函数往往会生成更好的设计。
以下是使用 TDD 来实现 Number Types 中的 BMI 计算的一个简化示例。首先,我们编写测试,以及一个最初的实现,该实现失败(因为我们尚未实现功能):
// Testing/TDDFail.kt
package testing1
import atomictest.eq
fun main() {
calculateBMI(160, 68) eq "Normal weight"
// calculateBMI(100, 68) eq "Underweight"
// calculateBMI(200, 68) eq "Overweight"
}
fun calculateBMI(lbs: Int, height: Int) =
"Normal weight"
只有第一个测试通过。其他测试失败并被注释掉了。接下来,我们添加了代码来确定哪些体重属于哪些分类。现在所有的测试都失败了:
// Testing/TDDStillFails.kt
package testing2
import atomictest.eq
fun main() {
// 一切都失败了:
// calculateBMI(160, 68) eq "Normal weight"
// calculateBMI(100, 68) eq "Underweight"
// calculateBMI(200, 68) eq "Overweight"
}
fun calculateBMI(
lbs: Int,
height: Int
): String {
val bmi = lbs / (height * height) * 703.07
return if (bmi < 18.5) "Underweight"
else if (bmi < 25) "Normal weight"
else "Overweight"
}
我们使用 Int 而不是 Double,导致结果为零。测试指导我们进行修复:
// Testing/TDDWorks.kt
package testing3
import atomictest.eq
fun main() {
calculateBMI(160.0, 68.0) eq "Normal weight"
calculateBMI(100.0, 68.0) eq "Underweight"
calculateBMI(200.0, 68.0) eq "Overweight"
}
fun calculateBMI(
lbs: Double,
height: Double
): String {
val bmi = lbs / (height * height) * 703.07
return if (bmi < 18.5) "Underweight"
else if (bmi < 25) "Normal weight"
else "Overweight"
}
您可以选择为边界条件添加其他测试。
在本书的练习中,我们包含了您的代码必须通过的测试。
练习和解答可以在 www.AtomicKotlin.com 找到。
异常
词语“异常”在这里的意义与短语“I take exception to that.”相同。
异常条件会阻止当前函数或作用域的继续执行。在问题发生的地方,您可能不知道该如何处理,但在当前上下文中无法继续执行。您没有足够的信息来修复问题。因此,您必须停止并将问题交给另一个能够采取适当行动的上下文。
本节介绍了异常作为错误报告机制的基础知识。在第 VI 部分:防止失败中,我们将介绍其他处理问题的方法。
很重要的一点是要区分异常条件和正常问题。正常问题在当前上下文中有足够的信息来应对问题。对于异常条件,您无法继续处理。您只能离开,将问题委托给外部上下文。这就是当您抛出异常时发生的情况。异常是从错误发生点“抛出”的对象。
考虑一下 toInt(),它将一个 String 转换为 Int。如果您对一个不包含整数值的 String 调用此函数会发生什么?
// Exceptions/ToIntException.kt
package exceptions
fun erroneousCode() {
// Uncomment this line to get an exception:
// val i = "1$".toInt() // [1]
}
fun main() {
erroneousCode()
}
取消对 [1] 行的注释会产生一个异常。在这里,失败的行被注释掉,以免停止本书的构建,该构建检查每个示例是否按预期编译和运行。
当抛出异常时,执行路径(无法继续执行的路径)会停止,并且异常对象会从当前上下文中弹出。在这里,它退出了 erroneousCode() 的上下文,然后进入了 main() 的上下文。在这种情况下,Kotlin 仅报告错误;程序员可能犯了一个错误,必须修复代码。
当异常未被捕获时,程序会中止,并显示包含详细信息的堆栈跟踪。在 ToIntException.kt 中取消注释 [1] 行,会产生以下输出:
Exception in thread "main" java.lang.NumberFormatException: For input s\
tring: "1$"
at java.lang.NumberFormatException.forInputString(NumberFormatExcepti\
on.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at ToIntExceptionKt.erroneousCode(at ToIntException.kt:6)
at ToIntExceptionKt.main(at ToIntException.kt:10)
堆栈跟踪提供了详细信息,比如异常发生的文件和行,这样您就可以快速发现问题所在。最后两行显示了问题:在 main() 的第 10 行我们调用了 erroneousCode()。然后,更准确地说,在 erroneousCode() 的第 6 行我们调用了 toInt()。
为了避免注释和取消注释代码以显示异常,我们使用了 AtomicTest 包中的 capture() 函数:
// Exceptions/IntroducingCapture.kt
import atomictest.*
fun main() {
capture {
"1$".toInt()
} eq "NumberFormatException: " +
"""For input string: "1$""""
}
使用 capture(),我们将生成的异常与预期的错误消息进行比较。capture() 对于正常编程不是很有用——它专门为本书设计,以便您可以看到异常,并知道输出已经经过了本书的构建系统的检查。
当无法成功生成预期的结果时,另一种策略是返回 null,它是一个表示“无值”的特殊常量。您可以返回 null 代替任何类型的值。稍后在可空类型中,我们将讨论 null 如何影响结果表达式的类型。
Kotlin 标准库中包含 String.toIntOrNull(),它会在 String 包含整数时执行转换,或者在无法转换时生成 null——null 是一种简单的指示失败的方式:
// Exceptions/IntroducingNull.kt
import atomictest.eq
fun main() {
"1$".toIntOrNull() eq null
}
假设我们要计算一段时间内的平均收入:
// Exceptions/AverageIncome.kt
package firstversion
import atomictest.*
fun averageIncome(income: Int, months: Int) =
income / months
fun main() {
averageIncome(3300, 3) eq 1100
capture {
averageIncome(5000, 0)
} eq "ArithmeticException: / by zero"
}
如果 months 为零,则 averageIncome() 中的除法会抛出一个 ArithmeticException。不幸的是,这不告诉我们有关为什么发生错误的任何信息,分母表示什么以及它是否可以合法地为零。这显然是代码中的错误——averageIncome() 应该以一种可以防止除以零错误的方式处理 months 为 0。
让我们修改 averageIncome() 以提供有关问题来源的更多信息。如果 months 为零,则无法返回常规整数值作为结果。一种策略是返回 null:
// Exceptions/AverageIncomeWithNull.kt
package withnull
import atomictest.eq
fun averageIncome(income: Int, months: Int) =
if (months == 0)
null
else
income / months
fun main() {
averageIncome(3300, 3) eq 1100
averageIncome(5000, 0) eq null
}
如果一个函数可以返回 null,Kotlin 要求您在使用结果之前检查它(这在可空类型中有涉及)。即使您只想向用户显示输出,也最好说“尚未经过完整月份”,而不是“您在该期间的平均收入为:null”。
而不是使用错误参数执行 averageIncome(),您可以抛出异常——跳出并强制程序的其他部分来处理问题。您可以允许默认的 ArithmeticException,但通常更有用的是抛出一个带有详细错误消息的特定异常。当您的应用程序在生产中运行了几年后,由于一个新功能调用 averageIncome() 而没有正确检查参数,应用程序突然抛出异常,您会对该消息感激不已:
// Exceptions/AverageIncomeWithException.kt
package properexception
import atomictest.*
fun averageIncome(income: Int, months: Int) =
if (months == 0)
throw IllegalArgumentException( // [1]
"Months can't be zero")
else
income / months
fun main() {
averageIncome(3300, 3) eq 1100
capture {
averageIncome(5000, 0)
} eq "IllegalArgumentException: " +
"Months can't be zero"
}
- [1] 在抛出异常时,
throw关键字后跟要抛出的异常,以及它可能需要的任何参数。在这里,我们使用了标准的异常类IllegalArgumentException。
您的目标是生成尽可能有用的消息,以简化将来对您的应用程序的支持。稍后您将学会定义自己的异常类型,并使其特定于您的情况。
练习和解答可以在 www.AtomicKotlin.com 找到。
列表
List是一个容器,即一个可以容纳其他对象的对象。
容器也称为集合。在本书的示例中,当我们需要一个基本的容器时,通常会使用 List。
List 是 Kotlin 标准库的一部分,因此不需要进行 import。
以下示例通过调用标准库函数 listOf() 并提供初始化值,创建了一个包含 Int 的 List:
// Lists/Lists.kt
import atomictest.eq
fun main() {
val ints = listOf(99, 3, 5, 7, 11, 13)
ints eq "[99, 3, 5, 7, 11, 13]" // [1]
// 遍历 List 中的每个元素:
var result = ""
for (i in ints) { // [2]
result += "$i "
}
result eq "99 3 5 7 11 13"
// 对 List 进行 "索引":
ints[4] eq 11 // [3]
}
- [1]
List在显示自己时使用方括号。 - [2]
for循环与List配合使用很好:for(i in ints)表示i会依次接收ints中的每个值。您无需声明val i或为其指定类型;Kotlin 从上下文中知道i是for循环的标识符。 - [3] 方括号 索引 到
List中。List保持其元素的初始化顺序,并且您可以通过数字逐个选择它们。与大多数编程语言一样,Kotlin 从元素零开始索引,本例中产生值99。因此,索引为4产生值11。
忘记索引从零开始会产生所谓的差一错误。在像 Kotlin 这样的语言中,我们通常不会逐个选择元素,而是通过 in 迭代整个容器。这消除了差一错误。
如果在 List 中使用超出最后一个元素的索引,Kotlin 会抛出 ArrayIndexOutOfBoundsException:
// Lists/OutOfBounds.kt
import atomictest.*
fun main() {
val ints = listOf(1, 2, 3)
capture {
ints[3]
} contains
listOf("ArrayIndexOutOfBoundsException")
}
List 可以容纳所有不同类型的元素。这里有一个 Double 的 List 和一个 String 的 List:
// Lists/ListUsefulFunction.kt
import atomictest.eq
fun main() {
val doubles =
listOf(1.1, 2.2, 3.3, 4.4)
doubles.sum() eq 11.0
val strings = listOf("Twas", "Brillig",
"And", "Slithy", "Toves")
strings eq listOf("Twas", "Brillig",
"And", "Slithy", "Toves")
strings.sorted() eq listOf("And",
"Brillig", "Slithy", "Toves", "Twas")
strings.reversed() eq listOf("Toves",
"Slithy", "And", "Brillig", "Twas")
strings.first() eq "Twas"
strings.takeLast(2) eq
listOf("Slithy", "Toves")
}
这显示了 List 的一些操作。注意名称“sorted”而不是“sort”。当您调用 sorted() 时,它会生成一个包含相同元素的新 List,按排序顺序排列,但不会改变原始 List。将其命名为“sort”意味着直接更改原始 List(也称为原地排序)。在 Kotlin 中的整个过程中,您会看到“保留原始对象并生成新对象”的倾向。reversed() 也会生成一个新的 List。
参数化类型
我们认为使用类型推断是一种良好的实践——它倾向于使代码更清晰,更易于阅读。但是,有时 Kotlin 抱怨无法确定要使用的类型,在其他情况下,明确性会使代码更易于理解。以下是我们如何告诉 Kotlin List 中包含的类型:
// Lists/ParameterizedTypes.kt
import atomictest.eq
fun main() {
// 类型被推断:
val numbers = listOf(1, 2, 3)
val strings =
listOf("one", "two", "three")
// 完全相同,但是显式指定类型:
val numbers2: List<Int> = listOf(1, 2, 3)
val strings2: List<String> =
listOf("one", "two", "three")
numbers eq numbers2
strings eq strings2
}
Kotlin 使用初始化值推断 numbers 包含 Int 的 List,而 strings 包含 String 的 List。
numbers2 和 strings2 是 numbers 和 strings 的显式类型版本,通过添加类型声明 List<Int> 和 List<String> 创建。您之前还没有看到过尖括号——它们表示类型参数,允许您说,“这个容器包含‘参数’对象”。我们将 List<Int> 读作Int 类型的 List”。
类型参数不仅对于容器很有用,对于其他组件也很有用,但是您经常在类似容器的对象中看到它们。
返回值也可以具有类型参数:
// Lists/ParameterizedReturn.kt
package lists
import atomictest.eq
// 返回类型被推断:
fun inferred(p: Char, q: Char) =
listOf(p, q)
// 显式返回类型:
fun explicit(p: Char, q: Char): List<Char> =
listOf(p, q)
fun main() {
inferred('a', 'b')
eq "[a, b]"
explicit('y', 'z') eq "[y, z]"
}
Kotlin 为 inferred() 推断返回类型,而 explicit() 指定函数返回类型。您不能只说它返回一个 List;Kotlin 会抱怨,因此您必须同时提供类型参数。在指定函数的返回类型时,Kotlin 强制执行您的意图。
只读和可变列表
如果您不明确表示要可变的 List,则不会得到一个。listOf() 生成一个不具有变异函数的只读 List。
如果您正在逐步创建 List(即在创建时不具有所有元素),请使用 mutableListOf()。这会生成一个可以修改的 MutableList:
// Lists/MutableList.kt
import atomictest.eq
fun main() {
val list = mutableListOf<Int>()
list.add(1)
list.addAll(listOf(2, 3))
list += 4
list += listOf(5, 6)
list eq listOf(1, 2, 3, 4, 5, 6)
}
您可以使用 add() 和 addAll() 将元素添加到 MutableList,或使用快捷方式 +=,它会添加单个元素或另一个集合。由于 list 没有初始元素,因此我们必须通过在调用 mutableListOf() 中提供 <Int> 规范来告诉 Kotlin 它的类型。
MutableList 可以被视为 List,在这种情况下它无法被修改。但是,您不能将只读 List 视为 MutableList:
// Lists/MutListIsList.kt
package lists
import atomictest.eq
fun getList(): List<Int> {
return mutableListOf(1, 2, 3)
}
fun main() {
// getList() 生成一个只读 List:
val list = getList()
// list += 3 // Error
list eq listOf(1, 2, 3)
}
请注意,尽管 list 是在 getList() 内部使用 mutableListOf() 创建的可变对象的不可变引用(val),但在 return 期间,结果类型变为 List<Int>。原始对象仍然是 MutableList,但是它通过 List 的视角来查看。
List 是只读的 — 您可以读取其内容但不能写入。如果底层实现是一个 MutableList 并且您保留了对该实现的可变引用,您仍然可以通过该可变引用修改它,并且任何只读引用都将看到这些更改。这是别名的另一个示例,介绍在限制可见性中:
// Lists/MultipleListRefs.kt
import atomictest.eq
fun main() {
val first = mutableListOf(1)
val second: List<Int> = first
second eq listOf(1)
first += 2
// second 观察到了变化:
second eq listOf(1, 2)
}
first 是对 mutableListOf(1) 生成的可变对象的一个不可变引用(val)。然后将 second 别名设置为 first,因此它是对同一对象的视图。second 是只读的,因为 List<Int> 不包括修改函数。注意,如果没有显式的 List<Int> 类型声明,Kotlin 将推断 second 也是对可变对象的引用。
我们能够将元素(2)添加到对象中,因为 first 是对可变 List 的引用。请注意,second 观察到了这些更改 —— 它不能更改 List,尽管 List 通过 first 发生了更改。
练习和解答可以在 www.AtomicKotlin.com 找到。
可变参数列表
vararg关键字生成一个具有灵活大小的参数列表。
在 列表 中,我们介绍了 listOf(),它接受任意数量的参数并生成一个 List:
// Varargs/ListOf.kt
import atomictest.eq
fun main() {
listOf(1) eq "[1]"
listOf("a", "b") eq "[a, b]"
}
使用 vararg 关键字,您可以定义一个函数,该函数接受任意数量的参数,就像 listOf() 一样。vararg 是 variable argument list(可变参数列表)的缩写:
// Varargs/VariableArgList.kt
package varargs
fun v(s: String, vararg d: Double) {}
fun main() {
v("abc", 1.0, 2.0)
v("def", 1.0, 2.0, 3.0, 4.0)
v("ghi", 1.0, 2.0, 3.0, 4.0, 5.0, 6.0)
}
函数定义可以只指定一个参数为 vararg。虽然在参数列表中的任何项目都可以指定为 vararg,但通常最简单的做法是对最后一个参数进行这样的操作。
vararg 允许您传递任意数量(包括零个)的参数。所有参数都必须是指定类型的。使用参数名称访问 vararg 参数,参数名称将成为一个 Array:
// Varargs/VarargSum.kt
package varargs
import atomictest.eq
fun sum(vararg numbers: Int): Int {
var total = 0
for (n in numbers) {
total += n
}
return total
}
fun main() {
sum(13, 27, 44) eq 84
sum(1, 3, 5, 7, 9, 11) eq 36
sum() eq 0
}
尽管 Array 和 List 看起来相似,但它们的实现方式不同 —— List 是一个常规库类,而 Array 具有特殊的低级支持。Array 来自 Kotlin 与其他语言(尤其是 Java)兼容的要求。
在日常编程中,当您需要一个简单的序列时,请使用 List。仅在第三方 API 需要一个 Array 或者当您处理 vararg 时才使用 Array。
在大多数情况下,您可以忽略 vararg 生成 Array 的事实,并将其视为 List:
// Varargs/VarargLikeList.kt
package varargs
import atomictest.eq
fun evaluate(vararg ints: Int) =
"Size: ${ints.size}\n" +
"Sum: ${ints.sum()}\n" +
"Average: ${ints.average()}"
fun main() {
evaluate(10, -3, 8, 1, 9) eq """
Size: 5
Sum: 25
Average: 5.0
"""
}
您可以在接受 vararg 的地方传递元素的 Array。要创建 Array,请使用与使用 listOf() 相同的方式使用 arrayOf()。注意,Array 总是可变的。要将 Array 转换为参数序列(不仅仅是类型为 Array 的单个元素),请使用 spread operator(扩展操作符),*:
// Varargs/SpreadOperator.kt
import varargs.sum
import atomictest.eq
fun main() {
val array = intArrayOf(4, 5)
sum(1, 2, 3, *array, 6) eq 21 // [1]
// 不编译:
// sum(1, 2, 3, array, 6)
val list = listOf(9, 10, 11)
sum(*list.toIntArray()) eq 30 // [2]
}
如果您传递一个原始类型(如 Int、Double 或 Boolean)的 Array,则 Array 创建函数必须具有特定的类型。如果在 [1] 行使用 arrayOf(4, 5) 而不是 intArrayOf(4, 5),将会产生一个错误,提示 inferred type is Array<Int> but IntArray was expected。
扩展操作符仅适用于数组。如果您有一个要作为参数序列传递的 List,请首先将其转换为 Array,然后应用扩展操作符,如 [2]。由于结果是原始类型的 Array,我们必须再次使用特定的转换函数 toIntArray()。
当您必须将 vararg 参数传递给另一个函数,而该函数也期望 vararg 参数时,扩展操作符尤其有用:
// Varargs/TwoFunctionsWithVarargs.kt
package varargs
import atomictest.eq
fun first(vararg numbers: Int): String {
var result = ""
for (i in numbers) {
result += "[$i]"
}
return result
}
fun second(vararg numbers: Int) =
first(*numbers)
fun main() {
second(7, 9, 32) eq "[7][9][32]"
}
命令行参数
在命令行上调用程序时,您可以向其传递可变数量的参数。要捕获命令行参数,必须为 main() 提供一个特定的参数:
// Varargs/MainArgs.kt
fun main(args: Array<String>) {
for (a in args) {
println(a)
}
}
参数传统上称为 args(尽管您可以称其为任何名称),而 args 的类型只能是 Array<String>(String 的数组)。
如果您使用 IntelliJ IDEA,您可以通过编辑相应的“运行配置”来传递程序参数,就像本课程的最后一个练习中所示。
您还可以使用 kotlinc 编译器来生成命令行程序。如果您的计算机上没有安装 kotlinc,请按照 Kotlin 官方网站 上的说明操作。一旦您输入并保存了 MainArgs.kt 的代码,可以在命令提示符中键入以下内容:
kotlinc MainArgs.kt
在程序调用后,您可以提供命令行参数,如下所示:
kotlin MainArgsKt hamster 42 3.14159
您将看到以下输出:
hamster
42
3.14159
如果您希望将 String 参数转换为特定类型,Kotlin 提供了转换函数,例如用于转换为 Int 的 toInt(),以及用于转换为 Float 的 toFloat()。使用这些函数时,假定命令行参数按照特定顺序出现。在这里,程序期望一个 String,后跟可转换为 Int 的内容,后跟可转换为 Float 的内容:
// Varargs/MainArgConversion.kt
fun main(args: Array<String>) {
if (args.size < 3) return
val first = args[0]
val second = args[1].toInt()
val third = args[2].toFloat()
println("$first $second $third")
}
main() 中的第一行在没有足够的参数时退出程序。如果您未提供可转换为 Int 和 Float 的内容作为第二个和第三个命令行参数,您将看到运行时错误(可以尝试以查看错误)。
使用与之前相同的命令行参数编译并运行 MainArgConversion.kt,您将看到:
hamster 42 3.14159
练习和解答可以在 www.AtomicKotlin.com 找到。
集合(Sets)
Set是一种集合,只允许每个值的一个元素。
最常见的 Set 操作是使用 in 或 contains() 进行成员检测:
// Sets/Sets.kt
import atomictest.eq
fun main() {
val intSet = setOf(1, 1, 2, 3, 9, 9, 4)
// 没有重复的元素:
intSet eq setOf(1, 2, 3, 4, 9)
// 元素的顺序无关紧要:
setOf(1, 2) eq setOf(2, 1)
// 集合的成员检测:
(9 in intSet) eq true
(99 in intSet) eq false
intSet.contains(9) eq true
intSet.contains(99) eq false
// 这个集合是否包含另一个集合?
intSet.containsAll(setOf(1, 9, 2)) eq true
// 集合的并集:
intSet.union(setOf(3, 4, 5, 6)) eq
setOf(1, 2, 3, 4, 5, 6, 9)
// 集合的交集:
intSet intersect setOf(0, 1, 2, 7, 8) eq
setOf(1, 2)
// 集合的差集:
intSet subtract setOf(0, 1, 9, 10) eq
setOf(2, 3, 4)
intSet - setOf(0, 1, 9, 10) eq
setOf(2, 3, 4)
}
这个例子展示了:
- 将重复的元素放入
Set会自动删除这些重复元素。 - 对于集合来说,元素的顺序并不重要。如果两个集合包含相同的元素,那么它们是相等的。
in和contains()都用于成员检测。- 您可以执行通常的维恩图操作,如检查子集、并集、交集和差集,使用点表示法(
set.union(other))或中缀表示法(set intersect other)。union、intersect和subtract函数可以与中缀表示法一起使用。 - 集合的差集可以使用
subtract()或减法运算符来表示。
要从 List 中删除重复元素,请将其转换为 Set:
// Sets/RemoveDuplicates.kt
import atomictest.eq
fun main() {
val list = listOf(3, 3, 2, 1, 2)
list.toSet() eq setOf(1, 2, 3)
list.distinct() eq listOf(3, 2, 1)
"abbcc".toSet() eq setOf('a', 'b', 'c')
}
您还可以使用 distinct(),它返回一个 List。您可以在 String 上调用 toSet(),将其转换为包含唯一字符的集合。
与 List 一样,Kotlin 为 Set 提供了两个创建函数。setOf() 的结果是只读的。要创建一个可变的 Set,请使用 mutableSetOf():
// Sets/MutableSet.kt
import atomictest.eq
fun main() {
val mutableSet = mutableSetOf<Int>()
mutableSet += 42
mutableSet += 42
mutableSet eq setOf(42)
mutableSet -= 42
mutableSet eq setOf<Int>()
}
运算符 += 和 -= 可以向 Set 中添加和移除元素,与处理 List 一样。
练习和答案可以在 www.AtomicKotlin.com 找到。
映射(Maps)
Map将 键 关联到 值,并在给定键时查找值。
您可以通过向 mapOf() 提供键值对来创建 Map。使用 to,我们将每个键与其关联的值分开:
// Maps/Maps.kt
import atomictest.eq
fun main() {
val constants = mapOf(
"Pi" to 3.141,
"e" to 2.718,
"phi" to 1.618
)
constants eq
"{Pi=3.141, e=2.718, phi=1.618}"
// 从键查找值:
constants["e"] eq 2.718 // [1]
constants.keys eq setOf("Pi", "e", "phi")
constants.values eq "[3.141, 2.718, 1.618]"
var s = ""
// 遍历键值对:
for (entry in constants) { // [2]
s += "${entry.key}=${entry.value}, "
}
s eq "Pi=3.141, e=2.718, phi=1.618,"
s = ""
// 在迭代期间解包:
for ((key, value) in constants) // [3]
s += "$key=$value, "
s eq "Pi=3.141, e=2.718, phi=1.618,"
}
- [1] 通过
[]运算符使用键来查找值。您可以使用keys获取所有键,使用values获取所有值。调用keys会产生一个Set,因为Map中的所有键必须是唯一的,否则在查找时会产生歧义。 - [2] 遍历
Map会产生键值对的映射条目。 - [3] 在迭代期间,您可以解包键和值。
普通的 Map 是只读的。下面是一个 MutableMap:
// Maps/MutableMaps.kt
import atomictest.eq
fun main() {
val m =
mutableMapOf(5 to "five", 6 to "six")
m[5] eq "five"
m[5] = "5ive"
m[5] eq "5ive"
m += 4 to "four"
m eq mapOf(5 to "5ive",
4 to "four", 6 to "six")
}
map[key] = value 添加或更改与 key 关联的 value。您还可以使用 map += key to value 显式地添加一对。
mapOf() 和 mutableMapOf() 保留了元素放入 Map 的顺序。对于其他类型的 Map,不保证元素的顺序。
只读的 Map 不允许进行修改:
// Maps/ReadOnlyMaps.kt
import atomictest.eq
fun main() {
val m = mapOf(5 to "five", 6 to "six")
m[5] eq "five"
// m[5] = "5ive" // 报错
// m += (4 to "four") // 报错
m + (4 to "four") // 不改变 m
m eq mapOf(5 to "five", 6 to "six")
val m2 = m + (4 to "four")
m2 eq mapOf(
5 to "five", 6 to "six", 4 to "four")
}
定义 m 创建了一个将 Int 关联到 String 的 Map。如果我们试图替换一个 String,Kotlin 将会产生错误。
带有 + 的表达式创建一个新的 Map,其中包含旧的元素和新的元素,但不影响原始 Map。向只读的 Map 添加元素的唯一方法是创建一个新的 Map。
如果 Map 中不存在给定键的条目,它将返回 null。如果您需要一个不能为 null 的结果,可以使用 getValue(),如果键丢失则捕获 NoSuchElementException:
// Maps/GetValue.kt
import atomictest.*
fun main() {
val map = mapOf('a' to "attempt")
map['b'] eq null
capture {
map.getValue('b')
} eq "NoSuchElementException: " +
"Key b is missing in the map."
map.getOrDefault('a', "??") eq "attempt"
map.getOrDefault('b', "??") eq "??"
}
getOrDefault() 通常是 null 或异常的一个更好的替代。
您可以将类实例存储为 Map 中的值。下面是一个根据数字 String 检索 Contact 的映射:
// Maps/ContactMap.kt
package maps
import atomictest.eq
class Contact(
val name: String,
val phone: String
) {
override fun toString(): String {
return "Contact('$name', '$phone')"
}
}
fun main() {
val miffy = Contact("Miffy", "1-234-567890")
val cleo = Contact("Cleo", "098-765-4321")
val contacts = mapOf(
miffy.phone to miffy,
cleo.phone to cleo)
contacts["1-234-567890"] eq miffy
contacts["1-111-111111"] eq null
}
可以使用类实例作为 Map 中的键,但这更加复杂,因此我们将在本书的后面讨论它。
- -
Map 看起来像是简单的小型数据库。它们有时被称为 关联数组,因为它们将键与值关联起来。尽管与全功能数据库相比它们相当有限,但它们仍然非常有用(并且比数据库更高效)。
练习和答案可以在 www.AtomicKotlin.com 找到。
属性访问器
要读取属性,请使用其名称。要为可变属性分配值,请使用赋值运算符
=。
下面的代码读取和写入属性 i:
// PropertyAccessors/Data.kt
package propertyaccessors
import atomictest.eq
class Data(var i: Int)
fun main() {
val data = Data(10)
data.i eq 10 // 读取 'i' 属性
data.i = 20 // 写入 'i' 属性
}
这似乎是直接访问名为i的存储位置。然而,Kotlin 在执行读取和写入操作时调用函数。默认情况下,这些函数的行为是读取和写入存储在i中的数据。在本节中,您将学习如何编写自己的属性访问器,以自定义读取和写入操作。
用于获取属性值的访问器称为getter。您可以在属性定义后立即定义 get() 来创建一个getter。用于修改可变属性的访问器称为setter。您可以在属性定义后立即定义 set() 来创建一个setter。
以下示例中定义的属性访问器模仿了Kotlin生成的默认实现。我们显示额外的信息,以便您可以看到在读取和写入过程中实际调用了属性访问器。我们将 get() 和 set() 进行了缩进,以使其与属性视觉上关联起来,但实际关联是因为 get() 和 set() 是紧跟在属性后面定义的(Kotlin 不关心缩进):
// PropertyAccessors/Default.kt
package propertyaccessors
import atomictest.*
class Default {
var i: Int = 0
get() {
trace("get()")
return field // [1]
}
set(value) {
trace("set($value)")
field = value // [2]
}
}
fun main() {
val d = Default()
d.i = 2
trace(d.i)
trace eq """
set(2)
get()
2
"""
}
get() 和 set() 的定义顺序是无关紧要的。您可以定义 get() 而不定义 set(),反之亦然。
属性的默认行为是从getter返回其存储值,并通过setter修改它——即 [1] 和 [2] 的操作。在getter和setter内部,通过使用 field 关键字来间接操作存储的值,field 只能在这两个函数内部访问。
下面的示例使用getter的默认实现,并添加一个setter来跟踪属性 n 的更改:
// PropertyAccessors/LogChanges.kt
package propertyaccessors
import atomictest.*
class LogChanges {
var n: Int = 0
set(value) {
trace("$field becomes $value")
field = value
}
}
fun main() {
val lc = LogChanges()
lc.n eq 0
lc.n = 2
lc.n eq 2
trace eq "0 becomes 2"
}
如果将属性定义为 private,那么访问器都将变为 private。您还可以将setter设置为 private,getter设置为 public。这样,您就可以在类外部读取属性,但只能在类内部更改其值:
// PropertyAccessors/Counter.kt
package propertyaccessors
import atomictest.eq
class Counter {
var value: Int = 0
private set
fun inc() = value++
}
fun main() {
val counter = Counter()
repeat(10) {
counter.inc()
}
counter.value eq 10
}
使用 private set,我们控制了 value 属性,使其只能递增。
普通属性将其数据存储在一个字段中。您还可以创建一个没有字段的属性:
// PropertyAccessors/Hamsters.kt
package propertyaccessors
import atomictest.eq
class Hamster(val name: String)
class Cage(private val maxCapacity: Int) {
private val hamsters =
mutableListOf<Hamster>()
val capacity: Int
get() = maxCapacity - hamsters.size
val full: Boolean
get() = hamsters.size == maxCapacity
fun put(hamster: Hamster): Boolean =
if (full)
false
else {
hamsters += hamster
true
}
fun take(): Hamster =
hamsters.removeAt(0)
}
fun main() {
val cage = Cage(2)
cage.full eq false
cage.capacity eq 2
cage.put(Hamster("Alice")) eq true
cage.put(Hamster("Bob")) eq true
cage.full eq true
cage.capacity eq 0
cage.put(Hamster("Charlie")) eq false
cage.take()
cage.capacity eq 1
}
属性 capacity 和 full 没有底层状态-它们在每次访问时被计算。capacity 和 full 都类似于函数,您也可以将它们定义为函数:
// PropertyAccessors/Hamsters2.kt
package propertyaccessors
class Cage2(private val maxCapacity: Int) {
private val hamsters =
mutableListOf<Hamster>()
fun capacity(): Int =
maxCapacity - hamsters.size
fun isFull(): Boolean =
hamsters.size == maxCapacity
}
在这种情况下,使用属性可以提高可读性,因为容量和满度是笼子的属性。然而,不要仅仅将所有的函数都转换为属性-首先查看它们的可读性。
- -
Kotlin 风格指南更喜欢在对象状态未更改的情况下,当值计算成本低且每次调用返回相同结果时,使用属性而不是函数。
属性访问器为属性提供了一种保护方式。许多面向对象的语言依靠将物理字段设置为 private 来控制对该属性的访问。使用属性访问器,您可以添加代码来控制或修改对该属性的访问,同时允许任何人使用该属性。
练习和解答可以在 www.AtomicKotlin.com 找到。
总结 2
如果你是一名有经验的程序员,在阅读完总结1之后,可以按顺序阅读本章节的原子。
新手程序员应该阅读本原子,并完成相关的练习作为复习。如果你对其中的任何内容不清楚,请返回并学习相关主题的原子。
这些主题按照经验丰富的程序员的适当顺序列出,这与书中的原子顺序不同。例如,我们首先介绍包和导入,以便在本原子的其余部分中使用我们的最小测试框架。
包和测试
使用 package 关键字可以将任意数量的可重用库组件打包到一个库名称下:
// Summary2/ALibrary.kt
package com.yoururl.libraryname
// Components to reuse ... 可重用组件
fun f() = "result"
你可以将多个组件放在一个文件中,也可以将组件分散在同一包名下的多个文件中。在这个例子中,我们将 f() 定义为唯一的组件。
为了使其独特,包名惯例上以你的域名的反转形式开始。在这个例子中,域名是 yoururl.com。
在 Kotlin 中,包名可以独立于其内容所在的目录。而在 Java 中,要求目录结构与完全限定的包名相对应,所以包 com.yoururl.libraryname 应该位于 com/yoururl/libraryname 目录下。对于混合 Kotlin 和 Java 的项目,Kotlin 的样式指南建议使用相同的做法。对于纯 Kotlin 项目,请将 libraryname 目录放在项目目录结构的顶级。
import 语句将一个或多个名称引入当前命名空间:
// Summary2/UseALibrary.kt
import com.yoururl.libraryname.*
fun main() {
val x = f()
}
在 libraryname 后面的星号告诉 Kotlin 导入库的所有组件。你也可以逐个选择组件;详细信息请参阅包。
在本书的其余部分,我们会为定义函数、类等的文件使用 package 语句,以避免与书中的其他文件发生名称冲突。我们通常不会在 仅包含 main() 的文件中放置 package 语句。
本书中一个重要的库是 atomictest,我们简单的测试框架。atomictest 在附录 A: AtomicTest中定义,尽管它使用了你目前可能不理解的语言特性。
在导入atomictest之后,你可以像使用语言关键字一样使用eq(等于)和neq(不等于):
// Summary2/UsingAtomicTest.kt
import atomictest.*
fun main() {
val pi = 3.14
val pie = "A round dessert"
pi eq 3.14
pie eq "A round dessert"
pi neq pie
}
/* 输出:
3.14
A round dessert
3.14
*/
在没有任何点号或括号的情况下使用eq/neq的能力称为中缀表示法。你可以以常规方式调用infix函数:pi.eq(3.14),或者使用中缀表示法:pi eq 3.14。eq和neq都是真值断言,它们会显示eq/neq语句左侧的结果,以及如果右侧表达式与左侧不等效(或者与neq的情况相等)时的错误消息。这样,你可以在源代码中看到经过验证的结果。
atomictest.trace使用函数调用语法来添加结果,然后可以使用eq来验证:
// Testing/UsingTrace.kt
import atomictest.*
fun main() {
trace("Hello,")
trace(47)
trace("World!")
trace eq """
Hello,
47
World!
"""
}
你可以有效地用trace()替换println()。
Kotlin是一种混合的面向对象和函数式语言:它支持面向对象编程和函数式编程范式。
对象包含val和var来存储数据(这些被称为属性),并使用在类内部定义的函数执行操作,称为成员函数(当不会引起歧义时,我们简称为“函数”)。类定义了属性和成员函数,用于实质上是一个新的、用户定义的数据类型。当你创建一个类的val或var时,它被称为创建一个对象或创建一个实例。
一种特别有用的对象类型是容器,也称为集合。容器是包含其他对象的对象。在本书中,我们经常使用List,因为它是最通用的序列。在这里,我们对一个包含Double的List执行了几个操作。listOf()根据其参数创建一个新的List:
// Summary2/ListCollection.kt
import atomictest.eq
fun main() {
val lst = listOf(19.2, 88.3, 22.1)
lst[1] eq 88.3 // 索引
lst.reversed() eq listOf(22.1, 88.3, 19.2)
lst.sorted() eq listOf(19.2, 22.1, 88.3)
lst.sum() eq 129.6
}
使用List不需要import语句。
Kotlin使用方括号对序列进行索引。索引是从零开始的。
这个例子还展示了一些可用于List的许多标准库函数:sorted()、reversed()和sum()。要了解这些函数的详细信息,请参阅在线的Kotlin文档。
当调用sorted()或reversed()时,lst不会被修改。相反,将创建并返回一个新的List,其中包含所需的结果。这种永不修改原始对象的方法在整个Kotlin库中是一致的,你应该在编写自己的代码时努力遵循这种模式。
创建类
一个类定义由class关键字、类名和一个可选的主体组成。主体包含属性定义(val和var)和函数定义。
这个例子定义了一个没有主体的NoBody类,以及带有val属性的类:
// Summary2/ClassBodies.kt
package summary2
class NoBody
class SomeBody {
val name = "Janet Doe"
}
class EveryBody {
val all = listOf(SomeBody(),
SomeBody(), SomeBody())
}
fun main() {
val nb = NoBody()
val sb = SomeBody()
val eb = EveryBody()
}
要创建一个类的实例,将其名称后面加上括号,以及如果需要的话还可以加上参数。
类主体中的属性可以是任何类型。SomeBody包含一个类型为String的属性,而EveryBody的属性是一个包含SomeBody对象的List。
下面是一个带有成员函数的类:
// Summary2/Temperature.kt
package summary2
import atomictest.eq
class Temperature {
var current = 0.0
var scale = "f"
fun setFahrenheit(now: Double) {
current = now
scale = "f"
}
fun setCelsius(now: Double) {
current = now
scale = "c"
}
fun getFahrenheit(): Double =
if (scale == "f")
current
else
current * 9.0 / 5.0 + 32.0
fun getCelsius(): Double =
if (scale == "c")
current
else
(current - 32.0) * 5.0 / 9.0
}
fun main() {
val temp = Temperature() // [1]
temp.setFahrenheit(98.6)
temp.getFahrenheit() eq 98.6
temp.getCelsius() eq 37.0
temp.setCelsius(100.0)
temp.getFahrenheit() eq 212.0
}
这些成员函数与我们在类外定义的顶层函数几乎一样,只是它们属于类并且可以不加限定地访问类的其他成员,例如current和scale。成员函数还可以在同一个类中无需限定地调用其他成员函数。
- [1] 虽然
temp是一个val,但我们稍后修改了Temperature对象。val定义阻止了引用temp被重新赋值为一个新对象,但它不限制对象本身的行为。
以下两个类是井字棋游戏的基础:
// Summary2/TicTacToe.kt
package summary2
import atomictest.eq
class Cell {
var entry = ' ' // [1]
fun setValue(e: Char): String = // [2]
if (entry == ' ' &&
(e == 'X' || e == 'O')) {
entry = e
"Successful move"
} else
"Invalid move"
}
class Grid {
val cells = listOf(
listOf(Cell(), Cell(), Cell()),
listOf(Cell(), Cell(), Cell()),
listOf(Cell(), Cell(), Cell())
)
fun play(e: Char, x: Int, y: Int): String =
if (x !in 0..2 || y !in 0..2)
"Invalid move"
else
cells[x][y].setValue(e) // [3]
}
fun main() {
val grid = Grid()
grid.play('X', 1, 1) eq "Successful move"
grid.play('X', 1, 1) eq "Invalid move"
grid.play('O', 1, 3) eq "Invalid move"
}
Grid类持有一个包含三个List的List,每个List包含三个Cell,形成一个矩阵。
- [1]
Cell中的entry属性是一个var,因此它可以被修改。初始化中的单引号产生一个Char类型,因此对entry的所有赋值都必须是Char类型的。 - [2]
setValue()函数检查Cell是否可用,并且你传递了正确的字符。它返回一个String结果来表示成功或失败。 - [3]
play()函数检查x和y参数是否在范围内,然后通过索引进入矩阵,依赖于setValue()执行的测试。
构造函数
构造函数用于创建新对象。你可以通过在类名后面的括号中传递参数列表来向构造函数传递信息。构造函数的调用看起来类似于函数调用,只是名称的首字母大写(遵循 Kotlin 的风格指南)。构造函数返回一个该类的对象。
// Summary2/WildAnimals.kt
package summary2
import atomictest.eq
class Badger(id: String, years: Int) {
val name = id
val age = years
override fun toString(): String {
return "Badger: $name, age: $age"
}
}
class Snake(
var type: String,
var length: Double
) {
override fun toString(): String {
return "Snake: $type, length: $length"
}
}
class Moose(
val age: Int,
val height: Double
) {
override fun toString(): String {
return "Moose, age: $age, height: $height"
}
}
fun main() {
Badger("Bob", 11) eq "Badger: Bob, age: 11"
Snake("Garden", 2.4) eq
"Snake: Garden, length: 2.4"
Moose(16, 7.2) eq
"Moose, age: 16, height: 7.2"
}
Badger中的参数id和years只在构造函数体中可用。构造函数体由除了函数定义之外的代码行组成;在这个例子中,是name和age的定义。
通常情况下,你希望构造函数的参数在类的其他部分中也可用,而不需要像name和age那样显式定义新的标识符。如果将参数声明为var或val,它们将成为属性,并且可以在类的任何地方访问。Snake和Moose都使用了这种方法,你可以看到构造函数参数现在可以在它们各自的toString()函数内部使用了。
使用val声明的构造函数参数不能被修改,而使用var声明的参数可以被修改。
每当在期望String的情况下使用一个对象时,Kotlin会通过调用其toString()成员函数来生成该对象的String表示。要定义一个toString()函数,你必须理解一个新的关键字:override。这是必要的(Kotlin要求这样做),因为toString()已经被定义了。override告诉Kotlin我们确实想用自己的定义替换默认的toString()。override的显式性使得这一点对读者清晰可见,并有助于防止错误。
注意Snake和Moose中多行参数列表的格式化方式——当你有太多参数无法在一行上容纳时,这是推荐的标准,适用于构造函数和函数。
限制可见性
Kotlin提供了类似于C++或Java等其他语言中的访问修饰符。这些修饰符允许组件创建者决定对客户程序员可见的内容。Kotlin的访问修饰符包括public、private、protected和internal关键字。protected会在后面进行解释。
像public或private这样的访问修饰符出现在类、函数或属性的定义之前。每个访问修饰符仅控制特定定义的访问权限。
public定义对所有人都可见,尤其是对使用该组件的客户程序员可见。因此,对public定义的任何更改都会影响客户端代码。
如果你不提供修饰符,你的定义会自动成为public。为了在某些情况下保持清晰,程序员有时仍然会冗余地指定public。
如果将类、顶层函数或属性定义为private,它只在该文件内可用。
// Summary2/Boxes.kt
package summary2
import atomictest.*
private var count = 0 // [1]
private class Box(val dimension: Int) { // [2]
fun volume() =
dimension * dimension * dimension
override fun toString() =
"Box volume: ${volume()}"
}
private fun countBox(box: Box) { // [3]
trace("$box")
count++
}
fun countBoxes() {
countBox(Box(4))
countBox(Box(5))
}
fun main() {
countBoxes()
trace("$count boxes")
trace eq """
Box volume: 64
Box volume: 125
2 boxes
"""
}
你只能从Boxes.kt文件的其他函数和类中访问private属性([1])、类([2])和函数([3])。Kotlin阻止你从另一个文件访问private顶层元素。
类成员可以是private的:
// Summary2/JetPack.kt
package summary2
import atomictest.eq
class JetPack(
private var fuel: Double // [1]
) {
private var warning = false
private fun burn() = // [2]
if (fuel - 1 <= 0) {
fuel = 0.0
warning = true
} else
fuel -= 1
public fun fly() = burn() // [3]
fun check() = // [4]
if (warning) // [5]
"Warning"
else
"OK"
}
fun main() {
val jetPack = JetPack(3.0)
while (jetPack.check() != "Warning") {
jetPack.check() eq "OK"
jetPack.fly()
}
jetPack.check() eq "Warning"
}
- [1]
fuel和warning都是private属性,非JetPack的成员无法使用它们。 - [2]
burn()是private的,因此只能在JetPack内部访问。 - [3]
fly()和check()是public的,可以在任何地方使用。 - [4] 没有访问修饰符意味着
public可见性。 - [5] 只有相同类的成员才能访问
private成员。
因为private定义对于所有人都不可用,所以你通常可以放心更改它,而不用担心客户端程序员的影响。作为库设计者,你通常会尽可能将所有内容保持为private,只暴露你希望客户端程序员使用的函数和类。为了限制本书中示例清单的大小和复杂性,我们只在特殊情况下使用private。
任何你确定只是一个辅助函数的函数都可以设置为private,以确保你不会意外地在其他地方使用它,从而限制了你更改或删除该函数的能力。
将大型程序划分为模块可能是有用的。模块是代码库的逻辑独立部分。internal定义仅在定义它的模块内部可访问。如何将项目划分为模块取决于构建系统(例如Gradle或Maven),超出了本书的范围。
模块是一个更高级的概念,而包允许更细粒度的结构化。
异常
考虑toDouble()函数,它将一个String转换为一个Double。如果你对一个无法转换为Double的String调用它,会发生什么呢?
// Summary2/ToDoubleException.kt
fun main() {
// val i = "$1.9".toDouble()
}
取消注释main()函数中的那一行会导致异常。在这里,我们将失败的那一行注释掉,这样可以避免停止书籍的构建过程(构建过程会检查每个示例是否按预期编译和运行)。
当抛出异常时,当前的执行路径停止,异常对象从当前上下文中退出。如果异常未被捕获,程序会中止并显示一个包含详细信息的堆栈跟踪。
为了避免通过注释和取消注释代码来显示异常,atomictest.capture()函数可以捕获异常并将其与我们的期望进行比较:
// Summary2/AtomicTestCapture.kt
import atomictest.*
fun main() {
capture {
"$1.9".toDouble()
} eq "NumberFormatException: " +
"""For input string: '$1.9'"""
}
capture()函数是专门为本书设计的,它可以让您查看异常并知道输出已经经过了书籍的构建系统检查。
当您的函数无法成功生成预期结果时,另一种策略是返回null。稍后在可空类型中,我们将讨论null如何影响结果表达式的类型。
要抛出异常,使用throw关键字,后面跟随您想要抛出的异常以及它可能需要的任何参数。以下示例中的quadraticZeroes()函数解决了定义抛物线的二次方程:
ax2 + bx + c = 0
解法是二次方程公式:
二次方程公式
该示例找出了抛物线的零点,即抛物线与x轴相交的点。我们为两个限制条件抛出异常:
a不能为零。- 为了使零点存在,b2 - 4ac 不能为负。
如果零点存在,则有两个零点,因此我们创建了Roots类来保存返回值:
// Summary2/Quadratic.kt
package summary2
import kotlin.math.sqrt
import atomictest.*
class Roots(
val root1: Double,
val root2: Double
)
fun quadraticZeroes(
a: Double,
b: Double,
c: Double
): Roots {
if (a == 0.0)
throw IllegalArgumentException(
"a is zero")
val underRadical = b * b - 4 * a * c
if (underRadical < 0)
throw IllegalArgumentException(
"Negative underRadical: $underRadical")
val squareRoot = sqrt(underRadical)
val root1 = (-b - squareRoot) / 2 * a
val root2 = (-b + squareRoot) / 2 * a
return Roots(root1, root2)
}
fun main() {
capture {
quadraticZeroes(0.0, 4.0, 5.0)
} eq "IllegalArgumentException: " +
"a is zero"
capture {
quadraticZeroes(3.0, 4.0, 5.0)
} eq "IllegalArgumentException: " +
"Negative underRadical: -44.0"
val roots = quadraticZeroes(3.0, 8.0, 5.0)
roots.root1 eq -15.0
roots.root2 eq -9.0
}
在这里,我们使用了标准异常类IllegalArgumentException。稍后您将学习如何定义自己的异常类型,并使它们针对您的特定情况。您的目标是生成尽可能有用的消息,以便将来更容易支持您的应用程序。
列表
List是Kotlin的基本顺序容器类型。您可以使用listOf()创建一个只读列表,使用mutableListOf()创建一个可变列表:
// Summary2/ReadonlyVsMutableList.kt
import atomictest.*
fun main() {
val ints = listOf(5, 13, 9)
// ints.add(11) // 'add()' not available
for (i in ints) {
if (i > 10) {
trace(i)
}
}
val chars = mutableListOf('a', 'b', 'c')
chars.add('d') // 'add()' available
chars += 'e'
trace(chars)
trace eq """
13
[a, b, c, d, e]
"""
}
基本的 List 是只读的,不包含修改函数。因此,修改函数 add() 在 ints 上不起作用。
for 循环与 List 配合使用很好:for(i in ints) 表示 i 获取 ints 中的每个值。
chars 被创建为 MutableList,可以使用 add() 或 remove() 等函数对其进行修改。你也可以使用 += 和 -= 来添加或删除元素。
只读的 List 和 不可变 的 List 是不同的,后者根本无法被修改。在这里,我们将可变的 List first 赋值给只读的 List 引用 second。second 的只读特性并不阻止通过 first 对 List 进行修改。
// Summary2/MultipleListReferences.kt
import atomictest.eq
fun main() {
val first = mutableListOf(1)
val second: List<Int> = first
second eq listOf(1)
first += 2
// second sees the change:
second eq listOf(1, 2)
}
first 和 second 引用的是同一个内存中的对象。我们通过 first 引用对 List 进行修改,然后在 second 引用中观察到这个变化。
这是一个由三引号段落分割而成的 String 列表。这展示了一些标准库函数的强大之处。请注意这些函数如何可以链式调用:
// Summary2/ListOfStrings.kt
import atomictest.*
fun main() {
val wocky = """
Twas brillig, and the slithy toves
Did gyre and gimble in the wabe:
All mimsy were the borogoves,
And the mome raths outgrabe.
""".trim().split(Regex("\\W+"))
trace(wocky.take(5))
trace(wocky.slice(6..12))
trace(wocky.slice(6..18 step 2))
trace(wocky.sorted().takeLast(5))
trace(wocky.sorted().distinct().takeLast(5))
trace eq """
[Twas, brillig, and, the, slithy]
[Did, gyre, and, gimble, in, the, wabe]
[Did, and, in, wabe, mimsy, the, And]
[the, the, toves, wabe, were]
[slithy, the, toves, wabe, were]
"""
}
trim() 生成一个新的 String,去除开头和结尾的空白字符(包括换行符)。split() 根据参数将 String 分割成多个部分。在这种情况下,我们使用一个 Regex 对象,它创建了一个正则表达式,即匹配要分割的部分的模式。\W 是一个特殊的模式,表示“非单词字符”,+ 表示“一个或多个前面的字符”。因此,split() 将在一个或多个非单词字符处进行分割,从而将文本块分割为组成单词的部分。
在 String 字面值中,\ 位于特殊字符之前,并产生特殊字符,例如换行符 (\n) 或制表符 (\t)。要在生成的字符串中产生一个实际的 \,您需要使用两个反斜杠:"\\"。因此,所有正则表达式都需要额外的 \ 来插入反斜杠,除非您使用三引号的 String:"""\W+"""。
take(n) 生成一个包含前 n 个元素的新 List。slice() 生成一个包含由其 Range 参数选择的元素的新 List,而此 Range 可以包含一个步长。
请注意 sorted() 的命名,而不是 sort()。当您调用 sorted() 时,它会生成一个已排序的 List,而不会修改原始的 List。sort() 只适用于 MutableList,并且会就地对列表进行排序,即修改原始的 List。
正如其名称所示,takeLast(n) 生成一个包含最后 n 个元素的新 List。从输出中可以看到,“the” 被重复了。通过在调用链中添加 distinct() 函数可以消除重复项。
参数化类型
参数化类型允许我们描述复合类型,最常见的是容器类型。特别是,类型参数指定了容器所包含的内容。在这里,我们告诉 Kotlin numbers 包含一个 List 类型的 Int,而 strings 包含一个 List 类型的 String。
// Summary2/ExplicitTyping.kt
package summary2
import atomictest.eq
fun main() {
val numbers: List<Int> = listOf(1, 2, 3)
val strings: List<String> =
listOf("one", "two", "three")
numbers eq "[1, 2, 3]"
strings eq "[one, two, three]"
toCharList("seven") eq "[s, e, v, e, n]"
}
fun toCharList(s: String): List<Char> =
s.toList()
对于numbers和strings的定义,我们添加了冒号和类型声明List<Int>和List<String>。尖括号表示类型参数,允许我们说:“容器中保存了‘参数’对象”。通常将List<Int>读作“Int的List”。
返回值也可以有类型参数,就像toCharList()函数中所示。你不能只说它返回一个List,Kotlin会报错,因此你必须给出类型参数。
可变参数列表
vararg关键字是可变参数列表的简写形式,允许函数接受任意数量(包括零个)指定类型的参数。vararg会变成一个Array,它类似于一个List:
// Summary2/VarArgs.kt
package summary2
import atomictest.*
fun varargs(s: String, vararg ints: Int) {
for (i in ints) {
trace("$i")
}
trace(s)
}
fun main() {
varargs("primes", 5, 7, 11, 13, 17, 19, 23)
trace eq "5 7 11 13 17 19 23 primes"
}
函数定义只能指定一个参数为vararg。列表中的任何参数都可以是vararg,但通常最后一个参数最简单。
你可以在任何接受vararg的地方传递一个元素的Array。要创建一个Array,可以使用arrayOf(),方式与使用listOf()类似。注意,Array始终是可变的。要将一个Array转换为一系列参数(不仅仅是一个类型为Array的单个元素),可以使用展开操作符*:
// Summary2/ArraySpread.kt
import summary2.varargs
import atomictest.trace
fun main() {
val array = intArrayOf(4, 5) // [1]
varargs("x", 1, 2, 3, *array, 6) // [2]
val list = listOf(9, 10, 11)
varargs(
"y", 7, 8, *list.toIntArray()) // [3]
trace eq "1 2 3 4 5 6 x 7 8 9 10 11 y"
}
如果像上面的例子一样传递原始类型的Array,那么创建Array的函数必须具有特定的类型。如果**[1]使用arrayOf(4, 5)而不是intArrayOf(4, 5),[2]**会产生错误:推断类型为Array<Int>,但期望的是IntArray。
展开操作符只适用于数组。如果你有一个List要作为一系列参数传递,首先将其转换为Array,然后应用展开操作符,如**[3]**所示。因为结果是一个原始类型的Array,我们必须使用特定的转换函数toIntArray()。
集合
Set是只允许包含唯一值的集合。Set会自动防止重复元素的存在。
// Summary2/ColorSet.kt
package summary2
import atomictest.eq
val colors =
"Yellow Green Green Blue"
.split(Regex("""\W+""")).sorted() // [1]
fun main() {
colors eq
listOf("Blue", "Green", "Green", "Yellow")
val colorSet = colors.toSet() // [2]
colorSet eq
setOf("Yellow", "Green", "Blue")
(colorSet + colorSet) eq colorSet // [3]
val mSet = colorSet.toMutableSet() // [4]
mSet -= "Blue"
mSet += "Red" // [5]
mSet eq
setOf("Yellow", "Green", "Red")
// Set membership:
("Green" in colorSet) eq true // [6]
colorSet.contains("Red") eq false
}
- [1] 使用之前在
ListOfStrings.kt中描述的正则表达式,将字符串进行split()操作。 - [2] 将
colors复制到只读的Set colorSet中时,其中一个重复的字符串"Green"被移除,因为集合中只允许唯一的元素。 - [3] 在这里,我们使用
+操作符创建并显示一个新的Set。将重复的元素放入Set会自动移除这些重复项。 - [4] 使用
toMutableSet()函数可以从只读的Set创建一个新的MutableSet。 - [5] 对于
MutableSet,+=和-=操作符用于添加和删除元素,与MutableList的操作类似。 - [6] 使用
in或contains()操作符来测试元素是否属于Set。
所有常规的数学集合操作,如并集、交集、差集等,都可用于Set。
映射
Map用于将键和值进行关联,并在给定键时查找对应的值。通过向mapOf()函数提供键值对来创建Map。使用to关键字将每个键与其关联的值分隔开:
// Summary2/ASCIIMap.kt
import atomictest.eq
fun main() {
val ascii = mapOf(
"A" to 65,
"B" to 66,
"C" to 67,
"I" to 73,
"J" to 74,
"K" to 75
)
ascii eq
"{A=65, B=66, C=67, I=73, J=74, K=75}"
ascii["B"] eq 66 // [1]
ascii.keys eq "[A, B, C, I, J, K]"
ascii.values eq
"[65, 66, 67, 73, 74, 75]"
var kv = ""
for (entry in ascii) { // [2]
kv += "${entry.key}:${entry.value},"
}
kv eq "A:65,B:66,C:67,I:73,J:74,K:75,"
kv = ""
for ((key, value) in ascii) // [3]
kv += "$key:$value,"
kv eq "A:65,B:66,C:67,I:73,J:74,K:75,"
val mutable = ascii.toMutableMap() // [4]
mutable.remove("I")
mutable eq
"{A=65, B=66, C=67, J=74, K=75}"
mutable.put("Z", 90)
mutable eq
"{A=65, B=66, C=67, J=74, K=75, Z=90}"
mutable.clear()
mutable["A"] = 100
mutable eq "{A=100}"
}
- [1] 使用键(
"B")通过[]操作符查找对应的值。你可以使用keys访问所有的键,使用values访问所有的值。访问keys会产生一个Set,因为Map中的所有键必须是唯一的(否则在查找时会存在歧义)。 - [2] 遍历
Map会产生键值对的映射项。 - [3] 在迭代时可以解构键值对。
- [4] 使用
toMutableMap()可以从只读的Map创建一个MutableMap。现在我们可以对mutable进行修改操作,比如remove()、put()和clear()。方括号可以将一个新的键值对赋值给mutable。你也可以通过map += key to value的方式添加一对键值对。
属性访问器
访问属性i看起来很直观:
// Summary2/PropertyReadWrite.kt
package summary2
import atomictest.eq
class Holder(var i: Int)
fun main() {
val holder = Holder(10)
holder.i eq 10 // Read the 'i' property
holder.i = 20 // Write to the 'i' property
}
然而,Kotlin调用函数来执行读取和写入操作。这些函数的默认行为是读取和写入存储在i中的数据。通过创建属性访问器,你可以改变读取和写入过程中发生的操作。
用于获取属性值的访问器称为getter。要创建自己的getter,需在属性声明之后立即定义get()函数。用于修改可变属性的访问器称为setter。要创建自己的setter,需在属性声明之后立即定义set()函数。定义getter和setter的顺序并不重要,你可以单独定义其中一个。
下面的示例中的属性访问器模仿了默认实现,同时显示额外的信息,以便你可以看到属性访问器在读取和写入时确实被调用。我们对get()和set()函数进行了缩进,以在视觉上将它们与属性关联起来,但实际的关联是因为它们在属性之后立即定义的:
// Summary2/GetterAndSetter.kt
package summary2
import atomictest.*
class GetterAndSetter {
var i: Int = 0
get() {
trace("get()")
return field
}
set(value) {
trace("set($value)")
field = value
}
}
fun main() {
val gs = GetterAndSetter()
gs.i = 2
trace(gs.i)
trace eq """
set(2)
get()
2
"""
}
在getter和setter内部,使用field关键字间接操作存储的值,该关键字只能在这两个函数内部访问。你也可以创建一个没有field的属性,而是简单地调用getter来产生结果。
如果声明一个private属性,那么两个访问器都将变为private。你可以将setter设置为private,getter设置为public。这意味着你可以在类外读取属性,但只能在类内部更改其值。
练习和解答可在www.AtomicKotlin.com找到。
第三部分:可用性
“计算机语言的区别在于它们能够让什么变得容易,而不是仅仅让什么成为可能。” — Larry Wall,Perl语言的发明者
扩展函数
假设你发现了一个几乎能满足你所有需求的库,但如果它再多提供一个或两个额外的成员函数,就能完美解决你的问题。
但这并不是你的代码,要么你无法访问源代码,要么你无法控制它。每当新版本发布时,你都必须重复进行修改。
Kotlin 的扩展函数可以有效地向现有类添加成员函数。你所扩展的类型被称为 接收者。要定义一个扩展函数,你需要在函数名之前加上接收者类型:
fun ReceiverType.extensionFunction() { ... }
这将为String类添加两个扩展函数:
// ExtensionFunctions/Quoting.kt
package extensionfunctions
import atomictest.eq
fun String.singleQuote() = "'$this'"
fun String.doubleQuote() = "\"$this\""
fun main() {
"Hi".singleQuote() eq "'Hi'"
"Hi".doubleQuote() eq "\"Hi\""
}
您可以像调用类成员一样调用扩展函数。
要使用来自另一个包的扩展函数,您必须先导入它们:
// ExtensionFunctions/Quote.kt
package other
import atomictest.eq
import extensionfunctions.doubleQuote
import extensionfunctions.singleQuote
fun main() {
"Single".singleQuote() eq "'Single'"
"Double".doubleQuote() eq "\"Double\""
}
您可以使用关键字 this 访问成员函数或其他扩展函数。与类内部一样,您也可以省略 this 关键字,因此无需显式限定:
// ExtensionFunctions/StrangeQuote.kt
package extensionfunctions
import atomictest.eq
// Apply two sets of single quotes:
fun String.strangeQuote() =
this.singleQuote().singleQuote() // [1]
fun String.tooManyQuotes() =
doubleQuote().doubleQuote() // [2]
fun main() {
"Hi".strangeQuote() eq "''Hi''"
"Hi".tooManyQuotes() eq "\"\"Hi\"\""
}
- [1]
this指的是String接收器。 - [2] 我们省略了第一个
doubleQuote()函数调用的接收器对象(this)。
创建自己类的扩展有时可以产生更简洁的代码:
// ExtensionFunctions/BookExtensions.kt
package extensionfunctions
import atomictest.eq
class Book(val title: String)
fun Book.categorize(category: String) =
"""title: "$title", category: $category"""
fun main() {
Book("Dracula").categorize("Vampire") eq
"""title: "Dracula", category: Vampire"""
}
在 categorize() 内部,我们可以直接访问 title 属性,无需显式限定。
请注意,扩展函数只能访问被扩展类型的
public元素。因此,扩展函数只能执行与普通函数相同的操作。您可以将Book.categorize(String)重写为categorize(Book, String)。使用扩展函数的唯一原因是语法,但这种语法糖非常强大。对于调用代码而言,扩展函数看起来与成员函数相同,而且IDE在列出对象可调用的函数时会显示扩展函数。
练习和解答可以在 www.AtomicKotlin.com 找到。
命名参数和默认参数
在函数调用过程中,您可以提供参数名称。
命名参数提高了代码的可读性。这对于参数列表很长且复杂的情况尤为重要 - 命名参数可以足够清晰,以至于读者可以在不查看文档的情况下理解函数调用。
在下面的示例中,所有的参数都是 Int 类型。命名参数可以澄清它们的含义:
// NamedAndDefaultArgs/NamedArguments.kt
package color1
import atomictest.eq
fun color(red: Int, green: Int, blue: Int) =
"($red, $green, $blue)"
fun main() {
color(1, 2, 3) eq "(1, 2, 3)" // [1]
color(
red = 76, // [2]
green = 89,
blue = 0
) eq "(76, 89, 0)"
color(52, 34, blue = 0) eq // [3]
"(52, 34, 0)"
}
- [1] 这并没有提供太多信息。您需要查看文档才能知道这些参数的含义。
- [2] 每个参数的含义都很清晰。
- [3] 您不需要为所有的参数命名。
命名参数使您可以更改颜色的顺序。在这里,我们首先指定了 blue:
// NamedAndDefaultArgs/ArgumentOrder.kt
import color1.color
import atomictest.eq
fun main() {
color(blue = 0, red = 99, green = 52) eq
"(99, 52, 0)"
color(red = 255, 255, 0) eq
"(255, 255, 0)"
}
您可以混合使用命名参数和常规(位置)参数。如果更改参数的顺序,您应该在整个调用过程中使用命名参数 - 不仅仅是为了可读性,还因为编译器通常需要告诉它们参数的位置。
当与默认参数结合使用时,命名参数尤其有用。默认参数是函数定义中指定的参数的默认值:
// NamedAndDefaultArgs/Color2.kt
package color2
import atomictest.eq
fun color(
red: Int = 0,
green: Int = 0,
blue: Int = 0,
) = "($red, $green, $blue)"
fun main() {
color(139) eq "(139, 0, 0)"
color(blue = 139) eq "(0, 0, 139)"
color(255, 165) eq "(255, 165, 0)"
color(red = 128, blue = 128) eq
"(128, 0, 128)"
}
如果不提供任何参数,那么未提供的参数将采用其默认值,因此您只需要提供与默认值不同的参数。如果参数列表很长,这简化了生成的代码,使其更易于编写和阅读。
该示例还在 color() 的定义中使用了 尾随逗号。尾随逗号是最后一个参数(blue)之后的额外逗号。当参数或值写在多行上时,这非常有用。有了尾随逗号,您可以添加新项目并更改它们的顺序,而无需添加或删除逗号。
命名参数和默认参数(以及尾随逗号)在构造函数中同样适用:
// NamedAndDefaultArgs/Color3.kt
package color3
import atomictest.eq
class Color(
val red: Int = 0,
val green: Int = 0,
val blue: Int = 0,
) {
override fun toString() =
"($red, $green, $blue)"
}
fun main() {
Color(red = 77).toString() eq "(77, 0, 0)"
}
joinToString() 是一个使用默认参数的标准库函数。它将可迭代对象(列表、集合或范围)的内容合并为一个 String。您可以指定分隔符、前缀元素和后缀元素:
// NamedAndDefaultArgs/CreateString.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3,)
list.toString() eq "[1, 2, 3]"
list.joinToString() eq "1, 2, 3"
list.joinToString(prefix = "(",
postfix = ")") eq "(1, 2, 3)"
list.joinToString(separator = ":") eq
"1:2:3"
}
默认情况下,List 的默认 toString() 方法会返回方括号中的内容,这可能不是您想要的。joinToString() 的参数的默认值是用逗号作为 separator,用空字符串作为 prefix 和 postfix。在上面的示例中,我们使用命名参数和默认参数来指定我们想要更改的参数。
list 的初始化器包含一个尾随逗号。通常,只有在每个元素占据一行的情况下才会使用尾随逗号。
如果将对象用作默认参数,则会为每次调用创建该对象的新实例:
// NamedAndDefaultArgs/Evaluation.kt
package namedanddefault
class DefaultArg
fun h(d: DefaultArg = DefaultArg()) =
println(d)
fun main() {
h()
h()
}
/* Sample output:
DefaultArg@28d93b30
DefaultArg@1b6d3586
*/
h() 的两次调用的 DefaultArg 对象的地址不同,表明存在两个不同的对象。
当提高可读性时,请指定参数名称。比较以下两个对 joinToString() 的调用:
// NamedAndDefaultArgs/CreateString2.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3)
list.joinToString(". ", "", "!") eq
"1. 2. 3!"
list.joinToString(separator = ". ",
postfix = "!") eq "1. 2. 3!"
}
如果没有记住参数顺序的话,很难猜测 ". " 或 "" 是分隔符。
作为默认参数的另一个示例,trimMargin() 是一个标准库函数,用于格式化多行的 String。它使用边距前缀 String 来确定每行的开头。trimMargin() 会从源 String 的每一行中去除前导空白字符和边距前缀。如果第一行和最后一行是空行,则它会删除它们:
// NamedAndDefaultArgs/TrimMargin.kt
import atomictest.eq
fun main() {
val poem = """
|->Last night I saw upon the stair
|->A little man who wasn't there
|->He wasn't there again today
|->Oh, how I wish he'd go away."""
poem.trimMargin() eq
"""->Last night I saw upon the stair
->A little man who wasn't there
->He wasn't there again today
->Oh, how I wish he'd go away."""
poem.trimMargin(marginPrefix = "|->") eq
"""Last night I saw upon the stair
A little man who wasn't there
He wasn't there again today
Oh, how I wish he'd go away."""
}
|(“pipe”)是边距前缀的默认参数,您可以将其替换为所选的 String。
练习和解答可以在 www.AtomicKotlin.com 上找到。
重载
在没有默认参数支持的语言中,通常使用重载来模拟该功能。
术语重载是指函数的名称:您可以使用相同的名称(为该名称重载)来表示不同的函数,只要参数列表不同即可。以下是对成员函数 f() 进行重载的示例:
// Overloading/Overloading.kt
package overloading
import atomictest.eq
class Overloading {
fun f() = 0
fun f(n: Int) = n + 2
}
fun main() {
val o = Overloading()
o.f() eq 0
o.f(11) eq 13
}
在 Overloading 类中,我们看到两个具有相同名称 f() 的函数。函数的签名由名称、参数列表和返回类型组成。Kotlin 通过比较签名来区分不同的函数。在重载函数时,参数列表必须是唯一的,不能根据返回类型进行重载。
上述调用表明它们确实是不同的函数。函数签名还包括关于封闭类的信息(或者如果它是扩展函数,则是接收者类型)。
请注意,如果类已经有一个与扩展函数具有相同签名的成员函数,则 Kotlin 会优先选择成员函数。但是,您可以使用扩展函数重载成员函数:
// Overloading/MemberVsExtension.kt
package overloading
import atomictest.eq
class My {
fun foo() = 0
}
fun My.foo() = 1 // [1]
fun My.foo(i: Int) = i + 2 // [2]
fun main() {
My().foo() eq 0
My().foo(1) eq 3
}
- [1] 声明重复成员函数的扩展是没有意义的,因为它永远不会被调用。
- [2] 您可以使用扩展函数通过提供不同的参数列表来重载成员函数。
不要使用重载来模拟默认参数。也就是说,不要这样做:
// Overloading/WithoutDefaultArguments.kt
package withoutdefaultarguments
import atomictest.eq
fun f(n: Int) = n + 373
fun f() = f(0)
fun main() {
f() eq 373
}
没有参数的函数只是调用了第一个函数。通过使用默认参数,这两个函数可以被一个函数替代:
// Overloading/WithDefaultArguments.kt
package withdefaultarguments
import atomictest.eq
fun f(n: Int = 0) = n + 373
fun main() {
f() eq 373
}
在这两个示例中,您可以在没有参数的情况下调用函数,或者通过传递整数值来调用函数。更推荐使用 WithDefaultArguments.kt 中的形式。
在使用重载函数和默认参数时,调用重载函数会搜索“最近”的匹配项。在下面的示例中,`
main()中的foo()` 调用不会调用带有默认参数 99 的函数的第一个版本,而是调用第二个版本,即没有参数的版本:
// Overloading/OverloadedVsDefaultArg.kt
package overloadingvsdefaultargs
import atomictest.*
fun foo(n: Int = 99) = trace("foo-1-$n")
fun foo() {
trace("foo-2")
foo(14)
}
fun main() {
foo()
trace eq """
foo-2
foo-1-14
"""
}
您永远无法使用默认参数 99,因为 foo() 总是调用 f() 的第二个版本。
为什么重载有用?它允许您更清楚地表达“同一主题的变化”,而不是被迫使用不同的函数名称。假设您想要添加函数:
// Overloading/OverloadingAdd.kt
package overloading
import atomictest.eq
fun addInt(i: Int, j: Int) = i + j
fun addDouble(i: Double, j: Double) = i + j
fun add(i: Int, j: Int) = i + j
fun add(i: Double, j: Double) = i + j
fun main() {
addInt(5, 6) eq add(5, 6)
addDouble(56.23, 44.77) eq
add(56.23, 44.77)
}
addInt() 接受两个 Int,返回一个 Int,而 addDouble() 接受两个 Double,返回一个 Double。如果没有重载,您无法将操作命名为 add(),因此程序员通常将 what 与 how 混为一谈,以生成唯一的名称(您也可以使用随机字符创建唯一的名称,但是通常的模式是使用参数类型等有意义的信息)。相比之下,重载的 add() 更清晰。
在语言中缺少重载并不是一个严重的困扰,但这个特性提供了宝贵的简化,产生了更可读的代码。使用重载时,您只需要说出 what,这提高了抽象级别,减轻了读者的思维负担。如果您想了解 how,可以查看参数。请注意,重载减少了冗余:如果我们必须说
addInt()和addDouble(),那么实际上在函数名称中重复了参数信息。
练习和解答可以在 www.AtomicKotlin.com 上找到。
when 表达式
当一个模式匹配时,执行相应的操作是计算机编程中的重要部分。
任何简化此任务的工具对程序员来说都是一种福音。当需要做出超过两三个选择时,when表达式比if表达式更加方便。
when表达式用于将一个值与一组可能性进行比较。它以关键字when和要比较的括号内的值开始。接下来是一个包含一组可能的匹配和它们关联的操作的主体。每个匹配都是一个表达式,后面跟着一个右箭头->。箭头是两个分开的字符-和>,之间没有空白字符。该表达式会被求值并与目标值进行比较。如果匹配成功,则->右侧的表达式将成为when表达式的结果。
下面的示例中,ordinal()函数根据基数数词构建德语序数词。它将整数与固定的一组数进行匹配,以检查它们是否适用于一般规则或是例外情况(在德语中这种情况非常常见):
// WhenExpressions/GermanOrdinals.kt
package whenexpressions
import atomictest.eq
val numbers = mapOf(
1 to "eins", 2 to "zwei", 3 to "drei",
4 to "vier", 5 to "fuenf", 6 to "sechs",
7 to "sieben", 8 to "acht", 9 to "neun",
10 to "zehn", 11 to "elf", 12 to "zwoelf",
13 to "dreizehn", 14 to "vierzehn",
15 to "fuenfzehn", 16 to "sechzehn",
17 to "siebzehn", 18 to "achtzehn",
19 to "neunzehn", 20 to "zwanzig"
)
fun ordinal(i: Int): String =
when (i) { // [1]
1 -> "erste" // [2]
3 -> "dritte"
7 -> "siebte"
8 -> "achte"
20 -> "zwanzigste"
else -> numbers.getValue(i) + "te" // [3]
}
fun main() {
ordinal(2) eq "zweite"
ordinal(3) eq "dritte"
ordinal(11) eq "elfte"
}
- [1]
when表达式将i与主体中的匹配表达式进行比较。 - [2] 第一个匹配成功的表达式将完成
when表达式的执行,这里会产生一个String,成为ordinal()的返回值。 - [3]
else关键字表示当没有匹配时会“穿透”。
else分支始终出现在匹配列表的最后。当我们对2进行测试时,它不与1、3、7、8或20匹配,因此会进入else分支。
如果在上面的示例中忘记添加else分支,编译时会出现错误:“‘when’表达式必须是穷尽的,请添加必要的‘else’分支”。如果将when表达式视为语句(即不使用when的结果),可以省略else分支。此时未匹配的值将被忽略。
在下面的示例中,Coordinates类使用属性访问器报告其属性的更改。when表达式处理inputs列表中的每个项目:
// WhenExpressions/AnalyzeInput.kt
package whenexpressions
import atomictest.*
class Coordinates {
var x: Int = 0
set(value) {
trace("x gets $value")
field = value
}
var y: Int = 0
set(value) {
trace("y gets $value")
field = value
}
override fun toString() = "($x, $y)"
}
fun processInputs(inputs: List<String>) {
val coordinates = Coordinates()
for (input in inputs) {
when (input) { // [1]
"up", "u" -> coordinates.y-- // [2]
"down", "d" -> coordinates.y++
"left", "l" -> coordinates.x--
"right", "r" -> { // [3]
trace("Moving right")
coordinates.x++
}
"nowhere" -> {} // [4]
"exit" -> return // [5]
else -> trace("bad input: $input")
}
}
}
fun main() {
processInputs(listOf("up", "d", "nowhere",
"left", "right", "exit", "r"))
trace eq """
y gets -1
y gets 0
x gets -1
Moving right
x gets 0
"""
}
- [1]
input与不同的选项进行匹配。 - [2] 可以使用逗号在一个分支中列出多个值。这里,如果用户输入的是“up”或“u”,我们将其解释为向上移动。
- [3] 一个分支内的多个动作必须位于一个代码块中。
- [4] 使用空代码块表示“什么都不做”。
- [5] 在一个分支中从外部函数返回是有效的操作。在这里,
return终止对processInputs()的调用。
when表达式的参数可以是任何表达式,并且匹配可以是任何值(不仅限于常量):
// WhenExpressions/MatchingAgainstVals.kt
import atomictest.*
fun main() {
val yes = "A"
val no = "B"
for (choice in listOf(yes, no, yes)) {
when (choice) {
yes -> trace("Hooray!")
no -> trace("Too bad!")
}
// 使用 'if' 相同的逻辑:
if (choice == yes) trace("Hooray!")
else if (choice == no) trace("Too bad!")
}
trace eq """
Hooray!
Hooray!
Too bad!
Too bad!
Hooray!
Hooray!
"""
}
when表达式可以覆盖if表达式的功能。由于when更灵活,因此在有选择的情况下更推荐使用它。
我们可以将一个值的Set与另一个值的Set进行匹配:
// WhenExpressions/MixColors.kt
package whenexpressions
import atomictest.eq
fun mixColors(first: String, second: String) =
when (setOf(first, second)) {
setOf("red", "blue") -> "purple"
setOf("red", "yellow") -> "orange"
setOf("blue", "yellow") -> "green"
else -> "unknown"
}
fun main() {
mixColors("red", "blue") eq "purple"
mixColors("blue", "red") eq "purple"
mixColors("blue", "purple") eq "unknown"
}
在mixColors()中,我们使用Set作为when的参数,并将其与不同的Set进行比较。我们使用Set是因为元素的顺序是不重要的,当我们混合“red”和“blue”与混合“blue”和“red”时,我们需要相同的结果。
when有一种特殊的形式,它不带参数。省略参数意味着分支可以检查不同的布尔条件。您可以使用任何布尔表达式作为分支条件。例如,我们重新编写了Number Types中介绍的bmiMetric(),首先显示原始解决方案,然后使用when替代if:
// WhenExpressions/BmiWhen.kt
package whenexpressions
import atomictest.eq
fun bmiMetricOld(
kg: Double,
heightM: Double
): String {
val bmi = kg / (heightM * heightM)
return if (bmi < 18.5) "Underweight"
else if (bmi < 25) "Normal weight"
else "Overweight"
}
fun bmiMetricWithWhen(
kg: Double,
heightM: Double
): String {
val bmi = kg / (heightM * heightM)
return when {
bmi < 18.5 -> "Underweight"
bmi < 25 -> "Normal weight"
else -> "Overweight"
}
}
fun main() {
bmiMetricOld(72.57, 1.727) eq
bmiMetricWithWhen(72.57, 1.727)
}
使用when的解决方案是选择多个选项之间的更优雅的方式。
练习和解答可以在 www.AtomicKotlin.com 上找到。
枚举
枚举是一组名称的集合。
Kotlin中的enum class是管理这些名称的便捷方式:
// Enumerations/Level.kt
package enumerations
import atomictest.eq
enum class Level {
Overflow, High, Medium, Low, Empty
}
fun main() {
Level.Medium eq "Medium"
}
创建一个枚举会生成enum名称的toString()方法。
在main()中,您必须对枚举名称的每个引用进行限定,就像Level.Medium一样。您可以使用import将枚举中的所有名称引入到当前的命名空间(命名空间可以防止名称之间的冲突):
// Enumerations/EnumImport.kt
import atomictest.eq
import enumerations.Level.* // [1]
fun main() {
Overflow eq "Overflow"
High eq "High"
}
- [1]
*导入了Level枚举内的所有名称,但不导入Level这个名称本身。
您可以将枚举值导入到定义枚举类的同一个文件中:
// Enumerations/RecursiveEnumImport.kt
package enumerations
import atomictest.eq
import enumerations.Size.* // [1]
enum class Size {
Tiny, Small, Medium, Large, Huge, Gigantic
}
fun main() {
Gigantic eq "Gigantic" // [2]
Size.values().toList() eq // [3]
listOf(Tiny, Small, Medium,
Large, Huge, Gigantic)
Tiny.ordinal eq 0 // [4]
Huge.ordinal eq 4
}
- [1] 我们在
Size定义出现之前就导入了Size的值。 - [2] 在
import之后,我们不再需要限定访问枚举名称。 - [3] 您可以使用
values()遍历枚举名称。values()返回一个数组,因此我们调用toList()将其转换为列表。 - [4]
enum的第一个声明的常量具有ordinal值为零。每个后续的常量都会获得下一个整数值。
您可以使用when表达式对不同的枚举条目执行不同的操作。这里,我们导入了Level的名称以及其所有条目:
// Enumerations/CheckingOptions.kt
package checkingoptions
import atomictest.*
import enumerations.Level
import enumerations.Level.*
fun checkLevel(level: Level) {
when (level) {
Overflow -> trace(">>> Overflow!")
Empty -> trace("Alert: Empty")
else -> trace("Level $level OK")
}
}
fun main() {
checkLevel(Empty)
checkLevel(Low)
checkLevel(Overflow)
trace eq """
Alert: Empty
Level Low OK
>>> Overflow!
"""
}
checkLevel()仅针对两个常量执行特定的操作,而对于其他所有选项则表现正常(else情况)。
枚举是一种特殊类型的类,它有固定数量的实例,这些实例都列在类体内。除此之外,enum类的行为与常规类相同,因此您可以定义成员属性和函数。如果包含额外的元素,则必须在最后一个枚举值后添加一个分号:
// Enumerations/Direction.kt
package enumerations
import atomictest.eq
import enumerations.Direction.*
enum class Direction(val notation: String) {
North("N"), South("S"),
East("E"), West("W"); // 需要分号
val opposite: Direction
get() = when (this) {
North -> South
South -> North
West -> East
East -> West
}
}
fun main() {
North.notation eq "N"
North.opposite eq South
West.opposite.opposite eq West
North.opposite.notation eq "S"
}
Direction类包含一个notation属性,每个实例都持有不同的值。您可以在括号中传递notation构造函数参数的值(例如North("N")),就像构造常规类的实例一样。
opposite属性的getter在访问时动态计算结果。
请注意,此示例中的when不需要else分支,因为所有可能的enum条目都已覆盖。
枚举可以使代码更具可读性,这总是值得提倡的。
Exercises and solutions can be found at www.AtomicKotlin.com.
数据类
Kotlin 减少了重复性的编码工作
class 机制为您执行了大量的工作。然而,创建主要用于保存数据的类仍然需要大量重复的代码。当您需要一个基本上是数据持有者的类时,data 类简化了您的代码并执行常见的任务。
在 Kotlin 中,data 类简化了主要用于保存数据的类的代码,减少了重复性的编码工作。
您可以使用 data 关键字定义一个 data 类,告诉 Kotlin 生成额外的功能。每个构造函数参数前面必须加上 var 或 val:
// DataClasses/Simple.kt
package dataclasses
import atomictest.eq
data class Simple(
val arg1: String,
var arg2: Int
)
fun main() {
val s1 = Simple("Hi", 29)
val s2 = Simple("Hi", 29)
s1 eq "Simple(arg1=Hi, arg2=29)"
s1 eq s2
}
这个例子展示了 data 类的两个特点:
- 通过
s1产生的String与我们通常看到的不同;它包含对象所持有的参数名称和值的信息。data类以一种漂亮、可读的格式显示对象,而无需额外的代码。 - 如果您创建了两个包含相同数据(属性的相等值)的相同
data类的实例,您可能希望这两个实例也相等。对于普通类,要实现这种行为,您必须定义一个特殊的equals()函数来比较实例。在data类中,这个函数会自动生成;它会比较所有指定为构造函数参数的属性的值。
下面是一个普通类 Person 和一个 data 类 Contact 的例子:
// DataClasses/DataClasses.kt
package dataclasses
import atomictest.*
class Person(val name: String)
data class Contact(
val name: String,
val number: String
)
fun main() {
// 这两个看起来是相同的,但实际上不是:
Person("Cleo") neq Person("Cleo")
// data 类定义了合理的相等性:
Contact("Miffy", "1-234-567890") eq
Contact("Miffy", "1-234-567890")
}
/* 输出结果:
dataclasses.Person@54bedef2
Contact(name=Miffy, number=1-234-567890)
*/
因为 Person 类是没有使用 data 关键字定义的,所以包含相同 name 的两个实例并不相等。幸运的是,将 Contact 定义为 data 类会得到合理的结果。
请注意 data 类的显示格式与 Person 的区别,Person 只显示默认的对象信息。
对于每个 data 类,还生成了一个非常有用的函数 copy(),它创建一个包含当前对象数据的新对象。但是,它也允许您在此过程中更改选定的值:
// DataClasses/CopyDataClass.kt
package dataclasses
import atomictest.eq
data class DetailedContact(
val name: String,
val surname: String,
val number: String,
val address: String
)
fun main() {
val contact = DetailedContact(
"Miffy",
"Miller",
"1-234-567890",
"1600 Amphitheatre Parkway")
val newContact = contact.copy(
number = "098-765-4321",
address = "Brandschenkestrasse 110")
newContact eq DetailedContact(
"Miffy",
"Miller",
"098-765-4321",
"Brandschenkestrasse 110")
}
copy() 函数的参数名称与构造函数参数相同。所有参数都有默认值,等于当前值,因此您只需要提供要替换的参数的值。
HashMap 和 HashSet
创建一个 data 类还会生成适当的 哈希函数,以便对象可以用作 HashMap 和 HashSet 中的键:
// DataClasses/HashCode.kt
package dataclasses
import atomictest.eq
data class Key(val name: String, val id: Int)
fun main() {
val korvo: Key = Key("Korvo", 19)
korvo.hashCode() eq -2041757108
val map = HashMap<Key, String>()
map[korvo] = "Alien"
map[korvo] eq "Alien"
val set = HashSet<Key>()
set.add(korvo)
set.contains(korvo) eq true
}
hashCode() 与 equals() 结合使用,快速查找 HashMap 或 HashSet 中的 Key。手动创建正确的 hashCode() 是棘手且容易出错的,因此让 data 类为您完成这项工作非常有益。有关 equals() 和 hashCode() 的更多详细信息,请参阅运算符重载。
在 www.AtomicKotlin.com 上可以找到练习和解答。
解构声明(Destructuring Declarations)
假设您想要从函数返回多个项,例如结果以及有关该结果的一些信息。
Pair 类是标准库的一部分,它允许您返回两个值:
// Destructuring/Pairs.kt
package destructuring
import atomictest.eq
fun compute(input: Int): Pair<Int, String> =
if (input > 5)
Pair(input * 2, "High")
else
Pair(input * 2, "Low")
fun main() {
compute(7) eq Pair(14, "High")
compute(4) eq Pair(8, "Low")
val result = compute(5)
result.first eq 10
result.second eq "Low"
}
我们将 compute() 的返回类型指定为 Pair<Int, String>。Pair 是一个参数化类型,类似于 List 或 Set。
返回多个值很有帮助,但我们还希望有一种方便的方式来解包结果。如上所示,您可以使用 Pair 的 first 和 second 属性访问其组件,但您还可以使用解构声明同时声明和初始化多个标识符:
val (a, b, c) = composedValue
这将解构一个组合值并按位置分配其组件。该语法与定义单个标识符的语法不同 - 对于解构,您将标识符的名称放在括号内。
下面是从 compute() 返回的 Pair 的解构声明:
// Destructuring/PairDestructuring.kt
import destructuring.compute
import atomictest.eq
fun main() {
val (value, description) = compute(7)
value eq 14
description eq "High"
}
Triple 类组合了三个值,但仅限于此。这是有意的:如果您需要存储更多的值,或者发现自己使用了许多 Pair 或 Triple,考虑创建专门的类。
data 类 自动允许解构声明:
// Destructuring/Computation.kt
package destructuring
import atomictest.eq
data class Computation(
val data: Int,
val info: String
)
fun evaluate(input: Int) =
if (input > 5)
Computation(input * 2, "High")
else
Computation(input * 2, "Low")
fun main() {
val (value, description) = evaluate(7)
value eq 14
description eq "High"
}
返回一个 Computation 而不是 Pair<Int, String> 更清晰。选择一个良好的结果名称几乎与为函数本身选择一个良好的自解释名称一样重要。如果是单独的类而不是 Pair,添加或删除 Computation 信息会更简单。
当您解包 data 类的实例时,必须按照与类中属性定义相同的顺序将值分配给新的标识符:
// Destructuring/Tuple.kt
package destructuring
import atomictest.eq
data class Tuple(
val i: Int,
val d: Double,
val s: String,
val b: Boolean,
val l: List<Int>
)
fun main() {
val tuple = Tuple(
1, 3.14, "Mouse", false, listOf())
val (i, d, s, b, l) = tuple
i eq 1
d eq 3.14
s eq "Mouse"
b eq false
l eq listOf()
val (_, _, animal) = tuple // [1]
animal eq "Mouse"
}
- [1] 如果您不需要某些标识符,可以使用下划线代替它们的名称,如果它们位于末尾,则可以完全省略它们。在这里,解构的值
1和3.14使用下划线丢弃,"Mouse"被捕获到animal中,false和空List被丢弃,因为它们位于列表的末尾。
data 类的属性是按顺序分配的,而不是按名称。如果您对对象进行解构并在 data 类的末尾以外的任何位置添加属性,该新属性将在您之前的标识符之上解构,从而产生意外的结果(请参见练习3)。如果自定义的 data 类具有相同类型的属性,编译器无法检测到误用,因此您可能要避免对其进行解构。解构库中的 data 类,如 Pair 或 Triple,是安全的,因为它们不会更改。
使用 for 循环,您可以迭代 Map 或一系列对(或其他 data 类)并对每个元素进行解构:
// Destructuring/ForLoop.kt
import atomictest.eq
fun main() {
var result = ""
val map = mapOf(1 to "one", 2 to "two")
for
((key, value) in map) {
result += "$key = $value, "
}
result eq "1 = one, 2 = two,"
result = ""
val listOfPairs =
listOf(Pair(1, "one"), Pair(2, "two"))
for ((i, s) in listOfPairs) {
result += "($i, $s), "
}
result eq "(1, one), (2, two),"
}
withIndex() 是 List 的标准库扩展函数。它返回 IndexedValue 的集合,可以进行解构:
// Destructuring/LoopWithIndex.kt
import atomictest.trace
fun main() {
val list = listOf('a', 'b', 'c')
for ((index, value) in list.withIndex()) {
trace("$index:$value")
}
trace eq "0:a 1:b 2:c"
}
解构声明仅允许用于局部 var 和 val,不能用于创建类属性。
练习和答案可以在 www.AtomicKotlin.com 找到。
可空类型(Nullable Types)
考虑一个有时会产生“无结果”的函数。当发生这种情况时,函数本身不会产生错误。没有什么出错了,只是“没有答案”。
一个很好的例子是从 Map 中检索值。如果 Map 不包含给定键的值,它不能给您答案,因此返回一个 null 引用来表示“没有值”:
// NullableTypes/NullInMaps.kt
import atomictest.eq
fun main() {
val map = mapOf(0 to "yes", 1 to "no")
map[2] eq null
}
像 Java 这样的语言允许结果既可以是 null,也可以是有意义的值。不幸的是,如果您像对待有意义的值一样对待 null,会导致严重的失败(在 Java 中,这会产生 NullPointerException;在更原始的语言(如 C)中,null 指针可能会导致进程甚至操作系统或机器崩溃)。null 引用的创造者 Tony Hoare 将其称为“我十亿美元的错误”(尽管实际成本可能远远超过这个数字)。
解决此问题的一个可能方法是让语言从一开始就不允许 null,而是引入特殊的“没有值”指示器。Kotlin 可能会这样做,但必须与 Java 进行交互,而 Java 使用 null。
Kotlin 的解决方案可能是最好的折衷方案:类型默认为非可空。但是,如果某个内容可能生成 null 结果,您必须在类型名称后添加问号,以明确标记该结果为可空:
// NullableTypes/NullableTypes.kt
import atomictest.eq
fun main() {
val s1 = "abc" // [1]
// 编译时错误:
// val s2: String = null // [2]
// 可空定义:
val s3: String? = null // [3]
val s4: String? = s1 // [4]
// 编译时错误:
// val s5: String = s4 // [5]
val s6 = s4 // [6]
s1 eq "abc"
s3 eq null
s4 eq "abc"
s6 eq "abc"
}
- [1]
s1不能包含null引用。迄今为止,在本书中我们创建的所有var和val都自动是非可空的。 - [2] 错误消息为:null can not be a value of a non-null type String。
- [3] 要定义一个可以包含
null引用的标识符,需要在类型名称的末尾加上?。这种标识符可以包含null或常规值。 - [4] 可以在可空类型中存储
null和常规非可空值。 - [5] 不能将可空类型的标识符赋值给非可空类型的标识符。Kotlin 会发出:Type mismatch: inferred type is String? but String was expected. 即使实际值在这种情况下是非空的(我们知道它是
"abc"),Kotlin 也不允许,因为它们是两种不同的类型。 - [6] 如果使用类型推断,Kotlin 会生成适当的类型。在这里,
s6是可空的,因为s4是可空的。
即使看起来我们只是在现有类型末尾添加 ? 来修改现有类型,实际上我们正在指定一种不同的类型。例如,String 和 String? 是两种不同的类型。String? 类型禁止了第 [2] 和 [5] 行中的操作,从而保证非可空类型的值永远不会是 null。
使用方括号从 Map 中检索值会产生一个可空结果,因为底层的 Map 实现来自 Java:
// NullableTypes/NullableInMap.kt
import atomictest.eq
fun main() {
val map = mapOf(0 to "yes", 1 to "no")
val first: String? = map[0]
val second: String? = map[2]
first eq "yes"
second eq null
}
为什么知道值不可能是 null 是重要的?许多操作隐式地假设非可空的结果。例如,如果接收方值为 null,则调用成员函数将导致异常。在 Java 中,这样的调用将导致 NullPointerException(通常简称为 NPE)。由于几乎任何值都可以是 null,所以任何函数调用都可能以这种方式失败。在这些情况下,您必须编写代码检查 null 结果,或依赖代码的其他部分来防范 null。
在 Kotlin 中,您不能简单地将可空类型的值解引用(调用成员函数或访问成员属性):
// NullableTypes/Dereference.kt
import atomictest.eq
fun main() {
val s1: String = "abc"
val s2: String? = s1
s1.length eq 3 // [1]
// 不能编译:
// s2.length // [2]
}
您
可以像 [1] 中一样访问非可空类型的成员。如果引用可空类型的成员,就像 [2] 中一样,Kotlin 将会发出错误。
大多数类型的值都存储为对内存中对象的引用。这就是术语解引用的含义——要访问一个对象,您需要从内存中检索它的值。
确保解引用可空类型不会抛出 NullPointerException 的最直接的方法是明确检查引用是否不为 null:
// NullableTypes/ExplicitCheck.kt
import atomictest.eq
fun main() {
val s: String? = "abc"
if (s != null)
s.length eq 3
}
在显式的 if 检查之后,Kotlin 允许您解引用可空类型。但是,在处理可空类型时,每次编写此 if 都会显得太嘈杂。Kotlin 有简洁的语法来缓解这个问题,您将在随后的章节中了解到。
每当创建一个新类时,Kotlin 会自动包含可空类型和非可空类型:
// NullableTypes/Amphibian.kt
package nullabletypes
class Amphibian
enum class Species {
Frog, Toad, Salamander, Caecilian
}
fun main() {
val a1: Amphibian = Amphibian()
val a2: Amphibian? = null
val at1: Species = Species.Toad
val at2: Species? = null
}
正如您所看到的,我们没有特别做什么来产生补充的可空类型——它们默认可用。
练习和答案可以在 www.AtomicKotlin.com 找到。
安全调用和 Elvis 运算符
Kotlin 提供了方便的操作来处理可空性。
可空类型带来了许多限制。您不能简单地解引用可空类型的标识符:
// SafeCallsAndElvis/DereferenceNull.kt
fun main() {
val s: String? = null
// 不能编译:
// s.length // [1]
}
取消 [1] 的注释会产生编译时错误:Only safe (?.) or non-null asserted (!!.) calls are allowed on a nullable receiver of type String?.。
安全调用将常规调用中的点(.)替换为问号和点(?.),中间没有空格。安全调用以确保不会抛出异常的方式访问可空类型的成员。它们仅在接收方不为 null 时执行操作:
// SafeCallsAndElvis/SafeOperation.kt
package safecalls
import atomictest.*
fun String.echo() {
trace(toUpperCase())
trace(this)
trace(toLowerCase())
}
fun main() {
val s1: String? = "Howdy!"
s1?.echo() // [1]
val s2: String? = null
s2?.echo() // [2]
trace eq """
HOWDY!
Howdy!
howdy!
"""
}
[1] 行调用 echo() 并在 trace 中产生结果,而 [2] 行不执行任何操作,因为接收方 s2 是 null。
安全调用是一种捕获结果的简洁方式:
// SafeCallsAndElvis/SafeCall.kt
package safecalls
import atomictest.eq
fun checkLength(s: String?, expected: Int?) {
val length1 =
if (s != null) s.length else null // [1]
val length2 = s?.length // [2]
length1 eq expected
length2 eq expected
}
fun main() {
checkLength("abc", 3)
checkLength(null, null)
}
[2] 行实现了与 [1] 行相同的效果。如果接收方不为 null,它会执行正常的访问(s.length)。如果接收方为 null,它不会执行 s.length 调用(这会导致异常),而是对表达式产生 null。
如果您需要的不仅仅是 ?. 产生的 null,Elvis 运算符 提供了一种替代方法。该运算符是一个问号后跟一个冒号(?:),中间没有空格。它是以音乐家 Elvis Presley 的表情符号命名的,也是 “else-if” 这个词的一种变种(听起来有点像 “Elvis”)。
许多编程语言都提供了与 Kotlin 的 Elvis 运算符执行相同操作的 null 合并运算符。
如果 ?: 左侧的表达式不为 null,则该表达式成为结果。如果左侧表达式 是 null,则 ?: 右侧的表达式成为结果:
// SafeCallsAndElvis/ElvisOperator.kt
import atomictest.eq
fun main() {
val s1: String? = "abc"
(s1 ?: "---") eq "abc"
val s2: String? = null
(s2 ?: "---") eq "---"
}
s1 不为 null,因此 Elvis 运算符将 "abc" 作为结果。由于 s2 是 null,Elvis 运算符产生备用结果 "---"。
Elvis 运算符通常在安全调用之后使用,以生成有意义的值,而不是默认的 null,就像 [2] 中看到的那样:
// SafeCallsAndElvis/ElvisCall.kt
package safecalls
import atomictest.eq
fun checkLength(s: String?, expected: Int) {
val length1 =
if (s != null) s.length else 0 // [1]
val length2 = s?.length ?: 0 // [2]
length1 eq expected
length2 eq expected
}
fun main() {
checkLength("abc", 3)
checkLength(null, 0)
}
这个 checkLength() 函数与上面的 SafeCall.kt 中的函数非常相似。expected 参数的类型现在是非可空的。[1] 和 [2] 在产生 null 代替的位置上产生了零。
当您使用安全调用来链接访问多个成员时,如果任何中间表达式为 null,结果将为 null:
// SafeCallsAndElvis/ChainedCalls.kt
package safecalls
import atomictest.eq
class Person(
val name: String,
var friend: Person? = null
)
fun main() {
val alice = Person("Alice")
alice.friend?.friend?.name eq null // [1]
val bob = Person("Bob")
val charlie = Person("Charlie", bob)
bob.friend = charlie
bob.friend?.friend?.name eq "Bob" // [2]
(alice.friend?.friend?.name
?: "Unknown") eq "Unknown" // [3]
}
当您使用安全调用来链式访问多个成员时,如果任何中间表达式为 null,结果将为 null。
- [1] 属性
alice.friend为null,因此其他调用的返回值都是null。 - [2] 所有中间调用都产生有意义的值。
- [3] 安全调用链之后的 Elvis 运算符提供了一个备用值,如果任何中间元素为
null。
练习和答案可以在 www.AtomicKotlin.com 找到。
非空断言
解决可空类型问题的另一种方法是具有特殊知识,即相关引用不为
null。
要提出这个断言,使用双感叹号 !!,称为非空断言。如果这看起来令人震惊,那是正常的:相信某些东西不能为 null 是大多数与 null 相关的程序故障的根源(其他的故障可能来自于没有意识到 null 可能会发生)。
x!! 的意思是“忘记 x 可能是 null 的事实——我保证它不是 null。” 如果 x 不为 null,则 x!! 产生 x,否则它会抛出异常:
// NonNullAssertions/NonNullAssert.kt
import atomictest.*
fun main() {
var x: String? = "abc"
x!! eq "abc"
x = null
capture {
val s: String = x!!
} eq "NullPointerException"
}
定义 val s: String = x!! 告诉 Kotlin 忽略它认为自己了解的 x 的情况,只是将它赋值给 s,s 是一个非可空引用。幸运的是,有运行时支持,当 x 为 null 时会抛出 NullPointerException。
通常情况下,您不会单独使用 !!,而是与 . 解引用一起使用:
// NonNullAssertions/NonNullAssertCall.kt
import atomictest.eq
fun main() {
val s: String? = "abc"
s!!.length eq 3
}
如果您每行只使用一个非空断言调用,当异常提供行号时,更容易找到故障。
安全调用 ?. 是一个单一的运算符,但非空断言调用由两个运算符组成:非空断言(!!)和解引用(.)。如您在 NonNullAssert.kt 中看到的,您可以单独使用非空断言。
避免使用非空断言,更喜欢使用安全调用或显式检查。非空断言是为了使 Kotlin 与 Java 进行交互而引入的,以及在 Kotlin 不能智能地确保执行必要的检查时的罕见情况。
如果您在代码中经常为同一操作使用非空断言,最好使用一个带有特定断言的单独函数来描述问题。例如,假设您的程序逻辑要求一个特定的键必须存在于 Map 中,并且如果键缺失,则更喜欢抛出异常而不是无声地不做任何操作。与常规方法(方括号)提取值不同,getValue() 在键缺失时会抛出 NoSuchElementException:
// NonNullAssertions/ValueFromMap.kt
import atomictest.*
fun main() {
val map = mapOf(1 to "one")
map[1]!!.toUpperCase() eq "ONE"
map.getValue(1).toUpperCase() eq "ONE"
capture {
map[2]!!.toUpperCase()
} eq "NullPointerException"
capture {
map.getValue(2).toUpperCase()
} eq "NoSuchElementException: " +
"Key 2 is missing in the map."
}
抛出特定的 NoSuchElementException 在出现问题时提供了更有用的详细信息。
- -
最佳实践的代码仅使用安全调用和引发详细异常的特殊函数。只有在绝对必要的情况下才使用非空断言。尽管非空断言是为了支持与 Java 代码的交互而包含的,但与 Java 交互的更好方法,您可以在 附录 B:Java 互操作性 中学习。
练习和答案可以在 www.AtomicKotlin.com 找到。
可空类型的扩展
有时事情并不是看起来的那样。
s?.f() 暗示了 s 是可空的,否则你可以简单地调用 s.f()。类似地,t.f() 看起来似乎是 t 是非空的,因为 Kotlin 不要求使用安全调用或编程检查。然而,t 并不一定是非空的。
Kotlin 标准库提供了 String 的扩展函数,包括:
isNullOrEmpty():检查接收者String是否为null或为空。isNullOrBlank():执行与isNullOrEmpty()相同的检查,并且允许接收者String仅由空白字符组成,包括制表符(\t)和换行符(\n)。
下面是这些函数的基本测试:
// NullableExtensions/StringIsNullOr.kt
import atomictest.eq
fun main() {
val s1: String? = null
s1.isNullOrEmpty() eq true
s1.isNullOrBlank() eq true
val s2 = ""
s2.isNullOrEmpty() eq true
s2.isNullOrBlank() eq true
val s3: String = " \t\n"
s3.isNullOrEmpty() eq false
s3.isNullOrBlank() eq true
}
函数的名称表明它们适用于可空类型。然而,即使 s1 是可空的,您也可以调用 isNullOrEmpty() 或 isNullOrBlank() 而不使用安全调用或显式检查。这是因为这些函数是可空类型 String? 的扩展函数。
我们可以将 isNullOrEmpty() 重写为一个非扩展函数,该函数以可空 String s 作为参数:
// NullableExtensions/NullableParameter.kt
package nullableextensions
import atomictest.eq
fun isNullOrEmpty(s: String?): Boolean =
s == null || s.isEmpty()
fun main() {
isNullOrEmpty(null) eq true
isNullOrEmpty("") eq true
}
由于 s 是可空的,我们明确地检查了 null 或空。表达式 s == null || s.isEmpty() 使用了短路求值:如果表达式的第一部分是 true,则不会评估表达式的其余部分,从而防止了 null 指针异常。
扩展函数使用 this 来表示接收者(被扩展类型的对象)。为了使接收者可空,将 ? 添加到被扩展类型的类型中:
// NullableExtensions/NullableExtension.kt
package nullableextensions
import atomictest.eq
fun String?.isNullOrEmpty(): Boolean =
this == null || isEmpty()
fun main() {
"".isNullOrEmpty() eq true
}
isNullOrEmpty() 作为扩展函数更易读。
- -
在使用可空类型的扩展时要小心。它们非常适用于简单的情况,例如 isNullOrEmpty() 和 isNullOrBlank(),尤其是使用表达接收者可能是 null 的自我解释性名称。一般来说,最好声明常规(非可空)的扩展。安全调用和显式检查可以澄清接收者的可空性,而针对可空类型的扩展可能会隐藏可空性,令代码的读者(可能是“未来的你”)困惑。
练习和答案可以在 www.AtomicKotlin.com 找到。
泛型入门
泛型创建参数化类型:在多个类型之间工作的组件。
术语“泛型”意味着“与大量类有关或适用的”。编程语言中泛型的最初目的是通过放松对那些类或函数的类型约束,为程序员在编写类或函数时提供最大的表达能力。
泛型最令人信服的最初动机之一是创建集合类,您已经在本书中的示例中看到了这些集合类,例如 List、Set 和 Map。集合是保存其他对象的对象。许多程序需要您在使用这些对象时将它们保存在一组对象中,因此集合是最可重用的类库之一。
让我们来看一个保存单个对象的类。该类指定该对象的确切类型:
// IntroGenerics/RigidHolder.kt
package introgenerics
import atomictest.eq
data class Automobile(val brand: String)
class RigidHolder(private val a: Automobile) {
fun getValue() = a
}
fun main() {
val holder = RigidHolder(Automobile("BMW"))
holder.getValue() eq
"Automobile(brand=BMW)"
}
RigidHolder 不是一个特别可重用的工具;它只能保存 Automobile。我们不希望为每种不同的类型编写一个新的持有者类型。为了实现这一点,我们使用 类型参数 代替 Automobile。
要定义一个泛型类型,请在类名之后添加包含一个或多个泛型占位符的尖括号(<>),并将这个泛型规范放在类名之后。在这里,泛型占位符 T 代表未知类型,并在类内部使用,就像它是普通类型一样:
// IntroGenerics/GenericHolder.kt
package introgenerics
import atomictest.eq
class GenericHolder<T>( // [1]
private val value: T
) {
fun getValue(): T = value
}
fun main() {
val h1 = GenericHolder(Automobile("Ford"))
val a: Automobile = h1.getValue() // [2]
a eq "Automobile(brand=Ford)"
val h2 = GenericHolder(1)
val i: Int = h2.getValue() // [3]
i eq 1
val h3 = GenericHolder("Chartreuse")
val s: String = h3.getValue() // [4]
s eq "Chartreuse"
}
- [1]
GenericHolder存储一个T,它的成员函数getValue()返回一个T。
当您调用 getValue(),如 [2]、[3] 或 [4] 所示,结果会自动是正确的类型。
看起来我们可以使用“通用类型”来解决这个问题,即一个作为所有其他类型的父类的类型。在 Kotlin 中,这个通用类型称为 Any。正如其名称所示,Any 允许任何类型的参数。如果要将多种类型的参数传递给一个函数,而这些类型之间没有任何共同之处,Any 可以解决这个问题。
乍一看,似乎我们可以在 GenericHolder.kt 中使用 Any 替代 T 来解决这个问题:
// IntroGenerics/AnyInstead.kt
package introgenerics
import atomictest.eq
class AnyHolder(private val value: Any) {
fun getValue(): Any = value
}
class Dog {
fun bark() = "Ruff!"
}
fun main() {
val holder = AnyHolder(Dog())
val any = holder.getValue()
// 不编译:
// any.bark()
val genericHolder = GenericHolder(Dog())
val dog = genericHolder.getValue()
dog.bark() eq "Ruff!"
}
实际上,Any 对于简单的情况确实有效,但是一旦我们需要特定的类型——调用 Dog 的 bark() 方法时,它就不起作用了,因为当它被分配给 Any 时,我们失去了它是 Dog 的事实。当我们将 Dog 传递为 Any 时,结果只是一个 Any,它没有 bark() 方法。
使用泛型保留了这个信息,在这种情况下,我们实际上有一个 Dog,这意味着我们可以对 getValue() 返回的对象执行 Dog 操作。
泛型函数
要定义一个泛型函数,请在函数名之前的尖括号中指定一个泛型类型参数:
// IntroGenerics/GenericFunction.kt
package introgenerics
import atomictest.eq
fun <T> identity(arg: T): T = arg
fun main() {
identity("Yellow") eq "Yellow"
identity(1) eq 1
val d: Dog = identity(Dog())
d.bark() eq "Ruff!"
}
d 的类型为 Dog,因为 identity() 是一个泛型函数,并返回一个 T。
Kotlin 标准库包含许多用于集合的泛型扩展函数。要编写一个泛型扩展函数,请将泛型规范放在接收者之前。例如,注意 first() 和 firstOrNull() 是如何定义的:
// IntroGenerics/GenericListExtensions.kt
package introgenerics
import atomictest.eq
fun <T> List<T>.first(): T {
if (isEmpty())
throw NoSuchElementException("Empty List")
return this[0]
}
fun <T> List<T>.firstOrNull(): T
? =
if (isEmpty()) null else this[0]
fun main() {
listOf(1, 2, 3).first() eq 1
val i: Int? = // [1]
listOf(1, 2, 3).firstOrNull()
i eq 1
val s: String? = // [2]
listOf<String>().firstOrNull()
s eq null
}
first() 和 firstOrNull() 可以与任何类型的 List 一起工作。为了返回一个 T,它们必须是泛型函数。
注意,firstOrNull() 指定了一个可空的返回类型。[1] 行显示,在 List<Int> 上调用该函数返回可空类型 Int?。[2] 行显示,在 List<String> 上调用 firstOrNull() 返回 String?。Kotlin 要求在 [1] 和 [2] 行上使用 ?,去掉它们并查看错误消息。
练习和答案可以在 www.AtomicKotlin.com 找到。
扩展属性
就像函数可以是扩展函数一样,属性也可以是扩展属性。
扩展属性的接收器类型规范与扩展函数的语法类似——扩展的类型直接放在函数或属性名称之前:
fun ReceiverType.extensionFunction() { ... }
val ReceiverType.extensionProperty: PropType
get() { ... }
扩展属性需要一个自定义的 getter。每次访问时计算属性值:
// ExtensionProperties/StringIndices.kt
package extensionproperties
import atomictest.eq
val String.indices: IntRange
get() = 0 until length
fun main() {
"abc".indices eq 0..2
}
虽然你可以将没有参数的任何扩展函数转换为属性,但我们建议先考虑一下。在选择属性和函数之间的原因,Property Accessors中描述的原因也适用于扩展属性。只有当属性足够简单且提高了可读性时,才会优先选择属性而不是函数。
您可以定义一个通用的扩展属性。在这里,我们将 Introduction to Generics 中的 firstOrNull() 转换为扩展属性:
// ExtensionProperties/GenericListExt.kt
package extensionproperties
import atomictest.eq
val <T> List<T>.firstOrNull: T?
get() = if (isEmpty()) null else this[0]
fun main() {
listOf(1, 2, 3).firstOrNull eq 1
listOf<String>().firstOrNull eq null
}
Kotlin 样式指南 建议在函数抛出异常时使用函数而不是属性。
当没有使用泛型参数类型时,您可以将其替换为 *。这称为星投影:
// ExtensionProperties/ListOfStar.kt
package extensionproperties
import atomictest.eq
val List<*>.indices: IntRange
get() = 0 until size
fun main() {
listOf(1).indices eq 0..0
listOf('a', 'b', 'c', 'd').indices eq 0..3
emptyList<Int>().indices eq IntRange.EMPTY
}
当使用 List<*> 时,您失去了关于 List 中包含的类型的所有具体信息。例如,List<*> 中的元素只能分配给 Any?:
// ExtensionProperties/AnyFromListOfStar.kt
import atomictest.eq
fun main() {
val list: List<*> = listOf(1, 2)
val any: Any? = list[0]
any eq 1
}
我们不知道存储在 List<*> 中的值是否可为空,这就是为什么它只能分配给可为空的 Any? 类型。
练习和答案可以在 www.AtomicKotlin.com 找到。
break 和 continue
break和continue允许你在循环内部进行“跳转”。
早期的程序员直接编写处理器,使用数字 操作码 作为指令,或者使用 汇编语言,它可以翻译成操作码。这种类型的编程是最底层的。例如,许多编码决策通过在代码中直接“跳转”到其他地方来实现。早期的高级语言(包括 FORTRAN、ALGOL、Pascal、C 和 C++)通过实现 goto 关键字来复制这种做法。
goto 使得从汇编语言转向高级语言的程序员更加舒适。然而,随着我们积累了更多经验,编程社区发现无条件跳转会产生复杂和难以维护的代码。这对 goto 产生了很大的反感,大多数后来的语言都避免了任何形式的无条件跳转。
Kotlin 提供了一种受限制的跳转,即 break 和 continue。这些与循环结构 for、while 和 do-while 相关联,你只能在这些循环内部使用 break 和 continue。此外,continue 只能跳转到循环的开始处,break 只能跳转到循环的结束处。
实际上,在编写新的 Kotlin 代码时,很少使用 break 和 continue。这些特性是早期语言的产物。尽管它们偶尔会有用,但在本书中,您将了解到 Kotlin 提供了更优越的机制。
这里有一个包含 continue 和 break 的 for 循环的示例:
// BreakAndContinue/ForControl.kt
import atomictest.eq
fun main() {
val nums = mutableListOf(0)
for (i in 4 until 100 step 4) { // [1]
if (i == 8) continue // [2]
if (i == 40) break // [3]
nums.add(i)
} // [4]
nums eq "[0, 4, 12, 16, 20, 24, 28, 32, 36]"
}
示例将 Int 聚合到可变的 List 中。在 [2] 处的 continue 跳回循环的开始,即 [1] 处的大括号。它在下一次循环迭代开始时“继续”执行。请注意,在 for 循环体中 continue 后面的代码不会被执行:当 i == 8 时不会调用 nums.add(i),因此在结果 nums 中看不到它。
当 i == 40 时,[3] 处的 break 被执行,通过跳转到其作用域的结尾处([4] 处)“跳出”了 for 循环。以 40 开头的数字不会被添加到最终的 List 中,因为 for 循环停止执行。
第 [2] 行和 [3] 行是可以互换的,因为它们的逻辑没有重叠。尝试交换这两行并验证输出是否不会更改。
我们可以使用 while 循环重写 ForControl.kt:
// BreakAndContinue/WhileControl.kt
import atomictest.eq
fun main() {
val nums = mutableListOf(0)
var i = 0
while (i < 100) {
i += 4
if (i == 8) continue
if (i == 40) break
nums.add(i)
}
nums eq "[0, 4, 12, 16, 20, 24, 28, 32, 36]"
}
break 和 continue 的行为保持不变,就像 do-while 循环一样:
// BreakAndContinue/DoWhileControl.kt
import atomictest.eq
fun main() {
val nums = mutableListOf(0)
var i = 0
do {
i += 4
if (i == 8) continue
if (i == 40) break
nums.add(i)
} while (i < 100)
nums eq "[0, 4, 12, 16, 20, 24, 28, 32, 36]"
}
do-while 循环总是至少执行一次,因为 while 测试位于循环的末尾。
标签
普通的 break 和 continue 只能跳转到其本地循环的边界。标签 允许 break 和 continue 跳转到包围循环的边界,因此您不仅局限于当前循环的范围。
您可以使用 label@ 创建标签,其中 label 可以是任何名称。在这里,标签是 outer:
// BreakAndContinue/ForLabeled.kt
import atomictest.eq
fun main() {
val strings = mutableListOf<String>()
outer@ for (c in 'a'..'e') {
for (i in 1..9) {
if (i == 5) continue@outer
if ("$c$i" == "c3") break@outer
strings.add("$c$i")
}
}
strings eq listOf("a1", "a2", "a3", "a4",
"b1", "b2", "b3", "b4", "c1", "c2")
}
带有标签的 continue 表达式 continue@outer 返回到标签 outer@。带有标签的 break 表达式 break@outer 找到了名为 outer@ 的块的结尾,并从那里继续执行。
标签适用于 while 和 do-while:
// BreakAndContinue/WhileLabeled.kt
import atomictest.eq
fun main() {
val strings = mutableListOf<String>()
var c = 'a' - 1
outer@ while (c < 'f') {
c += 1
var i = 0
do {
i++
if (i == 5) continue@outer
if ("$c$i" == "c3") break@outer
strings.add("$c$i")
} while (i < 10)
}
strings eq listOf("a1", "a2", "a3", "a4",
"b1", "b2", "b3", "b4", "c1", "c2")
}
WhileLabeled.kt 可以重写为:
// BreakAndContinue/Improved.kt
import atomictest.eq
fun main() {
val strings = mutableListOf<String>()
for (c in 'a'..'c') {
for (i in 1..4) {
val value = "$c$i"
if (value < "c3") { // [1]
strings.add(value)
}
}
}
strings eq listOf("a1", "a2", "a3", "a4",
"b1", "b2", "b3", "b4", "c1", "c2")
}
这种写法更加易于理解。在第 [1] 行,我们只添加(按字母顺序)位于 "c3" 之前的 String。这与在先前版本的示例中到达 "c3" 时使用 break 的行为相同。
- -
break 和 continue 往往会创建复杂且难以维护的代码。虽然这些跳转比“goto”更文明,但它们仍然会中断程序流程。没有跳转的代码几乎总是更容易理解的。
在某些情况下,您可以显式地编写迭代的条件,而不是使用 break 和 continue,就像我们在上面的示例中所做的那样。在其他情况下,您可以重构代码并引入新的函数。如果您将整个循环或循环体提取到新的函数中,则可以用 return 替代 break 和 continue。在接下来的部分 函数式编程 中,您将学会编写清晰的代码,而无需使用 break 和 continue。
考虑替代方法,并选择更简单和更易读的解决方案。这通常不会包括 break 和 continue。
练习和解答可在 www.AtomicKotlin.com 找到。
第四部分:函数式编程
“可靠性的不可避免代价就是简单性。” — C.A.R. Hoare
Lambdas(Lambda 表达式)
Lambda 表达式生成更简洁、更易于理解的代码。
Lambda(也称为函数字面值)是一个低仪式性的函数:它没有名称,需要最少的代码来创建,并且您可以将其直接插入到其他代码中。
首先,考虑一下 map(),它适用于像 List 这样的集合。map() 的参数是一个转换函数,该函数应用于集合中的每个元素。map() 返回一个包含所有转换后元素的新的 List。在这里,我们将每个 List 项转换为一个用 [] 括起来的 String:
// Lambdas/BasicLambda.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
val result = list.map({ n: Int -> "[$n]" })
result eq listOf("[1]", "[2]", "[3]", "[4]")
}
Lambda 是初始化 result 时大括号内的代码。参数列表与函数体由箭头 ->(与 when 表达式中使用的箭头相同)分隔。
函数体可以是一个或多个表达式。最后一个表达式成为 lambda 的返回值。
BasicLambda.kt 显示了完整的 lambda 语法,但通常可以简化。我们通常会在需要时创建和使用 lambda,这意味着 Kotlin 通常可以推断出类型信息。在这里,n 的类型是被推断出来的:
// Lambdas/LambdaTypeInference.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
val result = list.map({ n -> "[$n]" })
result eq listOf("[1]", "[2]", "[3]", "[4]")
}
Kotlin 可以判断出 n 是一个 Int,因为 lambda 正在与 List<Int> 一起使用。
如果只有一个参数,Kotlin 会为该参数生成名为 it 的名称,这意味着我们不再需要 n ->:
// Lambdas/LambdaIt.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
val result = list.map({ "[$it]" })
result eq listOf("[1]", "[2]", "[3]", "[4]")
}
map() 可以处理任何类型的 List。在这里,Kotlin 推断出 lambda 参数 it 的类型为 Char:
// Lambdas/Mapping.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'd')
val result =
list.map({ "[${it.toUpperCase()}]" })
result eq listOf("[A]", "[B]", "[C]", "[D]")
}
如果 lambda 是唯一的函数参数,或者是最后一个参数,您可以省略大括号周围的括号,从而产生更简洁的语法:
// Lambdas/OmittingParentheses.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'd')
val result =
list.map { "[${it.toUpperCase()}]" }
result eq listOf("[A]", "[B]", "[C]", "[D]")
}
如果函数接受多个参数,则除最后一个 lambda 参数外,所有参数都必须位于括号内。例如,您可以将 joinToString() 的最后一个参数指定为 lambda。该 lambda 用于将每个元素转换为 String,然后将所有元素连接起来:
// Lambdas/JoinToString.kt
import atomictest.eq
fun main() {
val list = listOf(9, 11, 23, 32)
list.joinToString(" ") { "[$it]" } eq
"[9] [11] [23] [32]"
}
如果要将 lambda 提供为命名参数,必须将 lambda 放在参数列表的括号内:
// Lambdas/LambdaAndNamedArgs.kt
import atomictest.eq
fun main() {
val list = listOf(9, 11, 23, 32)
list.joinToString(
separator = " ",
transform = { "[$it]" }
) eq "[9] [11] [23] [32]"
}
以下是带有多个参数的 lambda 的语法:
// Lambdas/TwoArgLambda.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c')
list.mapIndexed { index, element ->
"[$index: $element]"
} eq listOf("[0: a]", "[1: b]", "[2: c]")
}
这使用了 mapIndexed() 库函数,它将 list 中的每个元素与该元素的索引一起传递。我们在 mapIndexed() 之后应用的 lambda 需要两个参数,以匹配索引和元素(在 List<Char> 的情况下,元素是一个字符)。
如果您不使用特定的参数,您可以使用下划线来忽略它,以消除关于未使用标识符的编译器警告:
// Lambdas/Underscore.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c')
list.mapIndexed { index, _ ->
"[$index]"
} eq listOf("[0]", "[1]", "[2]")
}
请注意,可以使用 list.indices 重写 Underscore.kt:
// Lambdas/ListIndicesMap.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c')
list.indices.map {
"[$it]"
} eq listOf("[0]", "[1]", "[2]")
}
Lambda 可以具有零个参数,此时您可以保留箭头以强调,但 Kotlin 风格指南建议省略箭头:
// Lambdas/ZeroArguments
.kt
import atomictest.*
fun main() {
run { -> trace("A Lambda") }
run { trace("Without args") }
trace eq """
A Lambda
Without args
"""
}
标准库的 run() 函数只是调用其 lambda 参数。
- -
您可以在任何使用普通函数的地方使用 lambda,但如果 lambda 变得过于复杂,通常最好定义一个命名函数,以便清晰明了,即使您只打算使用一次。
练习和解答可在 www.AtomicKotlin.com 找到。
Lambdas的重要性
Lambdas可能看起来只是语法糖,但它们为你的编程提供了重要的能力。
代码经常会操作集合的内容,并且通常会以轻微的修改重复执行这些操作。考虑从集合中选择元素,例如年龄在给定值以下的人、具有特定角色的员工、特定城市的居民或未完成的订单。以下是一个从列表中选择偶数的示例。假设我们没有一个丰富的用于处理集合的函数库 - 我们将不得不实现自己的filterEven()操作:
// ImportanceOfLambdas/FilterEven.kt
package importanceoflambdas
import atomictest.eq
fun filterEven(nums: List<Int>): List<Int> {
val result = mutableListOf<Int>()
for (i in nums) {
if (i % 2 == 0) { // [1]
result += i
}
}
return result
}
fun main() {
filterEven(listOf(1, 2, 3, 4)) eq
listOf(2, 4)
}
如果一个元素除以2的余数为0,它将附加到结果中。
想象一下,你需要类似的操作,但是针对大于2的数字。你可以复制filterEven()并修改选择包含在结果中的元素的小部分:
// ImportanceOfLambdas/GreaterThan2.kt
package importanceoflambdas
import atomictest.eq
fun greaterThan2(nums: List<Int>): List<Int> {
val result = mutableListOf<Int>()
for (i in nums) {
if (i > 2) { // [1]
result += i
}
}
return result
}
fun main() {
greaterThan2(listOf(1, 2, 3, 4)) eq
listOf(3, 4)
}
前两个示例之间唯一显著的区别是指定所需元素的代码行(在两种情况下均为**[1]**)。
使用Lambda,我们可以在两种情况下使用相同的函数。标准库函数filter()接受一个谓词,指定要保留的元素,这个谓词可以是Lambda:
// ImportanceOfLambdas/Filter.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
val even = list.filter { it % 2 == 0 }
val greaterThan2 = list.filter { it > 2 }
even eq listOf(2, 4)
greaterThan2 eq listOf(3, 4)
}
现在,我们有了清晰、简洁的代码,避免了重复。even和greaterThan2都使用了filter(),只有谓词不同。filter()经过了大量测试,因此不太可能引入错误。
注意,filter()处理了否则需要手写代码的迭代。尽管自己管理迭代可能不会显得很费力,但这是一个更容易出错的细节,也是一个更容易出错的地方。因为它们非常“显而易见”,所以这些错误尤其难以发现。
这是函数式编程的一个标志,其中map()和filter()就是示例。函数式编程通过一步步解决问题。这些函数通常执行看起来微不足道的操作 - 编写自己的代码而不是使用map()和filter()并不难。然而,一旦你拥有了这些小而经过调试的解决方案的集合,你可以在不在每个级别都进行调试的情况下轻松地将它们组合起来。这使你能够更快地创建更加健壮的代码。
你可以将Lambda存储在var或val中。这允许通过将其作为参数传递给不同的函数来重用该Lambda的逻辑:
// ImportanceOfLambdas/StoringLambda.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
val isEven = { e: Int -> e % 2 == 0 }
list.filter(isEven) eq listOf(2, 4)
list.any(isEven) eq true
}
isEven检查一个数字是否为偶数,并将此引用作为参数传递给filter()和any()。在定义isEven时,我们必须指定参数类型,因为没有类型推断的上下文。
Lambda的另一个重要特性是能够引用其作用域之外的元素。当一个函数在其环境中“闭合”或“捕获”元素时,我们将其称为闭包。不幸的是,一些语言将“闭包”一词与Lambda的概念混为一谈。这两个概念完全不同:你可以有没有闭包的Lambda,也可以有没有Lambda的闭包。
当一种语言支持闭包时,它会以你期望的方式“正常工作”:
// ImportanceOfLambdas/Closures.kt
import atomictest.eq
fun main() {
val list = listOf(1, 5, 7, 10)
val divider = 5
list.filter { it % divider == 0 } eq
listOf(5, 10)
}
在这里,Lambda“捕获”了在Lambda之外定义的val divider。Lambda不仅可以读取捕获的元素,还可以修改它们:
// ImportanceOfLambdas/Closures2.kt
import atomictest.eq
fun main() {
val list = listOf(1, 5, 7, 10)
var sum = 0
val divider = 5
list.filter { it % divider == 0 }
.forEach {
sum += it }
sum eq 15
}
forEach()库函数将指定的操作应用于集合的每个元素。
尽管你可以像Closures2.kt中那样捕获可变变量sum,但通常你可以改变代码,避免修改环境的状态:
// ImportanceOfLambdas/Sum.kt
import atomictest.eq
fun main() {
val list = listOf(1, 5, 7, 10)
val divider = 5
list.filter { it % divider == 0 }
.sum() eq 15
}
sum()适用于数字列表,将列表中的所有元素相加。
普通函数也可以闭合周围的元素:
// ImportanceOfLambdas/FunctionClosure.kt
package importanceoflambdas
import atomictest.eq
var x = 100
fun useX() {
x++
}
fun main() {
useX()
x eq 101
}
useX()从其环境中捕获并修改x。
练习和解答可以在 www.AtomicKotlin.com 找到。
集合操作
函数式编程语言的一个重要特性是能够轻松地对对象的集合执行批量操作。
大多数函数式编程语言都提供了强大的集合处理功能,Kotlin也不例外。你已经见过map()、filter()、any()和forEach()。这个小节介绍了List和其他集合类型可用的其他操作。
我们首先来看看不同的方法来创建List。这里,我们使用Lambda来初始化List:
// OperationsOnCollections/CreatingLists.kt
import atomictest.eq
fun main() {
// Lambda参数是元素的索引:
val list1 = List(10) { it }
list1 eq "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]"
// 单一值的列表:
val list2 = List(10) { 0 }
list2 eq "[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]"
// 字母列表:
val list3 = List(10) { 'a' + it }
list3 eq "[a, b, c, d, e, f, g, h, i, j]"
// 循环遍历一个序列:
val list4 = List(10) { list3[it % 3] }
list4 eq "[a, b, c, a, b, c, a, b, c, a]"
}
这个版本的List构造函数有两个参数:List的大小和一个初始化每个List元素的Lambda(元素索引作为it参数传递)。记住,如果Lambda是最后一个参数,它可以与参数列表分开。
MutableList可以以同样的方式进行初始化。在这里,我们可以看到初始化的Lambda既在参数列表内部(mutableList1),也与参数列表分开(mutableList2):
// OperationsOnCollections/ListInit.kt
import atomictest.eq
fun main() {
val mutableList1 =
MutableList(5, { 10 * (it + 1) })
mutableList1 eq "[10, 20, 30, 40, 50]"
val mutableList2 =
MutableList(5) { 10 * (it + 1) }
mutableList2 eq "[10, 20, 30, 40, 50]"
}
请注意,List()和MutableList()不是构造函数,而是函数。它们的名称故意以大写字母开头,以使它们看起来像构造函数。
许多集合函数采用谓词,并将其与集合的元素进行测试,其中一些我们已经见过:
filter()生成一个包含与给定谓词匹配的所有元素的列表。any()如果至少有一个元素与谓词匹配,则返回true。all()检查是否所有元素都与谓词匹配。none()检查是否没有元素与谓词匹配。find()和firstOrNull()都返回与谓词匹配的第一个元素,如果没有找到此类元素则返回null。lastOrNull()返回与谓词匹配的最后一个元素,或者null。count()返回与谓词匹配的元素数量。
以下是每个函数的简单示例:
// OperationsOnCollections/Predicates.kt
import atomictest.eq
fun main() {
val list = listOf(-3, -1, 5, 7, 10)
list.filter { it > 0 } eq listOf(5, 7, 10)
list.count { it > 0 } eq 3
list.find { it > 0 } eq 5
list.firstOrNull { it > 0 } eq 5
list.lastOrNull { it < 0 } eq -1
list.any { it > 0 } eq true
list.any { it != 0 } eq true
list.all { it > 0 } eq false
list.all { it != 0 } eq true
list.none { it > 0 } eq false
list.none { it == 0 } eq true
}
filter() 和 count() 对每个元素应用谓词,而 any() 或 find() 在找到第一个匹配结果时停止。例如,如果第一个元素满足谓词,any()会立即返回true,而find()会返回第一个匹配的元素。只有当列表中不包含与给定谓词匹配的元素时,所有元素都会被处理。
filter() 返回满足给定谓词的一组元素。有时您可能对剩余的组感兴趣 - 即不满足谓词的元素。filterNot() 会产生这个剩余的组,但是partition() 可能更有用,因为它同时生成了这两个列表:
// OperationsOnCollections/Partition.kt
import atomictest.eq
fun main() {
val list = listOf(-3, -1, 5, 7, 10)
val isPositive = { i: Int -> i > 0 }
list.filter(isPositive) eq "[5, 7, 10]"
list.filterNot(isPositive) eq "[-3, -1]"
val (pos, neg) = list.partition { it > 0 }
pos eq "[5, 7, 10]"
neg eq "[-3, -1]"
}
partition() 产生一个包含 List 的 Pair 对象。使用Destructuring Declarations,您可以将 Pair 的元素分配给用括号括起的 var 或 val 组。Destructuring 是指同时定义多个 var 或 val 并从赋值的右侧表达式进行初始化。在这里,析构用于自定义函数:
// OperationsOnCollections/PairOfLists.kt
package operationsoncollections
import atomictest.eq
fun createPair() = Pair(1, "one")
fun main() {
val (i, s) = createPair()
i eq 1
s eq "one"
}
filterNotNull() 生成一个移除了 null 的新的 List:
// OperationsOnCollections/FilterNotNull.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, null)
list.filterNotNull() eq "[1, 2]"
}
在Lists中,我们看到了一些应用于可比较元素列表的函数,比如sum()或sorted()。这些函数不能应用于非可加或非可比元素的列表,但它们有名为sumBy()和sortedBy()的对应函数。您将一个函数(通常是一个Lambda)作为参数传递,该函数指定用于操作的属性:
// OperationsOnCollections/ByOperations.kt
package operationsoncollections
import atomictest.eq
data class Product(
val description: String,
val price: Double
)
fun main() {
val products = listOf(
Product("bread", 2.0),
Product("wine", 5.0)
)
products.sumByDouble { it.price } eq 7.0
products.sortedByDescending { it.price } eq
"[Product(description=wine, price=5.0)," +
" Product(description=bread, price=2.0)]"
products.minByOrNull { it.price } eq
Product("bread", 2.0)
}
请注意,我们有两个函数sumBy()和sumByDouble(),分别用于对整数值和双精度值进行求和。sorted()和sortedBy()对集合进行升序排序,而sortedDescending()和sortedByDescending()对集合进行降序排序。
minByOrNull基于给定的条件返回一个最小值,如果列表为空,则返回null。
take()和drop()分别产生或移除第一个元素,而takeLast()和dropLast()分别产生或移除最后一个元素。这些函数还有接受谓词的对应函数,用于指定要获取或删除的元素:
// OperationsOnCollections/TakeOrDrop.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'X', 'Z')
list.takeLast(3) eq "[c, X, Z]"
list.takeLastWhile { it.isUpperCase() } eq
"[X, Z]"
list.drop(1) eq "[b, c, X, Z]"
list.dropWhile { it.isLowerCase() } eq
"[X, Z]"
}
与您在List中看到的操作一样,也可以在Set上进行操作:
// OperationsOnCollections/SetOperations.kt
import atomictest.eq
fun main() {
val set = setOf("a", "ab", "ac")
set.maxByOrNull { it.length }?.length eq 2
set.filter {
it.contains('b')
} eq listOf("ab")
set.map { it.length } eq listOf(1, 2, 2)
}
maxByOrNull() 如果集合为空,则返回null,因此其结果是可空的。
请注意,将filter()和map()应用于Set时,它们将其结果返回为List。
filter() 返回满足给定谓词的一组元素。有时您可能对剩余的组感兴趣 - 即不满足谓词的元素。filterNot() 会产生这个剩余的组,但是partition() 可能更有用,因为它同时生成了这两个列表:
// OperationsOnCollections/Partition.kt
import atomictest.eq
fun main() {
val list = listOf(-3, -1, 5, 7, 10)
val isPositive = { i: Int -> i > 0 }
list.filter(isPositive) eq "[5, 7, 10]"
list.filterNot(isPositive) eq "[-3, -1]"
val (pos, neg) = list.partition { it > 0 }
pos eq "[5, 7, 10]"
neg eq "[-3, -1]"
}
partition() 产生一个包含 List 的 Pair 对象。使用Destructuring Declarations,您可以将 Pair 的元素分配给用括号括起的 var 或 val 组。Destructuring 是指同时定义多个 var 或 val 并从赋值的右侧表达式进行初始化。在这里,析构用于自定义函数:
// OperationsOnCollections/PairOfLists.kt
package operationsoncollections
import atomictest.eq
fun createPair() = Pair(1, "one")
fun main() {
val (i, s) = createPair()
i eq 1
s eq "one"
}
filterNotNull() 生成一个移除了 null 的新的 List:
// OperationsOnCollections/FilterNotNull.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, null)
list.filterNotNull() eq "[1, 2]"
}
在Lists中,我们看到了一些应用于可比较元素列表的函数,比如sum()或sorted()。这些函数不能应用于非可加或非可比元素的列表,但它们有名为sumBy()和sortedBy()的对应函数。您将一个函数(通常是一个Lambda)作为参数传递,该函数指定用于操作的属性:
// OperationsOnCollections/ByOperations.kt
package operationsoncollections
import atomictest.eq
data class Product(
val description: String,
val price: Double
)
fun main() {
val products = listOf(
Product("bread", 2.0),
Product("wine", 5.0)
)
products.sumByDouble { it.price } eq 7.0
products.sortedByDescending { it.price } eq
"[Product(description=wine, price=5.0)," +
" Product(description=bread, price=2.0)]"
products.minByOrNull { it.price } eq
Product("bread", 2.0)
}
请注意,我们有两个函数sumBy()和sumByDouble(),分别用于对整数值和双精度值进行求和。sorted()和sortedBy()对集合进行升序排序,而sortedDescending()和sortedByDescending()对集合进行降序排序。
minByOrNull基于给定的条件返回一个最小值,如果列表为空,则返回null。
take()和drop()分别产生或移除第一个元素,而takeLast()和dropLast()分别产生或移除最后一个元素。这些函数还有接受谓词的对应函数,用于指定要获取或删除的元素:
// OperationsOnCollections/TakeOrDrop.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'X', 'Z')
list.takeLast(3) eq "[c, X, Z]"
list.takeLastWhile { it.isUpperCase() } eq
"[X, Z]"
list.drop(1) eq "[b, c, X, Z]"
list.dropWhile { it.isLowerCase() } eq
"[X, Z]"
}
与您在List中看到的操作一样,也可以在Set上进行操作:
// OperationsOnCollections/SetOperations.kt
import atomictest.eq
fun main() {
val set = setOf("a", "ab", "ac")
set.maxByOrNull { it.length }?.length eq 2
set.filter {
it.contains('b')
} eq listOf("ab")
set.map { it.length } eq listOf(1, 2, 2)
}
maxByOrNull() 如果集合为空,则返回null,因此其结果是可空的。
请注意,将filter()和map()应用于Set时,它们将其结果返回为List。
练习和解答可以在 www.AtomicKotlin.com 找到。
成员引用
您可以将成员引用作为函数参数传递。
对于函数、属性和构造函数,成员引用 可以替换只是调用相应函数、属性或构造函数的平凡 Lambda。
成员引用使用双冒号将类名与函数或属性分隔开。在这里,Message::isRead 是一个成员引用:
// MemberReferences/PropertyReference.kt
package memberreferences1
import atomictest.eq
data class Message(
val sender: String,
val text: String,
val isRead: Boolean
)
fun main() {
val messages = listOf(
Message("Kitty", "Hey!", true),
Message("Kitty", "Where are you?", false))
val unread =
messages.filterNot(Message::isRead)
unread.size eq 1
unread.single().text eq "Where are you?"
}
要筛选未读消息,我们使用库函数 filterNot(),该函数接受谓词。在我们的情况下,谓词指示消息是否已读。我们可以传递一个 Lambda,但我们传递属性引用 Message::isRead。
当指定非平凡的排序顺序时,属性引用非常有用:
// MemberReferences/SortWith.kt
import memberreferences1.Message
import atomictest.eq
fun main() {
val messages = listOf(
Message("Kitty", "Hey!", true),
Message("Kitty", "Where are you?", false),
Message("Boss", "Meeting today", false))
messages.sortedWith(compareBy(
Message::isRead, Message::sender)) eq
listOf(
// 首先是未读消息,按发送者排序:
Message("Boss", "Meeting today", false),
Message("Kitty",
"Where are you?", false),
// 然后是已读消息,也按发送者排序:
Message("Kitty", "Hey!", true))
}
库函数 sortedWith() 使用比较器对列表进行排序,比较器是用于比较两个元素的对象。库函数 compareBy() 基于其参数构建比较器,参数是一系列的谓词。使用具有单个参数的 compareBy() 等效于调用 sortedBy()。
函数引用
假设您想要检查 List 是否包含任何重要消息,而不仅仅是未读消息。您可能有许多复杂的标准来决定“重要”是什么意思。您可以将此逻辑放入 Lambda 中,但该 Lambda 可能很容易变得又大又复杂。如果您将其提取到单独的函数中,代码会更容易理解。在 Kotlin 中,您不能将函数传递到函数类型的位置,但可以传递对该函数的引用:
// MemberReferences/FunctionReference.kt
package memberreferences2
import atomictest.eq
data class Message(
val sender: String,
val text: String,
val isRead: Boolean,
val attachments: List<Attachment>
)
data class Attachment(
val type: String,
val name: String
)
fun Message.isImportant(): Boolean =
text.contains("Salary increase") ||
attachments.any {
it.type == "image" &&
it.name.contains("cat")
}
fun main() {
val messages = listOf(Message(
"Boss", "Let's discuss goals " +
"for next year", false,
listOf(Attachment("image", "cute cats"))))
messages.any(Message::isImportant) eq true
}
这个新的 Message 类添加了一个 attachments 属性,扩展函数 Message.isImportant() 使用了这个信息。在调用 messages.any() 时,我们创建了对扩展函数的引用 - 引用不限于成员函数。
如果有一个以 Message 作为唯一参数的顶级函数,您可以将其作为引用传递。当您创建对顶级函数的引用时,没有类名,因此写为 ::function:
// MemberReferences/TopLevelFunctionRef.kt
package memberreferences2
import atomictest.eq
fun ignore(message: Message) =
!message.isImportant() &&
message.sender in setOf("Boss", "Mom")
fun main() {
val text = "Let's discuss goals " +
"for the next year"
val msgs = listOf(
Message("Boss", text, false, listOf()),
Message("Boss", text, false, listOf(
Attachment("image", "cute cats"))))
msgs.filter(::ignore).size eq 1
msgs.filterNot(::ignore).size eq 1
}
构造函数引用
您可以使用类名创建对构造函数的引用。
在这里,names.mapIndexed() 使用构造函数引用 ::Student:
// MemberReferences/ConstructorReference.kt
package memberreferences3
import atomictest.eq
data class Student(
val id: Int,
val name: String
)
fun main() {
val names = listOf("Alice", "Bob")
val students =
names.mapIndexed { index, name ->
Student(index, name)
}
students eq listOf(Student(0, "Alice"),
Student(1, "Bob"))
names.mapIndexed(::Student) eq students
}
mapIndexed() 在 Lambdas 中已介绍。它将 names 中的每个元素转换为该元素的索引以及元素本身。在 students 的定义中,这些被显式地映射到构造函数,但是使用 names.mapIndexed(::Student) 可以实现相同的效果。因此,函数和构造函数引用可以消除只是传递到 Lambda 中的一长串参数的需要。函数和构造函数引用通常比 Lambda 更具可读性。
扩展函数引用
要生成对扩展函数的引用,将引用前缀添加到扩展类型的名称:
// MemberReferences/ExtensionReference.kt
package memberreferences
import atomictest.eq
fun Int.times47() = times(47)
class Frog
fun Frog.speak() = "Ribbit!"
fun goInt(n: Int, g: (Int) -> Int) = g(n)
fun goFrog(frog:
Frog, g: (Frog) -> String) =
g(frog)
fun main() {
goInt(12, Int::times47) eq 564
goFrog(Frog(), Frog::speak) eq "Ribbit!"
}
在 goInt() 中,g 是一个期望 Int 参数并产生 Int 的函数。在 goFrog() 中,g 期望一个 Frog 并产生一个 String。
练习和解答可在 www.AtomicKotlin.com 找到。
高阶函数
如果语言的函数可以接受其他函数作为参数并产生函数作为返回值,则称其支持高阶函数。
高阶函数是函数式编程语言的一个重要部分。在之前的原子中,我们已经看到了诸如 filter()、map() 和 any() 等高阶函数。
您可以将一个 Lambda 存储在引用中。让我们看看这种存储的类型:
// HigherOrderFunctions/IsPlus.kt
package higherorderfunctions
import atomictest.eq
val isPlus: (Int) -> Boolean = { it > 0 }
fun main() {
listOf(1, 2, -3).any(isPlus) eq true
}
(Int) -> Boolean 是函数类型:它以括号开始,括号中包含零个或多个参数类型,然后是一个箭头 (->),后跟返回类型:
(参数1类型, 参数2类型... 参数N类型) -> 返回类型
通过引用调用函数的语法与普通函数调用相同:
// HigherOrderFunctions/CallingReference.kt
package higherorderfunctions
import atomictest.eq
val helloWorld: () -> String =
{ "Hello, world!" }
val sum: (Int, Int) -> Int =
{ x, y -> x + y }
fun main() {
helloWorld() eq "Hello, world!"
sum(1, 2) eq 3
}
当函数接受一个函数参数时,您可以传递给它一个函数引用或 Lambda。考虑如何定义标准库中的 any():
// HigherOrderFunctions/Any.kt
package higherorderfunctions
import atomictest.eq
fun <T> List<T>.any( // [1]
predicate: (T) -> Boolean // [2]
): Boolean {
for (element in this) {
if (predicate(element)) // [3]
return true
}
return false
}
fun main() {
val ints = listOf(1, 2, -3)
ints.any { it > 0 } eq true // [4]
val strings = listOf("abc", " ")
strings.any { it.isBlank() } eq true // [5]
strings.any(String::isNotBlank) eq // [6]
true
}
- [1]
any()应该适用于不同类型的List,因此我们将其定义为泛型List<T>的扩展函数。 - [2]
predicate函数可以调用参数类型为T的参数,因此我们可以将其应用于List元素。 - [3] 应用
predicate()可以判断element是否符合我们的条件。 - Lambda 的类型有所不同:在 [4] 中是
Int,在 [5] 中是String。 - [6] 成员引用是传递函数引用的另一种方式。
标准库中的 repeat() 接受一个函数作为其第二个参数。它将一个操作重复多次:
// HigherOrderFunctions/RepeatByInt.kt
import atomictest.*
fun main() {
repeat(4) { trace("hi!") }
trace eq "hi! hi! hi! hi!"
}
考虑如何定义 repeat():
// HigherOrderFunctions/Repeat.kt
package higherorderfunctions
import atomictest.*
fun repeat(
times: Int,
action: (Int) -> Unit // [1]
) {
for (index in 0 until times) {
action(index) // [2]
}
}
fun main() {
repeat(3) { trace("#$it") } // [3]
trace eq "#0 #1 #2"
}
- [1]
repeat()接受类型为(Int) -> Unit的参数action。 - [2] 调用
action()时,它会传递当前重复的index。 - [3] 在调用
repeat()时,您可以在 Lambda 中使用it访问重复的index。
函数的返回类型可以为可空:
// HigherOrderFunctions/NullableReturn.kt
import atomictest.eq
fun main() {
val transform: (String) -> Int? =
{ s: String -> s.toIntOrNull() }
transform("112") eq 112
transform("abc") eq null
val x = listOf("112", "abc")
x.mapNotNull(transform) eq "[112]"
x.mapNotNull { it.toIntOrNull() } eq "[112]"
}
toIntOrNull() 可能返回 null,因此 transform() 接受一个 String 并返回一个可空的 Int?。mapNotNull() 将 List 中的每个元素转换为可空值,并从结果中删除所有 null。它的效果与先调用 map(),然后对所得列表应用 filterNotNull() 是相同的。
注意将返回类型可空与将整个函数类型可空之间的区别:
// HigherOrderFunctions/NullableFunction.kt
import atomictest.eq
fun main() {
val returnTypeNullable: (String) -> Int? =
{ null }
val mightBeNull: ((String) -> Int)? = null
returnTypeNullable("abc") eq null
// 无法在没有空检查的情况下编译:
// mightBeNull("abc")
if (mightBeNull != null) {
mightBeNull("abc")
}
}
在调用存储在 mightBeNull 中的函数之前,我们必须确保函数引用本身不为 null。
练习和解答可在 www.AtomicKotlin.com 找到。
操作列表
压缩和展平是两种常见的操作,用于操作
List。
压缩
zip() 通过模仿夹克上的拉链的行为,将两个 List 结合在一起,将相邻的 List 元素成对配对:
// ManipulatingLists/Zipper.kt
import atomictest.eq
fun main() {
val left = listOf("a", "b", "c", "d")
val right = listOf("q", "r", "s", "t")
left.zip(right) eq // [1]
"[(a, q), (b, r), (c, s), (d, t)]"
left.zip(0..4) eq // [2]
"[(a, 0), (b, 1), (c, 2), (d, 3)]"
(10..100).zip(right) eq // [3]
"[(10, q), (11, r), (12, s), (13, t)]"
}
- [1] 将
left与right进行压缩,结果是一个Pair的List,将left中的每个元素与其相应的right中的元素配对。 - [2] 您还可以使用范围来对
zip()进行调用。 - [3] 范围
10..100比right大得多,但在其中一个序列用尽时,压缩过程会停止。
zip() 也可以对其创建的每个 Pair 执行操作:
// ManipulatingLists/ZipAndTransform.kt
package manipulatinglists
import atomictest.eq
data class Person(
val name: String,
val id: Int
)
fun main() {
val names = listOf("Bob", "Jill", "Jim")
val ids = listOf(1731, 9274, 8378)
names.zip(ids) { name, id ->
Person(name, id)
} eq "[Person(name=Bob, id=1731), " +
"Person(name=Jill, id=9274), " +
"Person(name=Jim, id=8378)]"
}
names.zip(ids) { ... } 生成了一个名称 - id Pair 序列,并将 lambda 应用于每个 Pair。结果是初始化的 Person 对象的 List。
要从单个 List 中合并两个相邻的元素,使用 zipWithNext():
// ManipulatingLists/ZippingWithNext.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'd')
list.zipWithNext() eq listOf(
Pair('a', 'b'),
Pair('b', 'c'),
Pair('c', 'd'))
list.zipWithNext { a, b -> "$a$b" } eq
"[ab, bc, cd]"
}
对 zipWithNext() 的第二次调用在压缩之后执行了附加操作。
展平
flatten() 接受一个包含元素本身是 List 的元素的 List(即 List 的 List),并将其展平为包含单个元素的 List:
// ManipulatingLists/Flatten.kt
import atomictest.eq
fun main() {
val list = listOf(
listOf(1, 2),
listOf(4, 5),
listOf(7, 8),
)
list.flatten() eq "[1, 2, 4, 5, 7, 8]"
}
flatten() 帮助我们理解另一个在集合上执行的重要操作:flatMap()。让我们产生一个范围的所有可能的 Pair:
// ManipulatingLists/FlattenAndFlatMap.kt
import atomictest.eq
fun main() {
val intRange = 1..3
intRange.map { a -> // [1]
intRange.map { b -> a to b }
} eq "[" +
"[(1, 1), (1, 2), (1, 3)], " +
"[(2,
1), (2, 2), (2, 3)], " +
"[(3, 1), (3, 2), (3, 3)]" +
"]"
intRange.map { a -> // [2]
intRange.map { b -> a to b }
}.flatten() eq "[" +
"(1, 1), (1, 2), (1, 3), " +
"(2, 1), (2, 2), (2, 3), " +
"(3, 1), (3, 2), (3, 3)" +
"]"
intRange.flatMap { a -> // [3]
intRange.map { b -> a to b }
} eq "[" +
"(1, 1), (1, 2), (1, 3), " +
"(2, 1), (2, 2), (2, 3), " +
"(3, 1), (3, 2), (3, 3)" +
"]"
}
每种情况下的 lambda 都是相同的:将每个 intRange 元素与每个 intRange 元素结合,以生成所有可能的 a to b Pair。但是在 [1] 中,map() 有助于保留额外的信息,这里我们已经生成了三个 List,每个都对应于 intRange 中的一个元素。在某些情况下,这些额外的信息是必不可少的,但在这里我们不需要它 - 我们只需要一个单一的扁平 List,其中包含所有组合,没有额外的结构。
有两个选择。[2] 展示了将 flatten() 函数应用于移除这个额外结构并将结果展平为单个 List,这是可接受的方法。但是,这是一个非常常见的任务,Kotlin 提供了一个称为 flatMap() 的组合操作,它通过单个调用执行 map() 和 flatten()。[3] 展示了 flatMap() 的使用。在大多数支持函数式编程的语言中,您会发现 flatMap()。
下面是 flatMap() 的另一个示例:
// ManipulatingLists/WhyFlatMap.kt
package manipulatinglists
import atomictest.eq
class Book(
val title: String,
val authors: List<String>
)
fun main() {
val books = listOf(
Book("1984", listOf("George Orwell")),
Book("Ulysses", listOf("James Joyce"))
)
books.map { it.authors }.flatten() eq
listOf("George Orwell", "James Joyce")
books.flatMap { it.authors } eq
listOf("George Orwell", "James Joyce")
}
我们希望得到一个作者的 List。map() 生成了一个作者的 List 的 List,这并不是很方便。flatten() 将其接受并生成一个简单的 List。flatMap() 在单个步骤中生成相同的结果。
在此示例中,我们使用 map() 和 flatMap() 将 enum Suit 和 Rank 结合在一起,生成一副 Card:
// ManipulatingLists/PlayingCards.kt
package manipulatinglists
import kotlin.random.Random
import atomictest.*
enum class Suit {
Spade, Club, Heart, Diamond
}
enum class Rank(val faceValue: Int) {
Ace(1), Two(2), Three(3), Four(4), Five(5),
Six(6), Seven(7), Eight(8), Nine(9),
Ten(10), Jack(10), Queen(10), King(10)
}
class Card(val rank: Rank, val suit: Suit) {
override fun toString() =
"$rank of ${suit}s"
}
val deck: List<Card> =
Suit.values().flatMap { suit ->
Rank.values().map { rank ->
Card(rank, suit)
}
}
fun main() {
val rand = Random(26)
repeat(7) {
trace("'${deck.random(rand)}'")
}
trace eq """
'Jack of Hearts' 'Four of Hearts'
'Five of Clubs' 'Seven of Clubs'
'Jack of Diamonds' 'Ten of Spades'
'Seven of Spades'
"""
}
在初始化 deck 中,内部的 Rank.values().map 生成了四个 List,一个对应于每个 Suit,因此我们在外部循环上使用了 flatMap(),以生成一个
Card 的 List,用于 deck。
练习和解答可以在 www.AtomicKotlin.com 找到。
构建映射
Map是非常有用的编程工具,有许多方法可以构建它们。
为了创建可重复的数据集,我们使用了 Manipulating Lists 中展示的技术,其中两个 List 被合并在一起,然后结果在一个 lambda 中被用于调用构造函数,生成一个 List<Person>:
// BuildingMaps/People.kt
package buildingmaps
data class Person(
val name: String,
val age: Int
)
val names = listOf("Alice", "Arthricia",
"Bob", "Bill", "Birdperson", "Charlie",
"Crocubot", "Franz", "Revolio")
val ages = listOf(21, 15, 25, 25, 42, 21,
42, 21, 33)
fun people(): List<Person> =
names.zip(ages) { name, age ->
Person(name, age)
}
Map 使用键来快速访问其值。通过使用 age 作为键构建一个 Map,我们可以通过年龄快速查找人的分组。库函数 groupBy() 是一种创建这种 Map 的方式:
// BuildingMaps/GroupBy.kt
import buildingmaps.*
import atomictest.eq
fun main() {
val map: Map<Int, List<Person>> =
people().groupBy(Person::age)
map[15] eq listOf(Person("Arthricia", 15))
map[21] eq listOf(
Person("Alice", 21),
Person("Charlie", 21),
Person("Franz", 21))
map[22] eq null
map[25] eq listOf(
Person("Bob", 25),
Person("Bill", 25))
map[33] eq listOf(Person("Revolio", 33))
map[42] eq listOf(
Person("Birdperson", 42),
Person("Crocubot", 42))
}
groupBy() 的参数产生一个 Map,其中每个键连接到一个 List 元素。在这里,所有相同 age 的人都被 age 键选择。
您也可以使用 filter() 函数产生相同的分组,但是 groupBy() 更可取,因为它只执行一次分组。使用 filter() 您必须为每个新键重复分组:
// BuildingMaps/GroupByVsFilter.kt
import buildingmaps.*
import atomictest.eq
fun main() {
val groups =
people().groupBy { it.name.first() }
// groupBy() 产生具有映射速度的访问:
groups['A'] eq listOf(Person("Alice", 21),
Person("Arthricia", 15))
groups['Z'] eq null
// 必须为每个字符重复使用 filter():
people().filter {
it.name.first() == 'A'
} eq listOf(Person("Alice", 21),
Person("Arthricia", 15))
people().filter {
it.name.first() == 'F'
} eq listOf(Person("Franz", 21))
people().partition {
it.name.first() == 'A'
} eq Pair(
listOf(Person("Alice", 21),
Person("Arthricia", 15)),
listOf(Person("Bob", 25),
Person("Bill", 25),
Person("Birdperson", 42),
Person("Charlie", 21),
Person("Crocubot", 42),
Person("Franz", 21),
Person("Revolio", 33)))
}
在这里,groupBy() 将 people() 按其首字母分组,由 first() 选择。我们还可以使用 filter() 通过为每个字符重复使用 lambda 代码来产生相同的结果。
如果您只需要两个分组,则 partition() 函数更直接,因为它基于谓词将内容分为两个列表。当您需要超过两个结果分组时,groupBy() 是适当的。
associateWith() 允许您获取一组键,并通过将每个键与其参数(在这里是 lambda)关联起来来构建一个 Map:
// BuildingMaps/AssociateWith.kt
import buildingmaps.*
import atomictest.eq
fun main() {
val map: Map<Person, String> =
people().associateWith { it.name }
map eq mapOf(
Person("Alice", 21) to "Alice",
Person("Arthricia", 15) to "Arthricia",
Person("Bob", 25) to "Bob",
Person("Bill", 25) to "Bill",
Person("Birdperson", 42) to "Birdperson",
Person("Charlie", 21) to "Charlie",
Person("Crocubot", 42) to "Crocubot",
Person("Franz", 21) to "Franz",
Person("Revolio", 33) to "Revolio")
}
associateBy() 反转了 associateWith() 产生的关联顺序 - 选择器(下面的 lambda)变为键:
// BuildingMaps/AssociateBy.kt
import buildingmaps.*
import atomictest.eq
fun main() {
val map: Map<String, Person> =
people().associateBy { it.name }
map eq mapOf(
"Alice" to Person("Alice", 21),
"Arthricia" to Person("Arthricia", 15),
"Bob" to Person("Bob", 25),
"Bill" to Person("Bill", 25),
"Birdperson" to Person("Birdperson", 42),
"Charlie" to Person("Charlie", 21),
"Crocubot" to Person("Crocubot", 42),
"Franz" to Person("Franz", 21),
"Revolio" to Person("Revolio", 33))
}
associateBy() 必须与唯一的选择键一起使用,并返回一个将每个唯一键与由该键选择的单个元素配对的 Map。
// BuildingMaps/AssociateByUnique.kt
import buildingmaps.*
import atomictest.eq
fun main() {
// 当键不是唯一时,associateBy() 会失败 - 值会消失:
val ages = people().associateBy { it.age }
ages eq mapOf(
21 to Person("Franz", 21),
15 to Person("Arthricia", 15),
25 to Person("Bill", 25),
42 to Person("Crocubot", 42),
33 to Person("Revolio", 33))
}
如果谓词选择了多个值,就像 ages 中一样,只有最后一个值会出现在生成的 Map 中。
getOrElse() 尝试在 Map 中查找值。与它关联的 lambda 在没有键时计算默认值。因为它是一个 lambda,所以只在必要时才计算默认的 key:
// BuildingMaps/GetOrPut.kt
import atomictest.eq
fun main() {
val map = mapOf(1 to "one", 2 to "two")
map.getOrElse(0) { "zero" } eq "zero"
val mutableMap = map.toMutableMap()
mutableMap.getOrPut(0) { "zero" } eq
"zero"
mutableMap eq "{1=one, 2=two, 0=zero}"
}
getOrPut() 适用于 MutableMap。如果键存在,它只返回与之关联的值。如果未找到键,它会计算该值,将其放入映射中并返回该值。
许多 Map 操作都与 List 中的操作相似。例如,您可以对 Map 的内容进行 filter() 或 map()。您可以分别筛选键和值:
// BuildingMaps/FilterMap.kt
import atomictest.eq
fun main() {
val map = mapOf(1 to "one",
2 to "two", 3 to "three", 4 to "four")
map.filterKeys { it % 2 == 1 } eq
"{1=one, 3=three}"
map.filterValues { it.contains('o') } eq
"{1=one, 2=two, 4=four}"
map.filter { entry ->
entry.key % 2 == 1 &&
entry.value.contains('o')
} eq "{1=one}"
}
这三个函数 filter()、filterKeys() 和 filterValues() 会产生一个新的 Map,其中只包含满足谓词的元素。filterKeys() 将其谓词应用于键,而 filterValues() 则将其谓词应用于值。
对 Map 应用操作
在 Map 中应用 map() 听起来像一种自反的说法,就像说“盐是咸的一样”。单词 map 代表了两个不同的概念:
- 转换集合
- 键-值数据结构
在许多编程语言中,单词 map 被用于这两个概念。为了清楚起见,当将 map() 应用于 Map 时,我们说 transform a map。
在这里,我们演示了 map()、mapKeys() 和 mapValues():
// BuildingMaps/TransformingMap.kt
import atomictest.eq
fun main() {
val even = mapOf(2 to "two", 4 to "four")
even.map { // [1]
"${it.key}=${it.value}"
} eq listOf("2=two", "4=four")
even
.map { (key, value) -> // [2]
"$key=$value"
} eq listOf("2=two", "4=four")
even.mapKeys { (num, _) -> -num } // [3]
.mapValues { (_, str) -> "minus $str" } eq
mapOf(-2 to "minus two",
-4 to "minus four")
even.map { (key, value) ->
-key to "minus $value"
}.toMap() eq mapOf(-2 to "minus two", // [4]
-4 to "minus four")
}
- [1] 在这里,
map()接受一个带有Map.Entry参数的谓词。我们将其内容作为it.key和it.value访问。 - [2] 您还可以使用 析构声明 将条目内容放入
key和value中。 - [3] 如果未使用参数,则下划线 (
_) 可避免编译器投诉。mapKeys()和mapValues()返回一个新的Map,其中所有键或值都相应地进行了转换。 - [4]
map()返回一组配对,因此要生成一个Map,我们使用显式转换toMap()。
像 any() 和 all() 这样的函数也可以应用于 Map:
// BuildingMaps/SimilarOperation.kt
import atomictest.eq
fun main() {
val map = mapOf(1 to "one",
-2 to "minus two")
map.any { (key, _) -> key < 0 } eq true
map.all { (key, _) -> key < 0 } eq false
map.maxByOrNull { it.key }?.value eq "one"
}
any() 检查 Map 中的任何条目是否满足给定的谓词,而 all() 仅在 Map 中的所有条目都满足谓词时为 true。
maxByOrNull() 根据给定的标准查找最大的条目。可能不存在最大的条目,因此结果可为空。
练习和解答可以在 www.AtomicKotlin.com 找到。
序列
Kotlin 的
Sequence类似于List,但您只能迭代遍历Sequence,不能对Sequence进行索引。这个限制产生了非常高效的链式操作。
在其他函数式语言中,Kotlin 的 Sequence 被称为 流(stream)。Kotlin 必须选择一个不同的名称,以保持与 Java 8 的 Stream 库的互操作性。
对 List 的操作是急切(eager)执行的,它们总是立即执行的。在链接 List 操作时,必须在开始下一个操作之前生成第一个结果。在下面的示例中,每个 filter()、map() 和 any() 操作都应用于 list 中的每个元素:
// Sequences/EagerEvaluation.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4)
list.filter { it % 2 == 0 }
.map { it * it }
.any { it < 10 } eq true
// 相当于:
val mid1 = list.filter { it % 2 == 0 }
mid1 eq listOf(2, 4)
val mid2 = mid1.map { it * it }
mid2 eq listOf(4, 16)
mid2.any { it < 10 } eq true
}
急切求值是直观而简单的,但可能不太优化。在 EagerEvaluation.kt 中,遇到满足 any() 的第一个元素后停止会更有意义。对于长序列,这种优化可能比计算每个元素然后搜索单个匹配要快得多。
急切求值有时被称为水平求值:
水平求值
第一行包含初始列表内容。每一行后面都显示了上一个操作的结果。在执行下一个操作之前,会处理当前水平级别上的所有元素。
急切求值的替代方案是惰性求值:只有在需要时才计算结果。在序列上执行惰性操作有时被称为垂直求值:
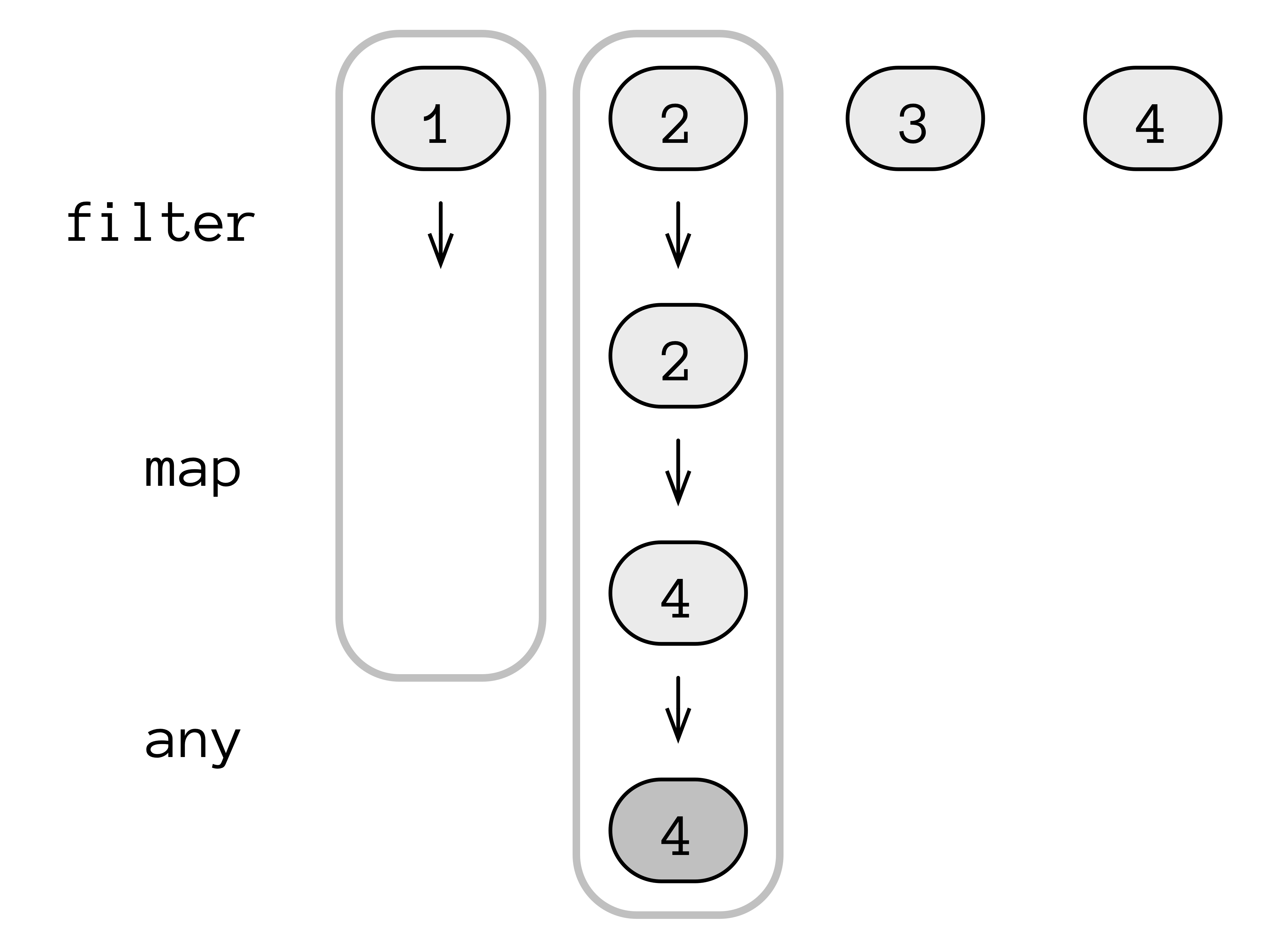
垂直求值
使用惰性求值,仅当请求某个元素的关联结果时才对该元素执行操作。如果在处理最后一个元素之前找到了计算的最终结果,那么不会再处理更多的元素。
通过使用 asSequence() 将 List 转换为 Sequence,可以实现惰性求值。除索引之外,所有 List 操作也适用于 Sequence,因此通常可以进行这个单一的改变,并获得惰性求值的好处。
下面的示例将上述图示转换为代码。我们首先在 List 上执行相同的一系列操作,然后在 Sequence 上执行。输出显示了每个操作的调用位置:
// Sequences/EagerVsLazyEvaluation.kt
package sequences
import atomictest.*
fun Int.isEven(): Boolean {
trace("$this.isEven()")
return this % 2 == 0
}
fun Int.square(): Int {
trace("$this.square()")
return this * this
}
fun Int.lessThanTen(): Boolean {
trace("$this.lessThanTen()")
return this < 10
}
fun main() {
val list = listOf(1, 2, 3, 4)
trace(">>> List:")
trace(
list
.filter(Int::isEven)
.map(Int::square)
.any(Int::lessThanTen)
)
trace(">>> Sequence:")
trace(
list.asSequence()
.filter(Int::isEven)
.map(Int::square)
.any(Int::lessThanTen)
)
trace eq """
>>> List:
1.isEven()
2.isEven()
3.isEven()
4.isEven()
2.square()
4.square()
4.lessThanTen()
true
>>> Sequence:
1.isEven()
2.isEven()
2.square()
4.lessThanTen()
true
"""
}
两种方法之间唯一的区别是添加了 asSequence() 调用,但是 List 代码会处理更多的元素。
在 Sequence 上调用 filter() 或 map() 会产生另一个 Sequence。在从计算中请求结果之前,什么都不会发生。相反,新的 Sequence 存储了有关延迟操作的所有信息,并且只有在需要时才执行这些操作:
// Sequences/NoComputationYet.kt
import atomictest.eq
import sequences.*
fun main() {
val r = listOf(1, 2, 3, 4)
.asSequence()
.filter(Int::isEven)
.map(Int::square)
r.toString().substringBefore("@") eq
"kotlin.sequences.TransformingSequence"
}
将 r 转换为字符串不会产生所需的结果,而只会产生对象的标识符(包括内存中对象的 @ 地址,我们使用标准库的 substringBefore() 删除它)。TransformingSequence 只保存操作,但不执行它们。
Sequence 操作分为两类:中间操作 和 终端操作。中间操作返回另一个 Sequence 作为结果。filter() 和 map() 是中间操作。终端操作返回一个非 Sequence。为了实现这一点,终端操作会执行所有存储的计算。在前面的示例中,any() 是终端操作,因为它接受一个 Sequence 并返回一个 Boolean。在下面的示例中,`
toList()是终端操作,因为它将Sequence转换为List`,在此过程中运行所有存储的操作:
// Sequences/TerminalOperations.kt
import sequences.*
import atomictest.*
fun main() {
val list = listOf(1, 2, 3, 4)
trace(list.asSequence()
.filter(Int::isEven)
.map(Int::square)
.toList())
trace eq """
1.isEven()
2.isEven()
2.square()
3.isEven()
4.isEven()
4.square()
[4, 16]
"""
}
由于 Sequence 存储操作,它可以以任何顺序调用这些操作,从而实现惰性求值。
下面的示例使用标准库函数 generateSequence() 生成一个无限自然数序列。第一个参数是序列中的初始元素,后面跟着一个定义如何从上一个元素计算下一个元素的 lambda:
// Sequences/GenerateSequence1.kt
import atomictest.eq
fun main() {
val naturalNumbers =
generateSequence(1) { it + 1 }
naturalNumbers.take(3).toList() eq
listOf(1, 2, 3)
naturalNumbers.take(10).sum() eq 55
}
Collection 具有已知大小,可以通过其 size 属性发现。Sequence 被视为无限大。在这里,我们使用 take() 来决定需要多少个元素,然后是终端操作(toList() 或 sum())。
generateSequence() 还有一个重载版本,不需要第一个参数,只需要一个返回序列中下一个元素的 lambda。当没有更多元素时,它会返回 null。下面的示例生成一个 Sequence,直到输入中出现“终止标志” XXX:
// Sequences/GenerateSequence2.kt
import atomictest.*
fun main() {
val items = mutableListOf(
"first", "second", "third", "XXX", "4th"
)
val seq = generateSequence {
items.removeAt(0).takeIf { it != "XXX" }
}
seq.toList() eq "[first, second, third]"
capture {
seq.toList()
} eq "IllegalStateException: This " +
"sequence can be consumed only once."
}
removeAt(0) 从 List 中删除并生成零索引位置的元素。takeIf() 如果满足给定的谓词,则返回接收者(由 removeAt(0) 生成的 String),如果谓词失败(当 String 为 "XXX" 时),则返回 null。
您只能对 Sequence 进行一次迭代。进一步的尝试会产生异常。要通过 Sequence 进行多次遍历,请首先将其转换为某种类型的 Collection。
下面是 takeIf() 的实现,使用泛型 T 定义,以便可以与任何类型的参数一起使用:
// Sequences/DefineTakeIf.kt
package sequences
import atomictest.eq
fun <T> T.takeIf(
predicate: (T) -> Boolean
): T? {
return if (predicate(this)) this else null
}
fun main() {
"abc".takeIf { it != "XXX" } eq "abc"
"XXX".takeIf { it != "XXX" } eq null
}
在这里,generateSequence() 和 takeIf() 生成一个递减的数字序列:
// Sequences/NumberSequence2.kt
import atomictest.eq
fun main() {
generateSequence(6) {
(it - 1).takeIf { it > 0 }
}.toList() eq listOf(6, 5, 4, 3, 2, 1)
}
普通的 if 表达式始终可以用作 takeIf() 的替代方案,但是引入额外的标识符可能会使 if 表达式变得笨拙。takeIf() 版本更加功能化,特别是如果它作为一系列调用的一部分使用。
练习和解答可以在 www.AtomicKotlin.com 找到。
局部函数
您可以在任何地方定义函数,甚至可以在其他函数内部定义函数。
在其他函数内部定义的命名函数称为本地函数。本地函数通过提取重复的代码来减少重复,并且仅在周围函数内部可见,因此它们不会“污染您的命名空间”。在下面的示例中,即使 log() 被定义得就像任何其他函数一样,它也是嵌套在 main() 内部的:
// LocalFunctions/LocalFunctions.kt
import atomictest.eq
fun main() {
val logMsg = StringBuilder()
fun log(message: String) =
logMsg.appendLine(message)
log("Starting computation")
val x = 42 // 模拟计算
log("Computation result: $x")
logMsg.toString() eq """
Starting computation
Computation result: 42
"""
}
本地函数是闭包:它们捕获来自周围环境的 var 或 val,否则必须作为附加参数传递。log() 使用了在其外部作用域中定义的 logMsg。这样,您就不需要将 logMsg 反复传递给 log()。
您可以创建本地扩展函数:
// LocalFunctions/LocalExtensions.kt
import atomictest.eq
fun main() {
fun String.exclaim() = "$this!"
"Hello".exclaim() eq "Hello!"
"Hallo".exclaim() eq "Hallo!"
"Bonjour".exclaim() eq "Bonjour!"
"Ciao".exclaim() eq "Ciao!"
}
exclaim() 仅在 main() 内部可用。
以下是一个演示类和用于此章节的示例值:
// LocalFunctions/Session.kt
package localfunctions
class Session(
val title: String,
val speaker: String
)
val sessions = listOf(Session(
"Kotlin Coroutines", "Roman Elizarov"))
val favoriteSpeakers = setOf("Roman Elizarov")
您可以使用函数引用引用本地函数:
// LocalFunctions/LocalFunctionReference.kt
import localfunctions.*
import atomictest.eq
fun main() {
fun interesting(session: Session): Boolean {
if (session.title.contains("Kotlin") &&
session.speaker in favoriteSpeakers) {
return true
}
// ... 更多检查
return false
}
sessions.any(::interesting) eq true
}
interesting() 仅使用一次,因此我们可能倾向于将其定义为 lambda。正如您将在本章后面看到的那样,在 interesting() 中的 return 表达式会使将其转换为 lambda 变得复杂。我们可以通过匿名函数来避免这种复杂性。与本地函数类似,匿名函数在其他函数内部定义,但匿名函数没有名称。匿名函数在概念上类似于 lambda,但使用 fun 关键字。以下是使用匿名函数重写的 LocalFunctionReference.kt:
// LocalFunctions/InterestingSessions.kt
import localfunctions.*
import atomictest.eq
fun main() {
sessions.any(
fun(session: Session): Boolean { // [1]
if (session.title.contains("Kotlin") &&
session.speaker in favoriteSpeakers) {
return true
}
// ... 更多检查
return false
}) eq true
}
- [1] 匿名函数看起来像一个没有函数名的常规函数。在这里,匿名函数作为参数传递给
sessions.any()。
如果 lambda 变得过于复杂并且难以阅读,可以将其替换为本地函数或匿名函数。
标签
在这里,forEach() 执行包含 return 的 lambda:
// LocalFunctions/ReturnFromFun.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach {
result += "$it"
if (it == value) {
result eq "123"
return // [1]
}
}
result eq "永远不会到达这里" // [2]
}
return 表达式会从使用 fun 定义的函数中退出(即不是 lambda)。在第 [1] 行,这意味着从 main() 返回。第 [2] 行永远不会被调用,因此没有输出。
要仅从 lambda 返回,而不是从周围的函数返回,可以使用标记的 return:
// LocalFunctions/LabeledReturn.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach {
result += "$it"
if (it == value) return@forEach
}
result eq "12345"
}
这里,标签是调用 lambda 的函数的名称。标记的返回表达式 return@forEach 告诉它仅返回到名称 forEach。
可以通过在 lambda 前面添加 label@ 来创建标签,其中 label 可以是任何名称:
// LocalFunctions/CustomLabel.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3, 4, 5)
val value = 3
var result = ""
list.forEach tag@{ // [1]
result
+= "$it"
if (it == value) return@tag // [2]
}
result eq "12345"
}
- [1] 此 lambda 被标记为
tag。 - [2]
return@tag从 lambda 返回,而不是从main()返回。
让我们将 InterestingSessions.kt 中的匿名函数替换为 lambda:
// LocalFunctions/ReturnInsideLambda.kt
import localfunctions.*
import atomictest.eq
fun main() {
sessions.any { session ->
if (session.title.contains("Kotlin") &&
session.speaker in favoriteSpeakers) {
return@any true
}
// ... 更多检查
false
} eq true
}
我们必须返回到一个标签,以便仅退出 lambda,而不是退出 main()。
操纵本地函数
您可以将 lambda 或匿名函数存储在 var 或 val 中,然后使用该标识符调用函数。要存储本地函数,请使用函数引用(参见成员引用)。
在下面的示例中,first() 创建一个匿名函数,second() 使用 lambda,third() 返回对本地函数的引用。fourth() 通过使用更紧凑的表达式主体实现了与 third() 相同的效果。fifth() 使用 lambda 实现相同的效果:
// LocalFunctions/ReturningFunc.kt
package localfunctions
import atomictest.eq
fun first(): (Int) -> Int {
val func = fun(i: Int) = i + 1
func(1) eq 2
return func
}
fun second(): (String) -> String {
val func2 = { s: String -> "$s!" }
func2("abc") eq "abc!"
return func2
}
fun third(): () -> String {
fun greet() = "Hi!"
return ::greet
}
fun fourth() = fun() = "Hi!"
fun fifth() = { "Hi!" }
fun main() {
val funRef1: (Int) -> Int = first()
val funRef2: (String) -> String = second()
val funRef3: () -> String = third()
val funRef4: () -> String = fourth()
val funRef5: () -> String = fifth()
funRef1(42) eq 43
funRef2("xyz") eq "xyz!"
funRef3() eq "Hi!"
funRef4() eq "Hi!"
funRef5() eq "Hi!"
first()(42) eq 43
second()("xyz") eq "xyz!"
third()() eq "Hi!"
fourth()() eq "Hi!"
fifth()() eq "Hi!"
}
main() 首先验证调用每个函数是否确实返回了预期类型的函数引用。然后,使用适当的参数调用每个 funRef。最后,调用每个函数,然后立即通过添加适当的参数列表调用返回的函数引用。例如,调用 first() 返回一个函数,因此我们通过添加参数列表 (42) 来调用 该 函数。
练习和解答可以在 www.AtomicKotlin.com 找到。
折叠列表
fold()将列表中的所有元素依次组合在一起,生成单个结果。
一个常见的练习是使用 fold() 实现诸如 sum() 或 reverse() 之类的操作。在这里,fold() 对序列求和:
// FoldingLists/SumViaFold.kt
import atomictest.eq
fun main() {
val list = listOf(1, 10, 100, 1000)
list.fold(0) { sum, n ->
sum + n
} eq 1111
}
fold() 接受初始值(在这种情况下是参数 0),并逐个将操作(在这里表示为 lambda)应用于将当前累积值与每个元素组合在一起。fold() 首先将 0(初始值)和 1 相加,得到 1。这成为了 sum,然后将其与 10 相加,得到 11,这成为了新的 sum。该操作对两个其他元素(100 和 1000)重复执行。这产生了 111 和 1111。当列表中没有其他内容时,fold() 将停止,并返回最终的 sum,即 1111。当然,fold() 实际上并不知道它正在执行“求和”操作,我们选择了标识符名称,以使理解更容易。
为了阐明 fold() 中的步骤,以下是使用普通的 for 循环编写的 SumViaFold.kt:
// FoldingLists/FoldVsForLoop.kt
import atomictest.eq
fun main() {
val list = listOf(1, 10, 100, 1000)
var accumulator = 0
val operation =
{ sum: Int, i: Int -> sum + i }
for (i in list) {
accumulator = operation(accumulator, i)
}
accumulator eq 1111
}
fold() 通过逐个将 operation 应用于将当前元素与累积值组合在一起来累积值。
尽管 fold() 是一个重要的概念,也是在纯函数式语言中累积值的唯一方法,但在 Kotlin 中有时仍然会使用普通的 for 循环。
foldRight() 从右到左处理元素,与从左到右处理元素的 fold() 相反。以下示例演示了这种差异:
// FoldingLists/FoldRight.kt
import atomictest.eq
fun main() {
val list = listOf('a', 'b', 'c', 'd')
list.fold("*") { acc, elem ->
"($acc) + $elem"
} eq "((((*) + a) + b) + c) + d"
list.foldRight("*") { elem, acc ->
"$elem + ($acc)"
} eq "a + (b + (c + (d + (*))))"
}
fold() 首先将操作应用于 a,如 (*) + a 所示,而 foldRight() 首先处理右侧的元素 d,然后最后处理 a。
fold() 和 foldRight() 的第一个参数是显式的累加器值。有时,第一个元素可以充当初始值。reduce() 和 reduceRight() 的行为类似于 fold() 和 foldRight(),但分别使用第一个和最后一个元素作为初始值:
// FoldingLists/ReduceAndReduceRight.kt
import atomictest.eq
fun main() {
val chars = "A B C D E F G H I".split(" ")
chars.fold("X") { a, e -> "$a $e"} eq
"X A B C D E F G H I"
chars.foldRight("X") { a, e -> "$a $e" } eq
"A B C D E F G H I X"
chars.reduce { a, e -> "$a $e" } eq
"A B C D E F G H I"
chars.reduceRight { a, e -> "$a $e" } eq
"A B C D E F G H I"
}
runningFold() 和 runningReduce() 生成一个包含过程中所有中间步骤的 List。List 中的最终值是 fold() 或 reduce() 的结果:
// FoldingLists/RunningFold.kt
import atomictest.eq
fun main() {
val list = listOf(11, 13, 17, 19)
list.fold(7) { sum, n ->
sum + n
} eq 67
list.runningFold(7) { sum, n ->
sum + n
} eq "[7, 18, 31, 48, 67]"
list.reduce { sum, n ->
sum + n
} eq 60
list.runningReduce { sum, n ->
sum + n
} eq "[11, 24, 41, 60]"
}
runningFold() 首先存储初始值(7),然后存储每个中间结果。runningReduce() 会跟踪每个 sum 值。
练习和解答可以在 www.AtomicKotlin.com 找到。
递归
递归 是一种在函数内部调用同一函数的编程技术。尾递归 是一种可以显式应用于某些递归函数的优化技术。
递归函数使用前一个递归调用的结果。阶乘是一个常见的例子,factorial(n) 将从 1 到 n 的所有数字相乘,可以定义如下:
factorial(1)是1factorial(n)是n * factorial(n - 1)
factorial() 是递归的,因为它使用来自相同函数应用于其修改后的参数的结果。这是 factorial() 的递归实现:
// Recursion/Factorial.kt
package recursion
import atomictest.eq
fun factorial(n: Long): Long {
if (n <= 1) return 1
return n * factorial(n - 1)
}
fun main() {
factorial(5) eq 120
factorial(17) eq 355687428096000
}
虽然这种方法易于阅读,但它的成本很高。在调用函数时,关于该函数及其参数的信息会存储在 调用栈 中。当抛出异常并且 Kotlin 显示 堆栈跟踪 时,您可以看到调用栈:
// Recursion/CallStack.kt
package recursion
fun illegalState() {
// throw IllegalStateException()
}
fun fail() = illegalState()
fun main() {
fail()
}
如果您取消注释包含异常的行,您将会看到以下内容:
Exception in thread "main" java.lang.IllegalStateException
at recursion.CallStackKt.illegalState(CallStack.kt:5)
at recursion.CallStackKt.fail(CallStack.kt:8)
at recursion.CallStackKt.main(CallStack.kt:11)
堆栈跟踪显示在抛出异常时的调用栈状态。对于 CallStack.kt,调用栈仅由三个函数组成:
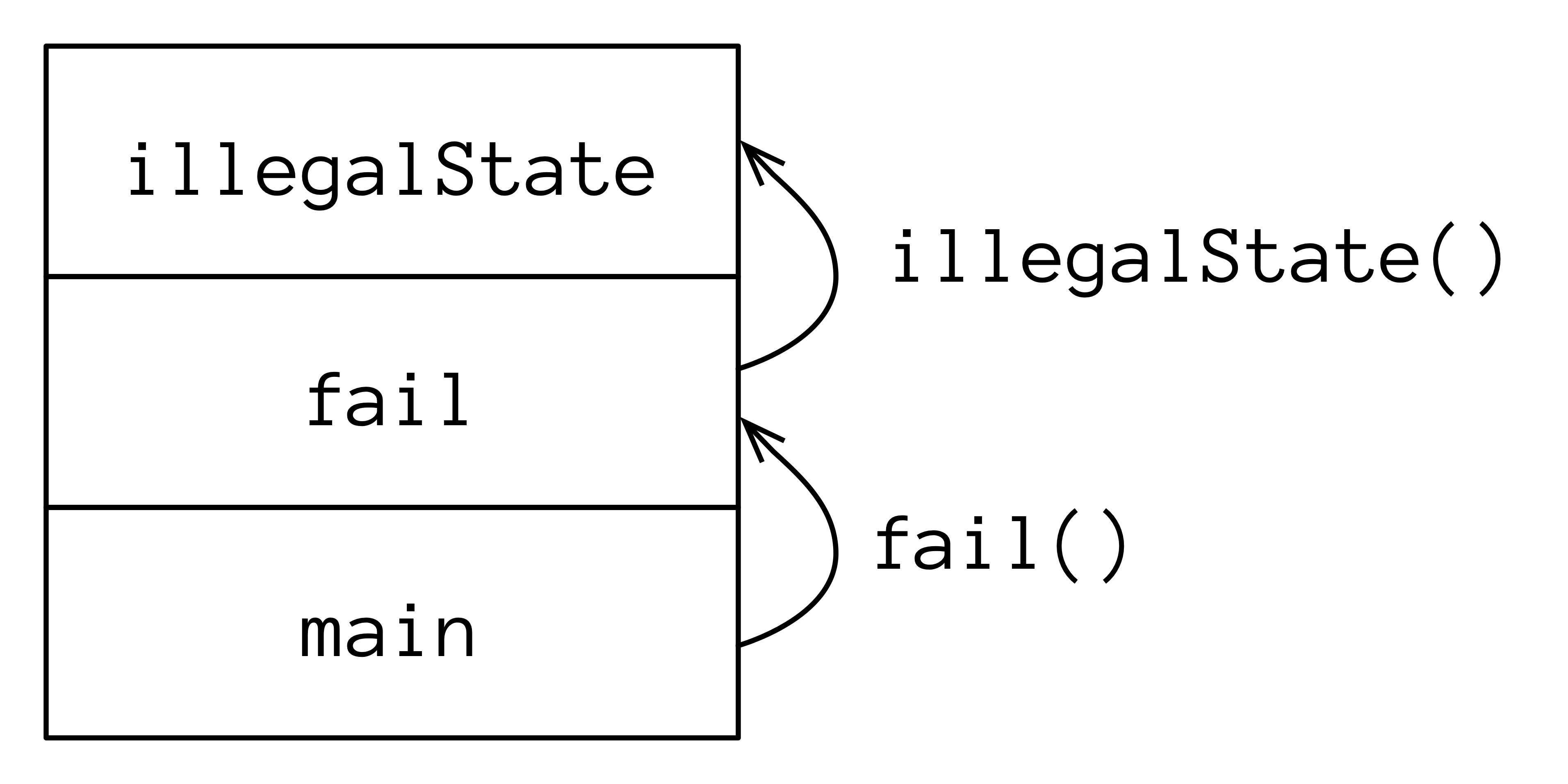
调用栈
我们从 main() 开始,它调用 fail()。fail() 调用将添加到调用栈中,以及它的参数。接下来,fail() 调用 illegalState(),也被添加到调用栈中。
当您调用递归函数时,每次递归调用都会向调用栈添加一个帧。这很容易导致 StackOverflowError,这意味着您的调用栈变得太大,耗尽了可用的内存。
程序员通常会因为忘记终止递归调用链而导致 StackOverflowError,这是 无限递归:
// Recursion/InfiniteRecursion.kt
package recursion
fun recurse(i: Int): Int = recurse(i + 1)
fun main() {
// println(recurse(1))
}
如果您在 main() 中取消注释该行,您将会看到包含许多重复调用的堆栈跟踪:
Exception in thread "main" java.lang.StackOverflowError
at recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:4)
at recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:4)
...
at recursion.InfiniteRecursionKt.recurse(InfiniteRecursion.kt:4)
递归函数不断地调用自身(每次使用不同的参数),并填充调用栈:
无限递归
无限递归总是以 StackOverflowError 结束,但您也可以通过调用足够多的递归函数调用来获得相同的结果。例如,让我们递归地计算到给定数字的整数之和,将 sum(n) 递归地定义为 n + sum(n - 1):
// Recursion/RecursionLimits.kt
package recursion
import atomictest.eq
fun sum(n: Long): Long {
if (n == 0L) return 0
return n + sum(n - 1)
}
fun main() {
sum(2) eq 3
sum(1000) eq 500500
// sum(100_000) eq 500050000 // [1]
(1..100_000L).sum() eq 5000050000 // [2]
}
这种递归很快变得昂贵。如果您取消注释 **[1
]** 行,您会发现它花费太长时间来完成,所有这些递归调用会导致堆栈溢出。如果 sum(100_000) 在您的计算机上仍然可以工作,请尝试更大的数字。
调用 sum(100_000) 会导致 StackOverflowError,因为它将 100_000 个 sum() 函数调用添加到调用栈中。作为比较,[2] 行使用 sum() 库函数来添加范围内的数字,而这不会失败。
为了避免 StackOverflowError,可以使用迭代解决方案来替代递归:
// Recursion/Iteration.kt
package iteration
import atomictest.eq
fun sum(n: Long): Long {
var accumulator = 0L
for (i in 1..n) {
accumulator += i
}
return accumulator
}
fun main() {
sum(10000) eq 50005000
sum(100000) eq 5000050000
}
这里没有 StackOverflowError 的风险,因为我们只进行了一次 sum() 调用,并且结果是在 for 循环中计算的。虽然迭代解决方案很简单,但必须使用可变状态变量 accumulator 来存储不断变化的值,而函数式编程试图避免变异。
为了防止调用栈溢出,函数式语言(包括 Kotlin)使用一种称为 尾递归 的技术。尾递归的目标是减小调用栈的大小。在 sum() 示例中,调用栈变为单个函数调用,就像在 Iteration.kt 中一样:
常规递归 vs. 尾递归
要产生尾递归,使用 tailrec 关键字。在正确的条件下,这会将递归调用转换为迭代,从而消除调用栈的开销。这是一个编译器优化,但不会对所有递归调用都有效。
要成功使用 tailrec,递归必须是最终操作,这意味着在返回之前不能对递归调用的结果进行任何额外的计算。例如,如果我们只是在 RecursionLimits.kt 中的 fun 前面放置了 tailrec,Kotlin 会生成以下警告消息:
- A function is marked as tail-recursive but no tail calls are found
- Recursive call is not a tail call
问题在于在返回结果之前将 n 与递归 sum() 调用的结果 结合 起来。为了使 tailrec 成功,递归调用的结果必须在返回时不进行任何处理。这通常需要对函数进行重新排列。对于 sum(),一个成功的 tailrec 如下所示:
// Recursion/TailRecursiveSum.kt
package tailrecursion
import atomictest.eq
private tailrec fun sum(
n: Long,
accumulator: Long
): Long =
if (n == 0L) accumulator
else sum(n - 1, accumulator + n)
fun sum(n: Long) = sum(n, 0)
fun main() {
sum(2) eq 3
sum(10000) eq 50005000
sum(100000) eq 5000050000
}
通过包含 accumulator 参数,加法发生在递归调用期间,您在返回结果时不对其进行任何处理。现在,tailrec 关键字可以成功使用,因为代码已重写为将所有活动委托给递归调用。此外,accumulator 变为一个不可变值,消除了我们对 Iteration.kt 的抱怨。
factorial() 是一个常见的示例,用于演示尾递归,并且是本节的一个练习。另一个示例是斐波那契数列,其中每个新的斐波那契数是前两个数的和。前两个数字是 0 和 1,产生以下序列:0, 1, 1, 2, 3, 5, 8, 13, 21 ... 这可以递归地表示:
// Recursion/VerySlowFibonacci.kt
package slowfibonacci
import atomictest.eq
fun fibonacci(n: Long): Long {
return when (n) {
0L -> 0
1L -> 1
else ->
fibonacci(n - 1) + fibonacci(n - 2)
}
}
fun main() {
fibonacci(0) eq 0
fibonacci(22) eq 17711
// 非常耗时:
// fibonacci(50) eq 12586269025
}
这个实现非常低效,因为不会重用先前计算的结果。因此,操作数量呈指数级增长:
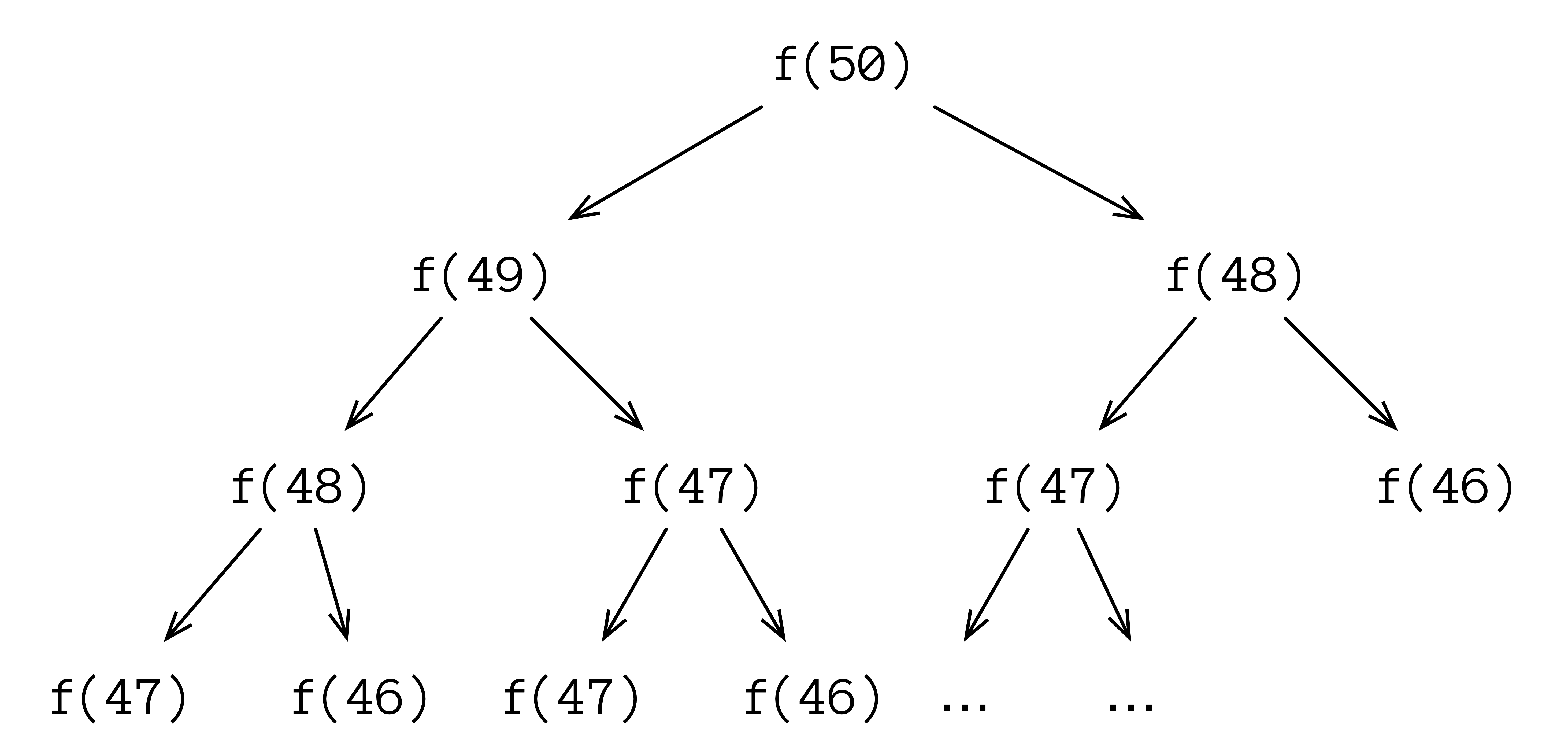
斐波那契数的低效计算
在计算第 50 个斐波那契数时,我们首先独立计算第 49 个和第 48 个数,这意味着我们计算第 48 个数两次。第 46 个数最多计算 4 次,依此类推。
使用尾递归,计算变得非常高效:
// Recursion/Fibonacci.kt
package recursion
import atomictest.eq
fun fibonacci(n: Int):
Long {
tailrec fun fibonacci(
n: Int,
current: Long,
next: Long
): Long {
if (n == 0) return current
return fibonacci(
n - 1, next, current + next)
}
return fibonacci(n, 0L, 1L)
}
fun main() {
(0..8).map { fibonacci(it) } eq
"[0, 1, 1, 2, 3, 5, 8, 13, 21]"
fibonacci(22) eq 17711
fibonacci(50) eq 12586269025
}
我们可以通过使用默认参数来避免本地的 fibonacci() 函数。但是,默认参数意味着用户可以将其他值放入这些默认值中,从而产生错误的结果。因为辅助的 fibonacci() 函数是一个局部函数,所以我们不会暴露额外的参数,您只能调用 fibonacci(n)。
main() 显示了斐波那契序列的前八个元素,结果为 22,最后是现在非常快速地产生的第 50 个斐波那契数。
练习和解答可以在 www.AtomicKotlin.com 找到。
第五部分:面向对象编程
“继承是一种非常灵活的机制。滥用继承是可能的,事实上相当常见,但这并不是对它进行系统性不信任的理由,尽管似乎已经成为一种潮流。” — Bertrand Meyer
接口
接口 描述了一种类型的概念。它是所有实现该接口的类的原型。
它描述了一个类应该做什么,但不涉及它应该如何去做。接口提供了一个形式,但通常不提供具体实现。它规定了对象的操作,但不详细说明这些操作是如何执行的。接口描述了实体的任务或目标,而不是包含实现细节的类。
一个字典的定义说,接口是“独立而常常不相关的系统相遇并相互作用或相互通信的地方”。因此,接口是系统不同部分之间通信的一种方式。
一个 应用程序编程接口(API)是各种软件组件之间明确定义的通信路径的集合。在面向对象编程中,对象的 API 是一组它用于与其他对象交互的公共成员。
使用特定接口的代码只知道可以为该接口调用哪些函数。接口在类之间建立了一个“协议”。(某些面向对象的语言有一个称为 protocol 的关键字来执行同样的操作。)
要创建一个接口,使用 interface 关键字而不是 class 关键字。在定义实现接口的类时,将类名与 :(冒号)和接口的名称连接起来:
// Interfaces/Computer.kt
package interfaces
import atomictest.*
interface Computer {
fun prompt(): String
fun calculateAnswer(): Int
}
class Desktop : Computer {
override fun prompt() = "Hello!"
override fun calculateAnswer() = 11
}
class DeepThought : Computer {
override fun prompt() = "Thinking..."
override fun calculateAnswer() = 42
}
class Quantum : Computer {
override fun prompt() = "Probably..."
override fun calculateAnswer() = -1
}
fun main() {
val computers = listOf(
Desktop(), DeepThought(), Quantum()
)
computers.map { it.calculateAnswer() } eq
"[11, 42, -1]"
computers.map { it.prompt() } eq
"[Hello!, Thinking..., Probably...]"
}
Computer 声明 了 prompt() 和 calculateAnswer(),但没有提供实现。实现接口的类必须为所有声明的函数提供函数体,使这些函数变为 具体 函数。在 main() 中,您可以看到实现接口的不同类通过其函数定义来表达不同的行为。
当实现接口的成员时,必须使用 override 修饰符。override 告诉 Kotlin,您有意使用了接口(或基类)中出现的相同名称,即您不是意外覆盖了它。
接口可以声明属性。这些属性必须在实现该接口的所有类中进行覆盖:
// Interfaces/PlayerInterface.kt
package interfaces
import atomictest.eq
interface Player {
val symbol: Char
}
class Food : Player {
override val symbol = '.'
}
class Robot : Player {
override val symbol get() = 'R'
}
class Wall(override val symbol: Char) : Player
fun main() {
listOf(Food(), Robot(), Wall('|')).map {
it.symbol
} eq "[., R, |]"
}
每个子类以不同的方式覆盖 symbol 属性:
枚举可以实现一个 interface:
// Interfaces/Hotness.kt
package interfaces
import atomictest.*
interface Hotness {
fun feedback(): String
}
enum class SpiceLevel : Hotness {
Mild {
override fun feedback() =
"It adds flavor!"
},
Medium {
override fun feedback() =
"Is it warm in here?"
},
Hot {
override fun feedback() =
"I'm suddenly sweating a lot."
},
Flaming {
override fun feedback() =
"I'm in pain. I am suffering."
}
}
fun main() {
SpiceLevel.values().map { it.feedback() } eq
"[It adds flavor!, " +
"Is it warm in here?, " +
"I'm suddenly sweating a lot., " +
"I'm in pain. I am suffering.]"
}
编译器确保每个 enum 元素为 feedback() 提供了一个定义。
SAM 转换
Single Abstract Method(SAM)接口来自 Java,其中称成员函数为 “方法”。Kotlin 有一种特殊的语法来定义 SAM 接口:fun interface。在这里,我们展示具有不同参数列表的 SAM 接口:
// Interfaces/SAM.kt
package interfaces
fun interface ZeroArg {
fun f(): Int
}
fun interface OneArg {
fun g(n: Int): Int
}
fun interface TwoArg {
fun h(i: Int, j: Int): Int
}
当使用 fun interface 时,编译器确保只有一个单一的成员函数。
您可以以普通冗长的方式实现 SAM 接口,也可以通过传递 lambda 来实现它;后者称为 SAM 转换。在 SAM 转换中,lambda 变成了接口中单一方法的实现。在这里,我们展示了实现三个接口的两种方式:
// Interfaces/SAMImplementation.kt
package interfaces
import atomictest.eq
class VerboseZero : ZeroArg {
override fun f() = 11
}
val verboseZero = VerboseZero()
val samZero = ZeroArg { 11 }
class VerboseOne : OneArg {
override fun g(n: Int) = n + 47
}
val verboseOne = VerboseOne()
val samOne = OneArg { it + 47 }
class VerboseTwo : TwoArg {
override fun h(i: Int, j: Int) = i + j
}
val verboseTwo = VerboseTwo()
val samTwo = TwoArg { i, j -> i + j }
fun main() {
verboseZero.f() eq 11
samZero.f() eq 11
verboseOne.g(92) eq 139
samOne.g(92) eq 139
verboseTwo.h(11, 47) eq 58
samTwo.h(11, 47) eq 58
}
通过比较 “verbose” 实现和 “sam” 实现,您可以看到 SAM 转换为一个常用的习惯用法产生了更简洁的语法,您不必强制定义一个类来创建一个单一的对象。
您可以将 lambda 传递给期望 SAM 接口的地方,而不必首先将其包装为对象:
// Interfaces/SAMConversion.kt
package interfaces
import atomictest.trace
fun interface Action {
fun act()
}
fun delayAction(action: Action) {
trace("Delaying...")
action.act()
}
fun main() {
delayAction { trace("Hey!") }
trace eq "Delaying... Hey!"
}
在 main() 中,我们传递了一个 lambda,而不是实现了 Action interface 的对象。Kotlin 会自动从该 lambda 创建一个 Action 对象。
练习和解答可以在 www.AtomicKotlin.com 找到。
复杂构造函数
为了使代码正常工作,对象必须得到适当的初始化。
构造函数是一个特殊的函数,用于创建一个新的对象。在构造函数中,我们看到了只初始化其参数的简单构造函数。在参数列表中使用 var 或 val 将这些参数变为属性,从对象外部可以访问:
// ComplexConstructors/SimpleConstructor.kt
package complexconstructors
import atomictest.eq
class Alien(val name: String)
fun main() {
val alien = Alien("Pencilvester")
alien.name eq "Pencilvester"
}
在这些情况下,我们不需要编写构造函数代码,Kotlin 会为我们自动完成。为了更多的自定义,可以在类体中添加构造函数代码。在 init 部分内部的代码会在对象创建时执行:
// ComplexConstructors/InitSection.kt
package complexconstructors
import atomictest.eq
private var counter = 0
class Message(text: String) {
private val content: String
init {
counter += 10
content = "[$counter] $text"
}
override fun toString() = content
}
fun main() {
val m1 = Message("Big ba-da boom!")
m1 eq "[10] Big ba-da boom!"
val m2 = Message("Bzzzzt!")
m2 eq "[20] Bzzzzt!"
}
即使构造函数参数没有使用 var 或 val 标记为属性,它们仍然可以在 init 部分内部访问。
尽管定义为 val,但 content 在定义点并未初始化。在这种情况下,Kotlin 确保在构造过程中的某一时刻进行初始化。要么重新分配 content,要么忘记初始化它都会产生错误消息。
- -
构造函数是构造函数参数列表(在进入类体之前初始化)和 init 部分(在对象创建时执行)的组合。Kotlin 允许多个 init 部分,它们按照定义的顺序执行。然而,在大型和复杂的类中,将 init 部分分散开来可能会给习惯于单个 init 部分的程序员带来维护问题。
练习和解答可以在 www.AtomicKotlin.com 找到。
辅助构造函数
当您需要多种方式来构造对象时,具名参数和默认参数通常是最简便的方法。然而,有时您必须创建多个重载的构造函数。
这个构造函数被“重载”,因为您正在为同一类的对象创建不同的构造方式。在 Kotlin 中,重载的构造函数被称为辅助构造函数。构造函数参数列表(紧跟在类名之后的部分)与属性的初始化和 init 块组合在一起,称为主构造函数。
要创建一个辅助构造函数,请使用 constructor 关键字,后面跟着一个与所有其他主要和辅助参数列表都不同的参数列表。在辅助构造函数内部,this 关键字调用主构造函数或另一个辅助构造函数:
// SecondaryConstructors/WithSecondary.kt
package secondaryconstructors
import atomictest.*
class WithSecondary(i: Int) {
init {
trace("Primary: $i")
}
constructor(c: Char) : this(c - 'A') {
trace("Secondary: '$c'")
}
constructor(s: String) :
this(s.first()) { // [1]
trace("Secondary: \"$s\"")
}
/* 不调用主构造函数将不会通过编译:
constructor(f: Float) { // [2]
trace("Secondary: $f")
}
*/
}
fun main() {
fun sep() = trace("-".repeat(10))
WithSecondary(1)
sep()
WithSecondary('D')
sep()
WithSecondary("Last Constructor")
trace eq """
Primary: 1
----------
Primary: 3
Secondary: 'D'
----------
Primary: 11
Secondary: 'L'
Secondary: "Last Constructor"
"""
}
从辅助构造函数调用另一个构造函数(使用 this)必须发生在额外的构造函数逻辑之前,因为构造函数体可能依赖于这些其他初始化。因此,它位于构造函数体之前。
参数列表决定要调用的构造函数。WithSecondary(1) 匹配主构造函数,WithSecondary('D') 匹配第一个辅助构造函数,WithSecondary("Last Constructor") 匹配第二个辅助构造函数。[1] 中的 this() 调用匹配第一个辅助构造函数,并且可以在输出中看到调用链。
主构造函数必须始终被调用,可以直接调用,也可以通过调用辅助构造函数来调用。否则,Kotlin 会在编译时生成错误,就像 [2] 中一样。因此,所有可以在构造函数之间共享的通用初始化逻辑都应该放在主构造函数中。
在使用辅助构造函数时,init 部分是不必要的:
// SecondaryConstructors/GardenItem.kt
package secondaryconstructors
import atomictest.eq
import secondaryconstructors.Material.*
enum class Material {
Ceramic, Metal, Plastic
}
class GardenItem(val name: String) {
var material: Material = Plastic
constructor(
name: String, material: Material // [1]
) : this(name) { // [2]
this.material = material // [3]
}
constructor(
material: Material
) : this("Strange Thing", material) // [4]
override fun toString() = "$material $name"
}
fun main() {
GardenItem("Elf").material eq Plastic
GardenItem("Snowman").name eq "Snowman"
GardenItem("Gazing Ball", Metal) eq // [5]
"Metal Gazing Ball"
GardenItem(material = Ceramic) eq
"Ceramic Strange Thing"
}
- [1] 只有主构造函数的参数可以通过
val或var声明为属性。 - [2] 你不能为辅助构造函数声明返回类型。
- [3]
material参数与属性名称相同,因此我们使用this进行了消除歧义。 - [4] 辅助构造函数体是可选的(尽管您仍然必须包含一个显式的
this()调用)。
在调用 [5] 中的第一个辅助构造函数时,属性 material 被赋值了两次。首先,在调用主构造函数(在 [2] 中)和初始化所有类属性时,将 Plastic 值赋给了它,然后在 [3] 处将其更改为 material 参数。
GardenItem 类可以使用默认参数来简化,用单个主构造函数替换辅助构造函数。
练习和解答可以在 www.AtomicKotlin.com 找到。
继承
继承 是一种通过重新使用和修改现有类来创建新类的机制。
对象通过属性存储数据,并通过成员函数执行操作。每个对象都占据唯一的存储位置,因此一个对象的属性可以与其他每个对象具有不同的值。对象还属于一个称为类的类别,该类别确定了其对象的形式(属性和函数)。因此,对象的外观类似于形成它的类。
创建和调试一个类可能需要大量的工作。如果您想要创建一个与现有类类似但具有一些变化的类,怎么办?从头开始构建一个新类似乎有些浪费。面向对象的语言提供了一种称为继承的重用机制。
继承遵循生物遗传的概念。您会说:“我想从现有类创建一个新类,但加入一些添加和修改。”
继承的语法与实现接口类似。要从现有类 Base 继承新类 Derived,请使用 :(冒号):
// Inheritance/BasicInheritance.kt
package inheritance
open class Base
class Derived : Base()
接下来的原子解释了在继承期间 Base 后面为什么要加括号。
术语基类和派生类(或父类和子类,或超类和子类)经常用于描述继承关系。
基类必须是 open 的。非 open 的类不允许继承 - 默认情况下它是封闭的。这与大多数其他面向对象的语言不同。例如,在 Java 中,一个类会自动可继承,除非您通过将该类声明为 final 来明确禁止继承。尽管 Kotlin 允许这样做,但 final 修饰符是多余的,因为每个类默认情况下实际上都是 final 的:
// Inheritance/OpenAndFinalClasses.kt
package inheritance
// 这个类可以被继承:
open class Parent
class Child : Parent()
// Child 不是 open 的,所以这会失败:
// class GrandChild : Child()
// 这个类无法被继承:
final class Single
// 与使用 'final' 一样:
class AnotherSingle
Kotlin 强制您通过使用 open 关键字来明确类是为继承而设计的,从而澄清您的意图。
在下面的示例中,GreatApe 是一个基类,并且具有两个具有固定值的属性。派生类 Bonobo,Chimpanzee 和 BonoboB 是与其父类相同的新类型:
// Inheritance/GreatApe.kt
package inheritance.ape1
import atomictest.eq
open class GreatApe {
val weight = 100.0
val age = 12
}
open class Bonobo : GreatApe()
class Chimpanzee : GreatApe()
class BonoboB : Bonobo()
fun GreatApe.info() = "wt: $weight age: $age"
fun main() {
GreatApe().info() eq "wt: 100.0 age: 12"
Bonobo().info() eq "wt: 100.0 age: 12"
Chimpanzee().info() eq "wt: 100.0 age: 12"
BonoboB().info() eq "wt: 100.0 age: 12"
}
info() 是 GreatApe 的扩展函数,因此您自然可以在 GreatApe 上调用它。但请注意,您还可以在 Bonobo、Chimpanzee 或 BonoboB 上调用 info()!尽管后三者是不同的类型,Kotlin 仍然会接受它们,就像它们是 GreatApe 的相同类型一样。这适用于继承的任何级别 - BonoboB 距离 GreatApe 有两个继承级别。
继承保证了从 GreatApe 继承的任何内容都是 GreatApe。所有作用于派生类对象的代码都知道 GreatApe 是它们的核心,因此 GreatApe 中的任何函数和属性在其子类中也将可用。
继承使您能够编写一段代码(info() 函数),不仅可以与一个类一起使用,还可以与继承该类的每个类一起使用。因此,继承为代码简化和重用提供了机会。
GreatApe.kt 有些过于简单,因为所有的类都是相同的。当您开始覆盖函数时,继承变得有趣,这意味着在派生类中重新定义基类中的函数以在派生类中执行不同的操作。
让我们看看 GreatApe.kt 的另一个版本。这次我们包括在子类中修改的成员函数:
// Inheritance/GreatApe2.kt
package inheritance.ape2
import atomictest.eq
open class GreatApe {
protected var energy = 0
open fun call() = "Hoo!"
open fun eat() {
energy += 10
}
fun climb(x: Int) {
energy -= x
}
fun energyLevel() = "Energy: $energy"
}
class Bonobo : GreatApe() {
override fun call() = "Eep!"
override fun eat() {
// 修改基类的变量:
energy += 10
// 调用基类的版本:
super.eat()
}
// 添加一个函数:
fun run() = "Bonobo run"
}
class Chimpanzee : GreatApe() {
// 新属性
:
val additionalEnergy = 20
override fun call() = "Yawp!"
override fun eat() {
energy += additionalEnergy
super.eat()
}
// 添加一个函数:
fun jump() = "Chimp jump"
}
fun talk(ape: GreatApe): String {
// ape.run() // 不是 GreatApe 函数
// ape.jump() // 也不是这个
ape.eat()
ape.climb(10)
return "${ape.call()} ${ape.energyLevel()}"
}
fun main() {
// 无法访问 'energy':
// GreatApe().energy
talk(GreatApe()) eq "Hoo! Energy: 0"
talk(Bonobo()) eq "Eep! Energy: 10"
talk(Chimpanzee()) eq "Yawp! Energy: 20"
}
每个 GreatApe 都有一个 call()。它们在吃东西时存储 energy,并在爬行时消耗能量。
如 限制可见性 中所述,派生类无法访问基类的 private 成员。有时,基类的创建者可能希望将特定成员赋予派生类的访问权限,但不授予外界的访问权限。这就是 protected 的作用:protected 成员对外界是封闭的,但可以在子类中访问或覆盖。
如果我们将 energy 声明为 private,则无法在每次使用 GreatApe 时更改它,这是很好的,但我们在子类中也无法访问它。将其设置为 protected 允许我们在子类中保持它可访问,但对外界是不可见的。
call() 在 Bonobo 和 Chimpanzee 中的定义方式与在 GreatApe 中的定义方式相同。它没有参数,类型推断确定其返回一个 String。
Bonobo 和 Chimpanzee 都应该对 call() 有不同的行为,所以我们想要更改它们的 call() 定义。如果您在派生类中创建一个与基类中的函数相同的函数签名,您将用新行为替换基类中定义的行为。这被称为覆盖。
当 Kotlin 在派生类中看到与基类中相同的函数签名时,它会认为您犯了一个错误,这被称为意外覆盖。如果您编写了一个与基类中的函数同名的函数,您会收到一个错误消息,提示您忘记了 override 关键字。Kotlin 假设您无意中选择了相同的名称、参数和返回类型,除非您使用 override 关键字(您首次在 Constructors 中看到过)来表示“是的,我打算这样做。” override 关键字还有助于阅读代码,这样您就不必比较签名来注意覆盖。
Kotlin 在覆盖函数时还施加了额外的约束。就像您不能继承一个基类,除非该基类是 open 的一样,您不能覆盖基类中的函数,除非该函数在基类中被定义为 open。请注意,climb() 和 energyLevel() 都不是 open,因此它们不能被覆盖。在 Kotlin 中,没有明确的意图,就无法实现继承和覆盖。
特别有趣的是,将 Bonobo 或 Chimpanzee 视为普通的 GreatApe 并在 talk() 中进行处理。在 talk() 内部,call() 在每种情况下都会产生正确的行为。talk() 不知何故知道对象的确切类型,并产生适当的 call() 变体。这就是多态性。
在 talk() 内部,您只能调用 GreatApe 的成员函数,因为 talk() 的参数是 GreatApe。即使 Bonobo 定义了 run(),Chimpanzee 定义了 jump(),这两个函数都不是 GreatApe 的一部分。
当您覆盖函数时,通常希望调用基类版本的该函数(一方面是为了重用代码),如在 eat() 的覆盖中所见。这会产生一个困境:如果您简单地调用 eat(),您会调用当前所在的同一个函数(正如我们在递归中所见)。为了调用基类版本的 eat(),请使用 super 关键字,缩写为“superclass”。
练习和解答可以在 www.AtomicKotlin.com 找到。
基类初始化
当一个类继承另一个类时,Kotlin 会保证两个类都得到正确初始化。
Kotlin 通过确保调用构造函数来创建有效的对象:
- 成员对象的构造函数。
- 派生类中新增的对象的构造函数。
- 基类的构造函数。
在继承示例中,基类没有构造函数参数。如果基类有构造函数参数,派生类在构造过程中必须提供这些参数。
以下是第一个带有构造函数参数的 GreatApe 示例,进行了重写:
// BaseClassInit/GreatApe3.kt
package baseclassinit
import atomictest.eq
open class GreatApe(
val weight: Double,
val age: Int
)
open class Bonobo(weight: Double, age: Int) :
GreatApe(weight, age)
class Chimpanzee(weight: Double, age: Int) :
GreatApe(weight, age)
class BonoboB(weight: Double, age: Int) :
Bonobo(weight, age)
fun GreatApe.info() = "wt: $weight age: $age"
fun main() {
GreatApe(100.0, 12).info() eq
"wt: 100.0 age: 12"
Bonobo(110.0, 13).info() eq
"wt: 110.0 age: 13"
Chimpanzee(120.0, 14).info() eq
"wt: 120.0 age: 14"
BonoboB(130.0, 15).info() eq
"wt: 130.0 age: 15"
}
在从 GreatApe 继承时,您必须将必要的构造函数参数传递给 GreatApe 基类,否则将会得到编译时错误消息。
在 Kotlin 为对象创建内存之后,它首先调用基类构造函数,然后调用下一个派生类的构造函数,依此类推,直到达到最派生的构造函数。这样,所有构造函数调用都可以依赖于在它们之前创建的所有子对象的有效性。事实上,这是它所知道的唯一内容;Bonobo 知道它从 GreatApe 继承,并且 Bonobo 构造函数可以调用 GreatApe 类中的函数,但 GreatApe 无法知道它是 Bonobo 还是 Chimpanzee,也无法调用那些子类特定的函数。
在从一个类继承时,您必须在基类名称后面提供基类构造函数的参数。这在对象构造过程中调用基类构造函数:
// BaseClassInit/NoArgConstructor.kt
package baseclassinit
open class SuperClass1(val i: Int)
class SubClass1(i: Int) : SuperClass1(i)
open class SuperClass2
class SubClass2 : SuperClass2()
当基类构造函数没有参数时,Kotlin 仍然需要在基类名称后面加上空括号,以便无参数地调用该构造函数。
如果基类中有辅助构造函数,您可以调用其中一个:
// BaseClassInit/House.kt
package baseclassinit
import atomictest.eq
open class House(
val address: String,
val state: String,
val zip: String
) {
constructor(fullAddress: String) :
this(fullAddress.substringBefore(", "),
fullAddress.substringAfter(", ")
.substringBefore(" "),
fullAddress.substringAfterLast(" "))
val fullAddress: String
get() = "$address, $state $zip"
}
class VacationHouse(
address: String,
state: String,
zip: String,
val startMonth: String,
val endMonth: String
) : House(address, state, zip) {
override fun toString() =
"Vacation house at $fullAddress " +
"from $startMonth to $endMonth"
}
class TreeHouse(
val name: String
) : House("Tree Street, TR 00000") {
override fun toString() =
"$name tree house at $fullAddress"
}
fun main() {
val vacationHouse = VacationHouse(
address = "8 Target St.",
state = "KS",
zip = "66632",
startMonth = "May",
endMonth = "September")
vacationHouse eq
"Vacation house at 8 Target St., " +
"KS 66632 from May to September"
TreeHouse("Oak") eq
"Oak tree house at Tree Street, TR 00000"
}
当 VacationHouse 从 House 继承时,它将适当的参数传递给主要的 House 构造函数。它还添加了自己的参数 startMonth 和 endMonth - 您不受限于基类中参数的数量、类型或顺序。您唯一的责任是在调用基类构造函数时提供正确的参数。
通过在基类构造函数调用中传递匹配的构造函数参数来调用重载的基类构造函数。您可以在 VacationHouse 和 TreeHouse 的定义中看到这一点。每个类都调用不同的基类构造函数。
在派生类的辅助构造函数内部,您可以调用基类构造函数或不同的派生类构造函数:
// BaseClassInit/OtherConstructors.kt
package baseclassinit
import atomictest.eq
open class Base(val i: Int)
class Derived : Base {
constructor(i: Int) : super(i)
constructor() : this(9)
}
fun main() {
val d1 = Derived(11)
d1.i eq 11
val d2 = Derived()
d2.i eq 9
}
要调用基类构造函数,使用 super 关键字,将构造函数参数传递给它,就像调用函数一样。使用 this 调用同一类的另一个构造函数。
练习和解答可以在 www.AtomicKotlin.com 找到。
抽象类
抽象类与普通类类似,只是其中一个或多个函数或属性是不完整的:函数缺少定义,属性没有初始化。接口类似于抽象类,但没有状态。
您必须使用 abstract 修饰符来标记具有缺失定义的类成员。包含 abstract 函数或属性的类也必须标记为 abstract。尝试删除下面任何一个 abstract 修饰符,看看您会得到什么样的消息:
// Abstract/AbstractKeyword.kt
package abstractclasses
abstract class WithProperty {
abstract val x: Int
}
abstract class WithFunctions {
abstract fun f(): Int
abstract fun g(n: Double)
}
WithProperty 使用没有初始化值的方式 声明 了 x(一个 声明 描述了一个东西,但没有提供 定义 来创建存储值的空间或为函数提供代码)。如果没有初始化器,Kotlin 要求引用必须是 abstract,并且期望在类上添加 abstract 修饰符。没有初始化器,Kotlin 无法推断出类型,因此还需要对 abstract 引用提供类型信息。
WithFunctions 声明了 f() 和 g(),但没有提供函数定义,同样强制您向函数和包含类中添加 abstract 修饰符。如果不为函数提供返回类型,就像 g() 那样,Kotlin 会假定它返回 Unit。
抽象函数和属性必须以某种方式在您从抽象类创建的类中存在(变得具体)。
在接口中声明的所有函数和属性默认都是抽象的,这使得接口类似于抽象类。当接口包含函数或属性声明时,abstract 修饰符是多余的,可以删除。这两个接口是等价的:
// Abstract/Redundant.kt
package abstractclasses
interface Redundant {
abstract val x: Int
abstract fun f(): Int
abstract fun g(n: Double)
}
interface Removed {
val x: Int
fun f(): Int
fun g(n: Double)
}
接口和抽象类的区别在于,抽象类可以包含状态,而接口不能。状态是存储在属性内的数据。在以下示例中,IntList 的状态包括存储在属性 name 和 list 中的值。
// Abstract/StateOfAClass.kt
package abstractstate
import atomictest.eq
class IntList(val name: String) {
val list = mutableListOf<Int>()
}
fun main() {
val ints = IntList("numbers")
ints.name eq "numbers"
ints.list += 7
ints.list eq listOf(7)
}
接口可以声明属性,但实际的数据仅存储在实现接口的类中。接口不允许在其属性中存储值:
// Abstract/NoStateInInterfaces.kt
package abstractclasses
interface IntList {
val name: String
// 编译不通过:
// val list = listOf(0)
}
接口和抽象类都可以包含具有实现的函数。您可以从这些函数中调用其他 abstract 成员:
// Abstract/Implementations.kt
package abstractclasses
import atomictest.eq
interface Parent {
val ch: Char
fun f(): Int
fun g() = "ch = $ch; f() = ${f()}"
}
class Actual(
override val ch: Char // [1]
): Parent {
override fun f() = 17 // [2]
}
class Other : Parent {
override val ch: Char // [3]
get() = 'B'
override fun f() = 34 // [4]
}
fun main() {
Actual('A').g() eq "ch = A; f() = 17" // [5]
Other().g() eq "ch = B; f() = 34" // [6]
}
Parent 声明了一个抽象属性 ch 和一个抽象函数 f(),这些在任何实现类中都必须被重写。行 [1]-[4] 展示了在子类中对这些成员的不同实现。
Parent.g() 在定义 g() 时没有定义的抽象成员。接口和抽象类保证在创建任何对象之前,所有抽象属性和函数都得到实现,而且您不能调用一个成员函数,除非您有一个对象。行 [5] 和 [6] 调用了不同实现的 ch 和 f()。
因为接口可以包含函数实现,所以它也可以包含自定义的属性访问器,如果对应的属性不改变状态:
// Abstract/PropertyAccessor.kt
package abstractclasses
import atomictest.eq
interface PropertyAccessor {
val a: Int
get() = 11
}
class Impl : PropertyAccessor
fun main() {
Impl().a eq 11
}
您可能会想知道为什么我们需要接口,当抽象类更强大时。为了理解“没有状态的类”的重要性,让我们来看一下 Kotlin 不支持的多重
继承概念。在 Kotlin 中,一个类只能从一个基类继承:
// Abstract/NoMultipleInheritance.kt
package multipleinheritance1
open class Animal
open class Mammal : Animal()
open class AquaticAnimal : Animal()
// 多个基类不能编译通过:
// class Dolphin : Mammal(), AquaticAnimal()
尝试编译注释掉的代码会产生错误:在 supertype 列表中只能出现一个类。
Java 也是这样工作的。最初的 Java 设计者认为 C++ 的多重继承是一个坏主意。当时的主要复杂性和不满来自于多个状态继承。管理多个状态继承的规则很复杂,很容易引起混淆和令人惊讶的行为。Java 通过引入接口来解决了这个问题,接口不能包含状态。Java 禁止了多个状态继承,但允许多个接口继承,Kotlin 遵循了这个设计:
// Abstract/MultipleInterfaceInheritance.kt
package multipleinheritance2
interface Animal
interface Mammal: Animal
interface AquaticAnimal: Animal
class Dolphin : Mammal, AquaticAnimal
请注意,与类一样,接口也可以彼此继承。
在从多个接口继承时,可以同时覆盖具有相同签名的两个或更多函数(名称与参数和返回类型结合在一起)。如果函数或属性签名冲突,您必须手动解决冲突,如 class C 中所示:
// Abstract/InterfaceCollision.kt
package collision
import atomictest.eq
interface A {
fun f() = 1
fun g() = "A.g"
val n: Double
get() = 1.1
}
interface B {
fun f() = 2
fun g() = "B.g"
val n: Double
get() = 2.2
}
class C : A, B {
override fun f() = 0
override fun g() = super<A>.g()
override val n: Double
get() = super<A>.n + super<B>.n
}
fun main() {
val c = C()
c.f() eq 0
c.g() eq "A.g"
c.n eq 3.3
}
函数 f() 和 g() 以及属性 n 在接口 A 和 B 中具有相同的签名,因此 Kotlin 不知道如何处理,并且如果您不解决此问题,会产生错误消息(尝试逐个注释掉 C 中的定义)。成员函数和属性可以像 f() 中那样通过新定义进行覆盖,但函数也可以使用 super 关键字访问它们的基本版本,使用尖括号指定基类,如 C.g() 和 C.n 的定义中所示。
标识符相同但类型不同的冲突在 Kotlin 中是不允许的,也不能解决。
练习和解答可以在 www.AtomicKotlin.com 找到。
向上转型
将对象引用视为其基础类型引用被称为向上转型。术语向上转型指的是继承层次结构通常以基类位于顶部,派生类从下方分支出的方式。
继承并添加新成员函数是 Smalltalk 的一种实践,它是最早成功的面向对象语言之一。在 Smalltalk 中,一切都是对象,创建类的唯一方法是从现有类继承,通常会添加新的成员函数。Smalltalk 对 Java 产生了很大影响,Java 也要求一切都是对象。
Kotlin 解放了我们的束缚。我们拥有独立的函数,因此不必将所有内容都包含在类中。扩展函数允许我们在不使用继承的情况下添加功能。实际上,要求使用 open 关键字进行继承使得继承成为一个非常明确和有意识的选择,而不是随时都可以使用的东西。
更准确地说,它将继承缩小到一个非常特定的用途,这种抽象允许我们编写可以在单个层次结构内的多个类之间重用的代码。多态性 这一节探讨了这些机制,但首先您必须理解向上转型。
考虑一些可以绘制和擦除的 Shape(形状):
// Upcasting/Shapes.kt
package upcasting
interface Shape {
fun draw(): String
fun erase(): String
}
class Circle : Shape {
override fun draw() = "Circle.draw"
override fun erase() = "Circle.erase"
}
class Square : Shape {
override fun draw() = "Square.draw"
override fun erase() = "Square.erase"
fun color() = "Square.color"
}
class Triangle : Shape {
override fun draw() = "Triangle.draw"
override fun erase() = "Triangle.erase"
fun rotate() = "Triangle.rotate"
}
show() 函数接受任何 Shape:
// Upcasting/Drawing.kt
package upcasting
import atomictest.*
fun show(shape: Shape) {
trace("Show: ${shape.draw()}")
}
fun main() {
listOf(Circle(), Square(), Triangle())
.forEach(::show)
trace eq """
Show: Circle.draw
Show: Square.draw
Show: Triangle.draw
"""
}
在 main() 中,show() 使用三种不同的类型进行了调用:Circle、Square 和 Triangle。show() 参数的基类是 Shape,因此 show() 接受这三种类型。这些类型中的每一个都被视为基本 Shape —— 我们说特定的类型被向上转型为基本类型。
我们通常将绘图层次结构绘制成具有基类的图表:
形状层次结构
当我们将 Circle、Square 或 Triangle 作为 Shape 类型的参数传递给 show() 时,我们向上转型了这个继承层次结构。在向上转型的过程中,我们失去了关于对象是 Circle、Square 还是 Triangle 类型的具体信息。在每种情况下,它不过是一个 Shape 对象而已。
将特定类型视为更一般类型正是继承的全部目的。继承的机制存在的唯一目的就是实现向上转型到基本类型的目标。由于这种抽象(“一切都是 Shape”),我们可以编写一个单一的 show() 函数,而不是为每种类型的元素编写一个函数。向上转型是重用对象代码的一种方式。
实际上,在几乎所有没有向上转型的继承的情况下,继承都被误用了——它是不必要的,会使代码变得复杂。这种误用是以下原则的原因:
优先使用组合而不是继承。
如果继承的目的是能够将派生类型替换为基本类型,那么派生类中的额外成员函数会发生什么情况:Square 中的 color() 和 Triangle 中的 rotate()?
可替代性,也称为 Liskov 替换原则,表示在向上转型后,派生类型可以像基本类型一样被处理 —— 既不多也不少。这意味着添加到派生类的任何成员函数实际上都会“被修剪掉”。它们仍然存在,但因为它们不是基类接口的一部分,所以在 show() 中无法使用它们:
// Upcasting/TrimmedMembers.kt
package upcasting
import atomictest.*
fun trim(shape: Shape) {
trace(shape.draw())
trace(shape.erase())
// 不会编译通过:
// shape.color() // [1]
// shape.rotate() // [2]
}
fun main() {
trim(Square())
trim(Triangle())
trace eq """
Square.draw
Square.erase
Triangle.draw
Triangle.erase
"""
}
您无法在第 [1] 行调用 color(),因为 Square 实例被向上转型为 Shape,并且您无法在第 [2] 行调用 rotate(),因为 Triangle 实例也被向上转型为 Shape。只有那些在 所有 Shape 中都共同存在的成员函数可用 —— 即在基本类型 Shape 中定义
的那些函数。
请注意,当您将 Shape 的子类型直接赋值给一般的 Shape 类型时,也是一样的。指定的类型决定了可用的成员:
// Upcasting/Assignment.kt
import upcasting.*
fun main() {
val shape1: Shape = Square()
val shape2: Shape = Triangle()
// 不会编译通过:
// shape1.color()
// shape2.rotate()
}
向上转型后,只能调用基类的成员。
练习和解答可以在 www.AtomicKotlin.com 找到。
多态性
多态性 是一个古希腊术语,意为“多种形式”。在编程中,多态性意味着一个对象或其成员具有多个实现。
考虑一个简单的 Pet 类型的层次结构。Pet 类表示所有的宠物都可以 speak()(说话)。Dog 和 Cat 覆盖了 speak() 成员函数:
// Polymorphism/Pet.kt
package polymorphism
import atomictest.eq
open class Pet {
open fun speak() = "Pet"
}
class Dog : Pet() {
override fun speak() = "Bark!"
}
class Cat : Pet() {
override fun speak() = "Meow"
}
fun talk(pet: Pet) = pet.speak()
fun main() {
talk(Dog()) eq "Bark!" // [1]
talk(Cat()) eq "Meow" // [2]
}
注意 talk() 函数的参数。当将 Dog 或 Cat 传递给 talk() 时,具体类型被遗忘,变成了一个普通的 Pet —— 既 Dog 和 Cat 都被向上转型为 Pet。现在,这些对象被视为普通的 Pet,那么行 [1] 和 [2] 中的输出应该都是 "Pet",对吗?
talk() 不知道它接收到的 Pet 的确切类型。尽管如此,在通过基类 Pet 的引用调用 speak() 时,会调用正确的子类实现,并获得所需的行为。
多态性发生在父类引用包含子类实例时。当您在父类引用上调用成员时,多态性会从子类中产生正确的重写成员。
将函数调用与函数体连接在一起称为绑定。通常情况下,您不会对绑定多想,因为它在编译时静态地发生。在多态性中,相同的操作必须对不同的类型产生不同的行为 —— 但编译器无法提前知道要使用哪个函数体。函数体必须在运行时动态确定,使用动态绑定。动态绑定也称为晚期绑定或动态调度。只有在运行时,Kotlin 才能确定要调用的确切 speak() 函数。因此,我们说多态性调用 pet.speak() 的绑定是动态发生的。
考虑一个幻想游戏。游戏中的每个 Character 都有一个 name,并且可以 play()。我们将 Fighter 和 Magician 结合起来来构建特定的角色:
// Polymorphism/FantasyGame.kt
package polymorphism
import atomictest.*
abstract class Character(val name: String) {
abstract fun play(): String
}
interface Fighter {
fun fight() = "Fight!"
}
interface Magician {
fun doMagic() = "Magic!"
}
class Warrior :
Character("Warrior"), Fighter {
override fun play() = fight()
}
open class Elf(name: String = "Elf") :
Character(name), Magician {
override fun play() = doMagic()
}
class FightingElf :
Elf("FightingElf"), Fighter {
override fun play() =
super.play() + fight()
}
fun Character.playTurn() = // [1]
trace(name + ": " + play()) // [2]
fun main() {
val characters: List<Character> = listOf(
Warrior(), Elf(), FightingElf()
)
characters.forEach { it.playTurn() } // [3]
trace eq """
Warrior: Fight!
Elf: Magic!
FightingElf: Magic!Fight!
"""
}
在 main() 中,每个对象在放入 List 时都会向上转型为 Character。trace 显示了在 List 中的每个 Character 上调用 playTurn() 会产生不同的输出。
playTurn() 是基类 Character 上的扩展函数。当在行 [3] 中调用它时,它是静态绑定的,这意味着要调用的确切函数在编译时确定。在行 [3] 中,编译器确定只有一个 playTurn() 函数实现 —— 就是在行 [1] 上定义的那个。
当编译器分析行 [2] 中的 play() 函数调用时,它不知道要使用哪个函数实现。如果 Character 是一个 Elf,它必须调用 Elf 的 play()。如果 Character 是一个 FightingElf,它必须调用 FightingElf 的 play()。它还可能需要调用一个尚未定义的子类函数。函数绑定在每次调用时都会有所不同。在编译时,唯一确定的是行 [2] 中的 play() 是 Character 子类的成员函数。具体的子类只能在运行时根据实际的 Character 类型来确定。
- -
动态绑定是不是免费的。决定运行时类型的额外逻辑会对性能产生轻微的影响,与静态绑定相比。为了强制清晰,Kotlin 默认为封闭的类和成员函数。要继承和重写,必须明确指定。
像 when 语句这样的语言特性可以独立学习。多态性不可以 —— 它只在协调中工作,作为类关系的更大画面的一部分。为了有效地使用面向对象的技术,您必须扩展您的视角,不仅包括个体类的成员,还包括类之间的共性以及它们相互之间的关系。
***练
习和解答可以在 www.AtomicKotlin.com 找到。***
组合
面向对象编程最具有吸引力的一个论点是代码重用。
你可能最初会将“重用”理解为“复制代码”。复制似乎是一个简单的解决方案,但它效果不是很好。随着时间的推移,您的需求会发生变化。对已复制的代码应用更改会变成一个维护噩梦。您是否找到了所有的副本?您是否以相同的方式对每个副本进行了更改?通过重用的代码,您只需要在一个地方进行更改。
在面向对象编程中,通过创建新类来重用代码,但与其从头开始创建新类,不如使用其他人已经构建和调试过的现有类。关键在于在不污染现有代码的情况下使用这些类。
继承是实现这一点的一种方式。继承将一个新类创建为现有类的类型。您可以向现有类的形式添加代码,而无需修改原始类。继承是面向对象编程的基石。
您还可以选择更直接的方法,通过在新类内部创建现有类的对象。这称为组合,因为新类由现有类的对象组成。您正在重用代码的功能,而不是其形式。
本书中经常使用组合。组合经常被忽视,因为它似乎如此简单 —— 您只需将一个对象放在一个类中。
组合是一种有一个的关系。 “一个房子 是一个 建筑物并且 有一个 厨房” 可以这样表示:
// Composition/House1.kt
package composition1
interface Building
interface Kitchen
interface House: Building {
val kitchen: Kitchen
}
继承描述了一个是一个的关系,通常有助于将描述大声朗读出来:“一个房子是一个建筑物。” 这听起来是正确的,不是吗?当是一个关系有意义时,继承通常是合理的。
如果您的房子有两个厨房,组合可以提供一个简单的解决方案:
// Composition/House2.kt
package composition2
interface Building
interface Kitchen
interface House: Building {
val kitchen1: Kitchen
val kitchen2: Kitchen
}
要允许任意数量的厨房,使用带有集合的组合:
// Composition/House3.kt
package composition3
interface Building
interface Kitchen
interface House: Building {
val kitchens: List<Kitchen>
}
我们花费时间和精力来理解继承,因为它更复杂,而且这种复杂性可能会给人一种它在某种程度上更重要的印象。相反:
优先选择组合而不是继承。
组合会产生更简单的设计和实现。这并不意味着您应该避免继承。只是我们往往陷入了更复杂的关系中。优先选择组合而不是继承 这一原则提醒我们要退后一步,看看我们的设计,思考是否可以通过组合来简化它。最终的目标是正确应用您的工具并产生一个良好的设计。
组合似乎很琐碎,但却很强大。当一个类增长并且负责不同的不相关的事情时,组合有助于将它们分开。使用组合来简化类的复杂逻辑。
在组合和继承之间选择
组合和继承都会将子对象放置在您的新类内部 —— 组合具有显式的子对象,而继承具有隐式的子对象。何时选择其中之一?
组合提供了现有类的功能,但不包括其接口。您嵌入一个对象以在新类中使用其功能,但用户看到的是您为新类定义的接口,而不是嵌入对象的接口。为了完全隐藏对象,将其私有嵌入:
// Composition/Embedding.kt
package composition
class Features {
fun f1() = "feature1"
fun f2() = "feature2"
}
class Form {
private val features = Features()
fun operation1() =
features.f2() + features.f1()
fun operation2() =
features.f1() + features.f2()
}
Features 类为 Form 的操作提供了实现,但使用 Form 的客户程序员无法访问 features —— 实际上,用户对于 Form 的实现方式是无感知的。这意味着,如果您找到了一种更好的实现 Form 的方法,可以删除 features 并更改为新的方法,而不会影响调用 Form 的代码。
如果 Form 继承了 Features,客户程序员可能会期望将 Form 向上转型为 Features。继承关系随后成为 Form 的一部分 —— 这种联系是显式的。如果您改变了这一点,会破坏依赖于该连接的代码。
有时候,允许类用户直接访问您的新类的组合是有意义的;也就是说,使成员对象变为公开。这是相对安全的,假设成员对象使用了适当的实现隐藏。对于某些系统,这种方法可以使接口更易于理解。考虑一个 Car:
// Composition/Car.kt
package composition
import atomictest.*
class Engine {
fun start() = trace("
Engine start")
fun stop() = trace("Engine stop")
}
class Wheel {
fun inflate(psi: Int) =
trace("Wheel inflate($psi)")
}
class Window(val side: String) {
fun rollUp() =
trace("$side Window roll up")
fun rollDown() =
trace("$side Window roll down")
}
class Door(val side: String) {
val window = Window(side)
fun open() = trace("$side Door open")
fun close() = trace("$side Door close")
}
class Car {
val engine = Engine()
val wheel = List(4) { Wheel() }
// 两扇门:
val leftDoor = Door("left")
val rightDoor = Door("right")
}
fun main() {
val car = Car()
car.leftDoor.open()
car.rightDoor.window.rollUp()
car.wheel[0].inflate(72)
car.engine.start()
trace eq """
left Door open
right Window roll up
Wheel inflate(72)
Engine start
"""
}
Car 的组合是问题分析的一部分,而不仅仅是底层实现的一部分。这有助于客户程序员理解如何使用类,同时也需要更少的代码复杂性来创建类。
当您继承时,您会为现有类创建一个定制版本。这将一个通用的类专门用于满足特定的需求。在这个示例中,使用一个 Vehicle 类来构建一个新类 Car 是没有意义的 —— Car 不是 包含 Vehicle,而是 是 一个 Vehicle。继承关系通过继承来表达,而有一个关系通过组合来表达。
多态的巧妙之处可能使人们觉得一切都应该继承。这将使您的设计变得繁琐。实际上,当您在使用现有类来构建新类时,首先选择组合可能会使事情变得不必要地复杂。更好的方法是首先尝试组合,尤其是当不清楚哪种方法最适合时。
习题和解答可以在 www.AtomicKotlin.com 找到。
继承与扩展
有时候继承被用来为一个类添加函数,以便为其重新赋予新的目标。这可能会导致难以理解和维护的代码。
假设有人已经创建了一个名为 Heater 的类,以及一些作用于 Heater 的函数:
// InheritanceExtensions/Heater.kt
package inheritanceextensions
import atomictest.eq
open class Heater {
fun heat(temperature: Int) =
"heating to $temperature"
}
fun warm(heater: Heater) {
heater.heat(70) eq "heating to 70"
}
为了论证,想象一下 Heater 实际上比这个复杂得多,而且还有许多类似 warm() 的辅助函数。我们不想修改这个库 —— 我们想要按原样重用它。
如果我们实际上想要的是一个 HVAC(供暖、通风和空调)系统,我们可以继承 Heater 并添加一个 cool() 函数。现有的 warm() 函数以及所有作用于 Heater 的其他函数,仍然可以在我们的新类型 HVAC 上工作 —— 这在使用组合的情况下是不成立的:
// InheritanceExtensions/InheritAdd.kt
package inheritanceextensions
import atomictest.eq
class HVAC : Heater() {
fun cool(temperature: Int) =
"cooling to $temperature"
}
fun warmAndCool(hvac: HVAC) {
hvac.heat(70) eq "heating to 70"
hvac.cool(60) eq "cooling to 60"
}
fun main() {
val heater = Heater()
val hvac = HVAC()
warm(heater)
warm(hvac)
warmAndCool(hvac)
}
这看起来很实用:Heater 没有完全满足我们的要求,所以我们从 Heater 继承了 HVAC 并附加了另一个函数。
正如您在向上转型中所见,面向对象语言具有处理继承过程中添加的成员函数的机制:在向上转型期间会去除添加的函数,使其在基类中不可用。这就是 里氏替换原则,也被称为“可替代性”,它表示接受基类的函数必须能够在不知道的情况下使用派生类的对象。可替代性是为什么 warm() 仍然在 HVAC 上起作用的原因。
尽管现代面向对象编程允许在继承过程中添加函数,但这可能是一种“代码异味”——它似乎是合理和迅速的,但可能会让您陷入麻烦。只因为它似乎有效并不意味着它是一个好主意。特别是,它可能会对以后维护代码的人(可能是您自己)产生负面影响。这种问题称为技术债务。
在继承过程中添加函数在新类在整个系统中被严格视为基类时可能会很有用,而忽略了它有自己的基类。在类型检查中,您将看到在继承过程中添加函数可以是一种可行的技术。
当我们在创建 HVAC 类时,我们实际上想要的是一个带有附加 cool() 函数的 Heater 类,以便它能在 warmAndCool() 中使用。这正是扩展函数所做的事情,而无需继承:
// InheritanceExtensions/ExtensionFuncs.kt
package inheritanceextensions2
import inheritanceextensions.Heater
import atomictest.eq
fun Heater.cool(temperature: Int) =
"cooling to $temperature"
fun warmAndCool(heater: Heater) {
heater.heat(70) eq "heating to 70"
heater.cool(60) eq "cooling to 60"
}
fun main() {
val heater = Heater()
warmAndCool(heater)
}
扩展函数不同于继承来扩展基类接口,扩展函数直接扩展基类接口,而无需继承。
如果我们对 Heater 库有控制权,我们可以以不同的方式进行设计,使其更灵活:
// InheritanceExtensions/TemperatureDelta.kt
package inheritanceextensions
import atomictest.*
class TemperatureDelta(
val current: Double,
val target: Double
)
fun TemperatureDelta.heat() {
if (current < target)
trace("heating to $target")
}
fun TemperatureDelta.cool() {
if (current > target)
trace("cooling to $target")
}
fun adjust(deltaT: TemperatureDelta) {
deltaT.heat()
deltaT.cool()
}
fun main() {
adjust(TemperatureDelta(60.0, 70.0))
adjust(TemperatureDelta(80.0, 60.0))
trace eq """
heating to 70.0
cooling to 60.0
"""
}
在这种方法中,我们通过在多个策略中进行选择来控制温度。我们也可以将 heat() 和 cool() 设计为成员函数,而不是扩展函数。
按约定的接口
扩展函数可以被认为是创建包含单个函数的接口:
// InheritanceExtensions/Convention.kt
package inheritanceextensions
class X
fun X.f() {}
class Y
fun Y.f() {}
fun callF(x: X) = x.f()
fun callF(y: Y) = y.f()
fun main() {
val x = X()
val y = Y()
x.f()
y.f()
callF(x)
callF(y)
}
现在 `X
和Y都表现得好像有一个名为f()的成员函数,但我们没有获得多态行为,所以我们必须重载callF()` 以使其适用于两种类型。
这种“按约定的接口”在 Kotlin 库中被广泛使用,尤其是在处理集合时。尽管这些主要是 Java 集合,但 Kotlin 库通过添加大量的扩展函数将它们变成了函数式风格的集合。例如,在几乎任何类似集合的对象上,您都可以找到 map() 和 reduce() 等函数。由于程序员对这个约定产生了期望,这使得编程变得更容易。
Kotlin 标准库的 Sequence 接口只包含一个成员函数。其他 Sequence 函数都是 扩展函数 —— 超过一百个。最初,这种方法用于与 Java 集合兼容,但现在它是 Kotlin 哲学的一部分:创建一个只包含定义其本质的方法的简单接口,然后将所有辅助操作都作为扩展添加进来。
适配器模式
一个库通常会定义一个类型,并提供接受该类型参数和/或返回该类型的函数:
// InheritanceExtensions/UsefulLibrary.kt
package usefullibrary
interface LibType {
fun f1()
fun f2()
}
fun utility1(lt: LibType) {
lt.f1()
lt.f2()
}
fun utility2(lt: LibType) {
lt.f2()
lt.f1()
}
要使用这个库,您必须以某种方式将现有的类转换为 LibType。在这里,我们从现有的 MyClass 继承,产生 MyClassAdaptedForLib,它实现了 LibType,因此可以传递给 UsefulLibrary.kt 中的函数:
// InheritanceExtensions/Adapter.kt
package inheritanceextensions
import usefullibrary.*
import atomictest.*
open class MyClass {
fun g() = trace("g()")
fun h() = trace("h()")
}
fun useMyClass(mc: MyClass) {
mc.g()
mc.h()
}
class MyClassAdaptedForLib :
MyClass(), LibType {
override fun f1() = h()
override fun f2() = g()
}
fun main() {
val mc = MyClassAdaptedForLib()
utility1(mc)
utility2(mc)
useMyClass(mc)
trace eq "h() g() g() h() g() h()"
}
尽管这确实在继承过程中扩展了一个类,但新的成员函数仅仅用于适应 UsefulLibrary。请注意,除此之外,在 MyClassAdaptedForLib 的任何地方,MyClassAdaptedForLib 的对象都可以被当作 MyClass 对象来处理,就像在调用 useMyClass() 中一样。没有代码使用扩展的 MyClassAdaptedForLib,其中基类的使用者必须知道派生类的情况。
Adapter.kt 依赖于 MyClass 被声明为 open 以供继承。如果您无法控制 MyClass,并且它不是 open,那怎么办?幸运的是,适配器也可以使用组合构建。在这里,我们在 MyClassAdaptedForLib 中添加一个 MyClass 字段:
// InheritanceExtensions/ComposeAdapter.kt
package inheritanceextensions2
import usefullibrary.*
import atomictest.*
class MyClass { // 不是 open
fun g() = trace("g()")
fun h() = trace("h()")
}
fun useMyClass(mc: MyClass) {
mc.g()
mc.h()
}
class MyClassAdaptedForLib : LibType {
val field = MyClass()
override fun f1() = field.h()
override fun f2() = field.g()
}
fun main() {
val mc = MyClassAdaptedForLib()
utility1(mc)
utility2(mc)
useMyClass(mc.field)
trace eq "h() g() g() h() g() h()"
}
这不像 Adapter.kt 那样清晰 —— 在调用 useMyClass(mc.field) 中,您必须显式地访问 MyClass 对象。但它仍然很好地解决了适应库的问题。
扩展函数似乎非常适合创建适配器。不幸的是,您不能通过收集扩展函数来实现接口。
成员函数与扩展函数
有些情况下,您被迫使用成员函数而不是扩展函数。如果一个函数必须访问一个 private 成员,您别无选择,只能将其作为成员函数:
// InheritanceExtensions/PrivateAccess.kt
package inheritanceextensions
import atomictest.eq
class Z(var i: Int = 0) {
private var j = 0
fun increment() {
i++
j++
}
}
fun Z.decrement() {
i--
// j -- // 无法访问
}
成员函数 increment() 可以操作 j,但扩展函数 decrement() 无法访问 j,因为 j 是 private 的。
扩展函数最大的限制是它们无法被覆盖:
// InheritanceExtensions/NoExtOverride.kt
package inheritanceextensions
import atomictest.*
open class Base {
open fun f() = "Base.f()"
}
class Derived : Base() {
override fun f() = "Derived.f()"
}
fun Base.g() = "Base.g()"
fun Derived.g() = "Derived.g()"
fun useBase(b: Base) {
trace("Received ${b::class.simpleName}")
trace(b.f())
trace(b.g())
}
fun main() {
useBase(Base())
useBase(Derived())
trace eq """
Received Base
Base.f()
Base.g()
Received Derived
Derived.f()
Base.g()
"""
}
trace 输出显示,多态在成员函数 f() 中起作用,但在扩展函数 g() 中则不起作用。
当一个函数不需要覆盖,并且您对类的成员有足够的访问权限时,可以将其定义为成员函数或扩展函数 —— 这是一种应该最大程度地增加代码清晰度的风格选择。
成员函数反映了类型的本质;您不能想象没有该函数的类型。扩展函数表示支持或利用该类型的“辅助”或“方便”操作,但不一定是该类型存在的必要条件。将辅助函数包含在类型内部会增加其可推理性,而将某些函数定义为扩展则使类型保持简洁和简单。
考虑一个 Device 接口。model 和 productionYear 属性对于 Device 来说是固有的,因为它们描述了关键特征。诸如 overpriced() 和 outdated() 之类的函数可以被定义为接口的成员,也可以定义为扩
展函数。在这里,它们被定义为接口的成员函数:
// InheritanceExtensions/DeviceMembers.kt
package inheritanceextensions1
import atomictest.eq
interface Device {
val model: String
val productionYear: Int
fun overpriced() = model.startsWith("i")
fun outdated() = productionYear < 2050
}
class MyDevice(
override val model: String,
override val productionYear: Int
): Device
fun main() {
val gadget: Device =
MyDevice("my first phone", 2000)
gadget.outdated() eq true
gadget.overpriced() eq false
}
如果我们假设 overpriced() 和 outdated() 不会在子类中被覆盖,它们可以被定义为扩展函数:
// InheritanceExtensions/DeviceExtensions.kt
package inheritanceextensions2
import atomictest.eq
interface Device {
val model: String
val productionYear: Int
}
fun Device.overpriced() =
model.startsWith("i")
fun Device.outdated() =
productionYear < 2050
class MyDevice(
override val model: String,
override val productionYear: Int
): Device
fun main() {
val gadget: Device =
MyDevice("my first phone", 2000)
gadget.outdated() eq true
gadget.overpriced() eq false
}
只包含描述性成员的接口更容易理解和推理,因此第二个示例中的 Device 接口可能是一个更好的选择。然而,这最终是一个设计决策。
- -
像 C++ 和 Java 这样的语言允许继承,除非您明确禁止。Kotlin 假设您 不会 使用继承 —— 它在不明确使用 open 关键字的情况下主动阻止继承和多态。这提供了有关 Kotlin 取向的见解:
通常,函数是您需要的一切。有时对象非常有用。对象是众多工具中的一个,但它们并不是万能的。
如果您在考虑如何在特定情况下使用继承,考虑是否真的需要继承,并应用 优先使用扩展函数和组合而不是继承(改编自书籍 设计模式)。
类委托
组合和继承都将子对象放置在新类中。使用组合时,子对象是显式的;使用继承时,子对象是隐式的。
组合使用嵌入对象的功能,但不暴露其接口。如果一个类需要重用现有实现并实现其接口,您有两个选择:继承和类委托。
类委托位于继承和组合之间。与组合类似,您将一个成员对象放置在正在构建的类中。与继承类似,类委托暴露了子对象的接口。此外,您可以向上转型为成员类型。对于代码重用,类委托使得组合具有与继承相同的强大功能。
如果没有语言支持,您将如何实现这一点?在这里,一个太空飞船需要一个控制模块:
// ClassDelegation/SpaceShipControls.kt
package classdelegation
interface Controls {
fun up(velocity: Int): String
fun down(velocity: Int): String
fun left(velocity: Int): String
fun right(velocity: Int): String
fun forward(velocity: Int): String
fun back(velocity: Int): String
fun turboBoost(): String
}
class SpaceShipControls : Controls {
override fun up(velocity: Int) =
"up $velocity"
override fun down(velocity: Int) =
"down $velocity"
override fun left(velocity: Int) =
"left $velocity"
override fun right(velocity: Int) =
"right $velocity"
override fun forward(velocity: Int) =
"forward $velocity"
override fun back(velocity: Int) =
"back $velocity"
override fun turboBoost() = "turbo boost"
}
如果我们想要扩展控制的功能或调整一些命令,我们可能会尝试从 SpaceShipControls 继承。但这不起作用,因为 SpaceShipControls 不是 open。
要暴露 Controls 中的成员函数,您可以创建一个 SpaceShipControls 的实例作为属性,并将所有暴露的成员函数显式地委托给该实例:
// ClassDelegation/ExplicitDelegation.kt
package classdelegation
import atomictest.eq
class ExplicitControls : Controls {
private val controls = SpaceShipControls()
// 手动委托:
override fun up(velocity: Int) =
controls.up(velocity)
override fun back(velocity: Int) =
controls.back(velocity)
override fun down(velocity: Int) =
controls.down(velocity)
override fun forward(velocity: Int) =
controls.forward(velocity)
override fun left(velocity: Int) =
controls.left(velocity)
override fun right(velocity: Int) =
controls.right(velocity)
// 修改的实现:
override fun turboBoost(): String =
controls.turboBoost() + "... boooooost!"
}
fun main() {
val controls = ExplicitControls()
controls.forward(100) eq "forward 100"
controls.turboBoost() eq
"turbo boost... boooooost!"
}
这些函数被转发到底层的 controls 对象,由于生成的接口与普通继承的接口相同,因此结果也相同。您还可以提供实现更改,就像 turboBoost() 一样。
Kotlin 自动化了类委托的过程,因此与 ExplicitDelegation.kt 中编写的显式函数实现不同,您只需指定一个要用作委托的对象。
要委托给一个类,请在接口名称后面放置 by 关键字,然后是要用作委托的成员属性:
// ClassDelegation/BasicDelegation.kt
package classdelegation
interface AI
class A : AI
class B(val a: A) : AI by a
将其阅读为“类 B 通过使用成员对象 a 来实现接口 AI”。您只能委托给接口,所以不能说 A by a。委托对象(a)必须是构造函数的参数。
现在,ExplicitDelegation.kt 可以使用 by 进行重写:
// ClassDelegation/DelegatedControls.kt
package classdelegation
import atomictest.eq
class DelegatedControls(
private val controls: SpaceShipControls =
SpaceShipControls()
): Controls by controls {
override fun
turboBoost(): String =
"${controls.turboBoost()}... boooooost!"
}
fun main() {
val controls = DelegatedControls()
controls.forward(100) eq "forward 100"
controls.turboBoost() eq
"turbo boost... boooooost!"
}
当 Kotlin 看到 by 关键字时,它会生成与我们为 ExplicitDelegation.kt 编写的代码类似的代码。委托后,可以通过外部对象访问成员对象的函数,而无需编写所有额外的代码。
Kotlin 不支持多类继承,但可以使用类委托模拟它。通常,多继承用于组合具有完全不同功能的类。例如,假设您想通过将在屏幕上绘制矩形的类与管理鼠标事件的类结合起来,来生成一个按钮:
// ClassDelegation/ModelingMI.kt
package classdelegation
import atomictest.eq
interface Rectangle {
fun paint(): String
}
class ButtonImage(
val width: Int,
val height: Int
): Rectangle {
override fun paint() =
"painting ButtonImage($width, $height)"
}
interface MouseManager {
fun clicked(): Boolean
fun hovering(): Boolean
}
class UserInput : MouseManager {
override fun clicked() = true
override fun hovering() = true
}
// 即使我们将类定义为 open,我们
// 仍会得到一个错误,因为一个超类列表中只能出现一个类:
// class Button : ButtonImage(), UserInput()
class Button(
val width: Int,
val height: Int,
var image: Rectangle =
ButtonImage(width, height),
private var input: MouseManager = UserInput()
): Rectangle by image, MouseManager by input
fun main() {
val button = Button(10, 5)
button.paint() eq
"painting ButtonImage(10, 5)"
button.clicked() eq true
button.hovering() eq true
// 可以向上转型为两种委托类型:
val rectangle: Rectangle = button
val mouseManager: MouseManager = button
}
类 Button 实现了两个接口:Rectangle 和 MouseManager。它不能继承 ButtonImage 和 UserInput 的实现,但它可以委托给它们两个。
请注意,构造函数参数列表中的 image 的定义既是 public 又是 var。这允许客户程序员动态替换 ButtonImage。
main() 中的最后两行显示了 Button 可以向上转型为其两种委托类型。这就是多继承的目标,因此委托有效地解决了多继承的需求。
- -
继承可能会受到限制。例如,如果超类不是 open,或者如果您的新类已经扩展了另一个类,您无法继承一个类。类委托使您摆脱了这些和其他限制。
谨慎使用类委托。在继承、组合和类委托这三个选择中,首先尝试组合。这是最简单的方法,可以解决大多数用例。在需要创建类型层次结构以在类型之间建立关系时,继承是必需的。当这些选项不适用时,类委托可以发挥作用。
练习和解答可以在 www.AtomicKotlin.com 找到。
向下转型
向下转型 发现先前向上转型的对象的特定类型。
向上转型总是安全的,因为基类不能具有比派生类更大的接口。每个基类成员都有保证存在,并且因此可以安全调用。尽管面向对象编程主要专注于向上转型,但在某些情况下,向下转型可能是一种有用且方便的方法。
向下转型发生在运行时,也称为运行时类型标识(RTTI)。
考虑一个类层次结构,其中基类型的接口比派生类型更窄。如果将对象向上转型为基类型,则编译器不再知道具体类型。特别是,它无法知道可以安全调用哪些扩展函数:
// DownCasting/NarrowingUpcast.kt
package downcasting
interface Base {
fun f()
}
class Derived1 : Base {
override fun f() {}
fun g() {}
}
class Derived2 : Base {
override fun f() {}
fun h() {}
}
fun main() {
val b1: Base = Derived1() // 向上转型
b1.f() // Base 的一部分
// b1.g() // 不是 Base 的一部分
val b2: Base = Derived2() // 向上转型
b2.f() // Base 的一部分
// b2.h() // 不是 Base 的一部分
}
要解决这个问题,必须有一些方法来确保向下转型是正确的,这样您不会意外地将其转换为错误的类型并调用不存在的成员。
智能类型转换
在 Kotlin 中,智能类型转换是自动向下转型。关键字 is 检查对象是否为特定类型。在该检查的范围内,任何代码都会假定它是该类型:
// DownCasting/IsKeyword.kt
import downcasting.*
fun main() {
val b1: Base = Derived1() // 向上转型
if(b1 is Derived1)
b1.g() // 在 "is" 检查的范围内
val b2: Base = Derived2() // 向上转型
if(b2 is Derived2)
b2.h() // 在 "is" 检查的范围内
}
如果 b1 的类型是 Derived1,则可以调用 g()。如果 b2 的类型是 Derived2,则可以调用 h()。
智能类型转换在 when 表达式内尤其有用,该表达式使用 is 来搜索 when 参数的类型。注意,在 main() 中,每个特定类型首先被向上转型为 Creature,然后传递给 what():
// DownCasting/Creature.kt
package downcasting
import atomictest.eq
interface Creature
class Human : Creature {
fun greeting() = "I'm Human"
}
class Dog : Creature {
fun bark() = "Yip!"
}
class Alien : Creature {
fun mobility() = "Three legs"
}
fun what(c: Creature): String =
when (c) {
is Human -> c.greeting()
is Dog -> c.bark()
is Alien -> c.mobility()
else -> "Something else"
}
fun main() {
val c: Creature = Human()
what(c) eq "I'm Human"
what(Dog()) eq "Yip!"
what(Alien()) eq "Three legs"
class Who : Creature
what(Who()) eq "Something else"
}
在 main() 中,向上转型发生在将 Human 赋给 Creature、将 Dog 传递给 what()、将 Alien 传递给 what() 以及将 Who 传递给 what()。
类层次结构通常在基类在顶部,派生类在其下方的方式下进行绘制。what() 接受先前向上转型的 Creature 并发现其确切类型,因此将该 Creature 对象向下转换到继承层次结构中,从更通用的基类到更特定的派生类。
when 表达式生成一个值时,需要一个 else 分支来捕获所有剩余的可能性。在 main() 中,使用局部类 Who 的实例来测试 else 分支。
when 的每个分支都使用 c,好像它是我们检查的类型:如果 c 是 Human,则调用 greeting();如果它是 Dog,则调用 bark();如果它是 Alien,则调用 mobility()。
可修改的引用
自动向下转型受到特殊约束。如果对对象的基类引用是可修改的(一个 var),那么在检测类型和在调用向下转型对象上的特定函数之间,有可能将此引用分配给不同的对象。也就是说,在类型检测和使用之间,对象的具体类型可能会发生变化。
在以下示例中,c 是 when 的参数,Kotlin 坚持要求该参数是不可变的,以便在 is 表达式和 -> 后面的调用之间不能更改它:
// DownCasting/MutableSmartCast.kt
package downcasting
class SmartCast1(val c: Creature) {
fun contact() {
when (c) {
is Human -> c.greeting()
is Dog -> c.bark()
is Alien -> c.mobility()
}
}
}
class SmartCast2(var c: Creature) {
fun contact() {
when (val c = c) { // [1]
is Human -> c.greeting() // [2]
is Dog -> c.bark()
is Alien -> c.mobility()
}
}
}
在 SmartCast1 中,构造函数参数 `c
是一个val,在 SmartCast2中是一个var。在两种情况下,c都传递到when` 表达式,该表达式使用一系列智能类型转换。
在 [1] 中,表达式 val c = c 看起来有些奇怪,只是在这里出于方便才使用——我们不建议在正常代码中“遮蔽”标识符名称。val c 创建一个新的局部标识符 c,用于捕获属性 c 的值。然而,属性 c 是一个 var,而局部(遮蔽)c 是一个 val。尝试移除 val c =。这意味着现在 c 将成为属性,即一个 var。这将导致 [2] 处产生错误消息:
- 智能转换到 'Human' 是不可能的,因为 'c' 是一个可变属性,可能在此时被更改
is Dog 和 is Alien 会产生类似的消息。这不仅限于 while 表达式;还有其他情况也会产生相同的错误消息。
错误消息中描述的更改通常是通过并发发生的,当多个独立任务有机会在不可预测的时间更改 c 时。(并发是一个高级主题,我们在本书中不涵盖该主题)。
Kotlin 强制我们确保在执行类型检查和使用向下转型类型之间不会更改 c。SmartCast1 通过使属性 c 成为 val 来实现这一点,而 SmartCast2 则通过引入局部的 val c 来实现。
同样地,复杂表达式不能智能转换,因为表达式可能会重新评估。对于可继承的 open 属性,不能进行智能转换,因为其值可能会在子类中被覆盖,因此不能保证在下一次访问时值将保持相同。
as 关键字
as 关键字将一个通用类型强制转换为特定类型:
// DownCasting/Unsafe.kt
package downcasting
import atomictest.*
fun dogBarkUnsafe(c: Creature) =
(c as Dog).bark()
fun dogBarkUnsafe2(c: Creature): String {
c as Dog
c.bark()
return c.bark() + c.bark()
}
fun main() {
dogBarkUnsafe(Dog()) eq "Yip!"
dogBarkUnsafe2(Dog()) eq "Yip!Yip!"
(capture {
dogBarkUnsafe(Human())
}) contains listOf("ClassCastException")
}
dogBarkUnsafe2() 显示了 as 的第二种形式:如果说 c as Dog,那么在作用域的其余部分中,c 将被视为 Dog。
失败的 as 转换会抛出 ClassCastException。普通的 as 被称为不安全的转换。
当 安全转换 as? 失败时,它不会抛出异常,而是返回 null。然后,您必须合理地处理该 null,以防止后续出现 NullPointerException。Elvis 运算符(在 安全调用与 Elvis 运算符 中描述)通常是最直接的方法:
// DownCasting/Safe.kt
package downcasting
import atomictest.eq
fun dogBarkSafe(c: Creature) =
(c as? Dog)?.bark() ?: "Not a Dog"
fun main() {
dogBarkSafe(Dog()) eq "Yip!"
dogBarkSafe(Human()) eq "Not a Dog"
}
如果 c 不是 Dog,则 as? 会产生一个 null。因此,(c as? Dog) 是一个可空表达式,我们必须使用安全调用运算符 ?. 来调用 bark()。如果 as? 产生一个 null,那么整个表达式 (c as? Dog)?.bark() 也将产生一个 null,Elvis 运算符通过生成 "Not a Dog" 来处理这个 null。
在列表中发现类型
当在谓词中使用时,is 可以在 List 或任何可迭代对象(可以迭代的对象)中查找特定类型的对象:
// DownCasting/FindType.kt
package downcasting
import atomictest.eq
val group: List<Creature> = listOf(
Human(), Human(), Dog(), Alien(), Dog()
)
fun main() {
val dog = group
.find { it is Dog } as Dog? // [1]
dog?.bark() eq "Yip!" // [2]
}
因为 group 包含 Creature,所以 find() 返回一个 Creature。我们希望将其视为 Dog,因此我们在第 [1] 行显式地将其转换。在 group 中可能没有 Dog,在这种情况下,find() 返回一个 null,因此我们必须将结果转换为可空的 Dog?。因为 dog 是可空的,所以我们在第 [2] 行使用安全调用运算符。
通常可以通过使用 filterIsInstance() 来避免第 [1] 行中的代码,它可以生成特定类型的所有元素:
// DownCasting/FilterIsInstance.kt
import downcasting.*
import atomictest.eq
fun main() {
val humans1: List<Creature> =
group.filter { it is Human }
humans1.size eq 2
val humans2: List<Human> =
group.filterIsInstance<Human>()
humans2 eq humans1
}
filterIsInstance() 是产生与 filter() 相同结果的更可读的方式。然而,结果类型是不同的:虽然 filter() 返回 Creature 的列表(即使所有的结果元素都是 Human),但 filterIsInstance() 返回目标类型 Human 的列表。我们还消除了 FindType.kt 中出现的空值问题。
练习和解答可以在 www.AtomicKotlin.com 上找到。
密封类(Sealed Classes)
为了限制一个类层次结构,可以将超类声明为
sealed。
考虑使用不同交通工具的旅行者所进行的旅行:
// SealedClasses/UnSealed.kt
package withoutsealedclasses
import atomictest.eq
open class Transport
data class Train(
val line: String
): Transport()
data class Bus(
val number: String,
val capacity: Int
): Transport()
fun travel(transport: Transport) =
when (transport) {
is Train ->
"Train ${transport.line}"
is Bus ->
"Bus ${transport.number}: " +
"size ${transport.capacity}"
else -> "$transport is in limbo!"
}
fun main() {
listOf(Train("S1"), Bus("11", 90))
.map(::travel) eq
"[Train S1, Bus 11: size 90]"
}
Train 和 Bus 分别包含有关它们的 Transport 模式的不同细节。
travel() 函数包含一个 when 表达式,该表达式会发现 transport 参数的确切类型。Kotlin 需要默认的 else 分支,因为可能会存在 Transport 的其他子类。
travel() 显示了向下转型的固有问题所在。假设您继承了 Tram 作为 Transport 的新类型。如果这样做,travel() 仍然会编译和运行,没有任何提示您应该修改它来检测 Tram。如果您的代码中分散了许多向下转型的实例,那么这将成为维护的挑战。
我们可以通过使用 sealed 关键字来改善这种情况。在定义 Transport 时,将 open class 替换为 sealed class:
// SealedClasses/SealedClasses.kt
package sealedclasses
import atomictest.eq
sealed class Transport
data class Train(
val line: String
) : Transport()
data class Bus(
val number: String,
val capacity: Int
) : Transport()
fun travel(transport: Transport) =
when (transport) {
is Train ->
"Train ${transport.line}"
is Bus ->
"Bus ${transport.number}: " +
"size ${transport.capacity}"
}
fun main() {
listOf(Train("S1"), Bus("11", 90))
.map(::travel) eq
"[Train S1, Bus 11: size 90]"
}
sealed 类的所有直接子类必须位于与基类相同的文件中。
尽管 Kotlin 强制您在 when 表达式中详尽检查所有可能的类型,但 travel() 中的 when 现在不再需要 else 分支。由于 Transport 是 sealed,Kotlin 知道除了此文件中存在的那些类之外,没有其他 Transport 的子类。when 表达式现在是详尽无遗的,不需要 else 分支。
sealed 类层次结构可以发现在添加新的子类时的错误。当引入新的子类时,您必须更新使用现有层次结构的所有代码。在 UnSealed.kt 中的 travel() 函数将继续工作,因为 else 分支在未知类型的交通工具上产生 "$transport is in limbo!"。然而,这可能不是您想要的行为。
sealed 类揭示了在添加新的子类(如 Tram)时要修改的所有位置。在没有进行额外更改的情况下,SealedClasses.kt 中的 travel() 函数将无法编译,如果我们引入 Tram 类的话。sealed 关键字使忽视问题变得不可能,因为会得到编译错误。
sealed 关键字使向下转型变得更加容易,但您仍然应该对过多使用向下转型的设计保持怀疑。通常有一种更好和更清晰的方式使用多态来编写代码。
sealed vs. abstract
在这里,我们展示了 abstract 和 sealed 类允许相同类型的函数、属性和构造函数:
// SealedClasses/SealedVsAbstract.kt
package sealedclasses
abstract class Abstract(val av: String) {
open fun concreteFunction() {}
open val concreteProperty = ""
abstract fun abstractFunction(): String
abstract val abstractProperty: String
init {}
constructor(c: Char) : this(c.toString())
}
open class Concrete() : Abstract("") {
override fun concreteFunction() {}
override val concreteProperty = ""
override fun abstractFunction() = ""
override val abstractProperty = ""
}
sealed class Sealed(val av: String) {
open fun concreteFunction() {}
open val concreteProperty = ""
abstract fun abstractFunction(): String
abstract val abstractProperty: String
init {}
constructor(c: Char) : this(c.toString())
}
open class SealedSubclass() : Sealed("") {
override fun concreteFunction() {}
override val concreteProperty = ""
override fun abstractFunction() = ""
override val abstractProperty = ""
}
fun main() {
Concrete()
SealedSubclass()
}
sealed 类基本上是一个带有额外约束的 abstract 类,所有直接子类必须定义在相同的文件中。
sealed 类的间接子类可以在单独的文件中定义:
// SealedClasses/ThirdLevelSealed.kt
package sealedclasses
class ThirdLevel : SealedSubclass()
ThirdLevel 并未直接继承自 Sealed,因此无需将其放置在 SealedVsAbstract.kt 中。
尽管 sealed 接口似乎是一个有用的构造,但 Kotlin 并未提供它,因为无法阻止 Java 类实现相同的接口。
枚举子类
当一个类是 sealed 时,您可以轻松地迭代其子类:
// SealedClasses/SealedSubclasses.kt
package sealedclasses
import atom
ictest.eq
sealed class Top
class Middle1 : Top()
class Middle2 : Top()
open class Middle3 : Top()
class Bottom3 : Middle3()
fun main() {
Top::class.sealedSubclasses
.map { it.simpleName } eq
"[Middle1, Middle2, Middle3]"
}
创建一个类会生成一个 类对象。您可以访问该类对象的属性和成员函数来发现信息,并创建和操作该类的对象。::class 会产生一个类对象,因此 Top::class 会生成 Top 的类对象。
类对象的属性之一是 sealedSubclasses,它期望 Top 是一个 sealed 类(否则会产生一个空列表)。sealedSubclasses 会产生所有这些子类的类对象。请注意,结果中仅显示 Top 的直接子类。
类对象的 toString() 稍微冗长。通过使用 simpleName 属性,我们只生成类名本身。
sealedSubclasses 使用 反射,需要在类路径中添加依赖项 kotlin-reflection.jar。反射是一种动态发现和使用类的特征的方法。
当构建多态系统时,sealedSubclasses 可能是一个重要的工具。它可以确保新的类将自动包含在所有适当的操作中。然而,由于它在运行时发现子类,因此可能会对您的系统产生性能影响。如果您遇到速度问题,请确保使用分析器来发现 sealedSubclasses 是否可能是问题的原因(随着您学习使用分析器,您会发现性能问题通常并不在您猜测的地方)。
练习和解答可以在 www.AtomicKotlin.com 上找到。
类型检查
在 Kotlin 中,您可以根据对象的类型轻松进行操作。通常,这种活动属于多态的领域,因此类型检查可以启用有趣的设计选择。
传统上,类型检查用于特殊情况。例如,大多数昆虫都能飞行,但有少数几种不能飞行。在 basic() 中,我们使用类型检查来选择那些不能飞行的昆虫:
// TypeChecking/Insects.kt
package typechecking
import atomictest.eq
interface Insect {
fun walk() = "$name: walk"
fun fly() = "$name: fly"
}
class HouseFly : Insect
class Flea : Insect {
override fun fly() =
throw Exception("Flea cannot fly")
fun crawl() = "Flea: crawl"
}
fun Insect.basic() =
walk() + " " +
if (this is Flea)
crawl()
else
fly()
interface SwimmingInsect : Insect {
fun swim() = "$name: swim"
}
interface WaterWalker : Insect {
fun walkWater() =
"$name: walk on water"
}
class WaterBeetle : SwimmingInsect
class WaterStrider : WaterWalker
class WhirligigBeetle :
SwimmingInsect, WaterWalker
fun Insect.water() =
when(this) {
is SwimmingInsect -> swim()
is WaterWalker -> walkWater()
else -> "$name: drown"
}
fun main() {
val insects = listOf(
HouseFly(), Flea(), WaterStrider(),
WaterBeetle(), WhirligigBeetle()
)
insects.map { it.basic() } eq
"[HouseFly: walk HouseFly: fly, " +
"Flea: walk Flea: crawl, " +
"WaterStrider: walk WaterStrider: fly, " +
"WaterBeetle: walk WaterBeetle: fly, " +
"WhirligigBeetle: walk " +
"WhirligigBeetle: fly]"
insects.map { it.water() } eq
"[HouseFly: drown, Flea: drown, " +
"WaterStrider: walk on water, " +
"WaterBeetle: swim, " +
"WhirligigBeetle: swim]"
}
也有极少数的昆虫可以在水上行走或在水下游泳。同样,将这些特殊情况的行为放入基类以支持这一小部分类型是没有意义的。相反,Insect.water() 包含一个 when 表达式,该表达式会为特殊行为选择那些子类型,并假设其他一切都是标准行为。
选择一些孤立的类型进行特殊处理是类型检查的典型用例。请注意,向系统添加新类型不会影响现有代码(除非新类型也需要特殊处理)。
为了简化代码,name 会生成由问题下的 this 指向的对象类型:
// TypeChecking/AnyName.kt
package typechecking
val Any.name
get() = this::class.simpleName
name 接受一个 Any,并使用 ::class 获取关联的类引用,然后生成该类的 simpleName。
现在考虑一个“形状”示例的变体:
// TypeChecking/TypeCheck1.kt
package typechecking
import atomictest.eq
interface Shape {
fun draw(): String
}
class Circle : Shape {
override fun draw() = "Circle: Draw"
}
class Square : Shape {
override fun draw() = "Square: Draw"
fun rotate() = "Square: Rotate"
}
fun turn(s: Shape) = when(s) {
is Square -> s.rotate()
else -> ""
}
fun main() {
val shapes = listOf(Circle(), Square())
shapes.map { it.draw() } eq
"[Circle: Draw, Square: Draw]"
shapes.map { turn(it) } eq
"[, Square: Rotate]"
}
有几个原因可能导致您将 rotate() 添加到 Square 而不是 Shape:
Shape接口不在您的控制范围内,因此您无法修改它。- 旋转
Square看起来像是一个特殊情况,不应该为Shape接口增加负担或复杂性。 - 您只是试图通过添加
Square来快速解决问题,而不想费劲将rotate()放入Shape中,并在所有子类型中实现它。
当您必须通过添加更多类型来发展您的系统时,情况开始变得混乱:
// TypeChecking/TypeCheck2.kt
package typechecking
import atomictest.eq
class Triangle : Shape {
override fun draw() = "Triangle: Draw"
fun rotate() = "Triangle: Rotate"
}
fun turn2(s: Shape) = when(s) {
is Square -> s.rotate()
is Triangle -> s.rotate()
else -> ""
}
fun main() {
val shapes =
listOf(Circle(), Square(), Triangle())
shapes.map { it.draw() } eq
"[Circle: Draw, Square: Draw, " +
"Triangle: Draw]"
shapes.map { turn(it) } eq
"[, Square: Rotate, ]"
shapes.map { turn2(it) } eq
"[, Square: Rotate, Triangle: Rotate]"
}
shapes.map { it.draw() } 中的多态调用会适应新的 Triangle 类,而无需任何更改或错误。此外,Kotlin 不允许除非它实现了 draw(),否则就无法使用 Triangle。
原始的 turn() 在添加 Triangle 时不会出现问题,但它也不会产生我们想要的结果。为了生成所需的行为,turn() 必须变为 turn2()。
假设您的系统开始累积更多类似于 turn() 的函数。Shape 逻辑现在分散在所有这些函数中,而不是在 Shape 层次结构内部集中。如果您添加更多的 Shape 类型
,您必须搜索包含在 Shape 类型上切换的每个函数,并将其修改为包括新的情况。如果您错过了其中的任何函数,编译器将无法捕获到它。
turn() 和 turn2() 展示了通常被称为类型检查编码的内容,这意味着在您的系统中测试每种类型。 (如果您只寻找一种或几种特殊类型,通常不被认为是类型检查编码)。
在传统的面向对象语言中,类型检查编码通常被认为是一种反模式,因为它会引发一个或多个代码片段,这些代码片段必须在您添加或更改系统中的类型时保持警惕维护和更新。另一方面,多态将这些更改封装到您添加或修改的类型中,然后这些更改会透明地传播到您的系统中。
请注意,此问题仅在系统需要通过添加更多的 Shape 类型来发展时才会发生。如果这不是您的系统如何发展的方式,您就不会遇到这个问题。如果这是一个问题,通常不会突然发生,而会随着您的系统不断发展而变得越来越困难。
我们将看到 Kotlin 如何通过使用 sealed 类显著减轻了这个问题。这个解决方案并不完美,但类型检查成为了一个更合理的设计选择。
辅助函数中的类型检查
BeverageContainer 的本质是容纳和提供饮料。将回收视为辅助函数似乎是有道理的:
// TypeChecking/BeverageContainer.kt
package typechecking
import atomictest.eq
interface BeverageContainer {
fun open(): String
fun pour(): String
}
class Can : BeverageContainer {
override fun open() = "Pop Top"
override fun pour() = "Can: Pour"
}
open class Bottle : BeverageContainer {
override fun open() = "Remove Cap"
override fun pour() = "Bottle: Pour"
}
class GlassBottle : Bottle()
class PlasticBottle : Bottle()
fun BeverageContainer.recycle() =
when(this) {
is Can -> "Recycle Can"
is GlassBottle -> "Recycle Glass"
else -> "Landfill"
}
fun main() {
val refrigerator = listOf(
Can(), GlassBottle(), PlasticBottle()
)
refrigerator.map { it.open() } eq
"[Pop Top, Remove Cap, Remove Cap]"
refrigerator.map { it.recycle() } eq
"[Recycle Can, Recycle Glass, " +
"Landfill]"
}
通过将 recycle() 定义为辅助函数,它将不同的回收行为捕获在一个单独的位置,而不是通过将 recycle() 作为成员函数分布在 BeverageContainer 层次结构中。
使用 when 对类型进行操作是干净且直观的,但设计仍然存在问题。当您添加新类型时,recycle() 悄悄地使用 else 子句。由于这一点,对于类型检查函数(如 recycle()),可能会错过必要的更改。我们希望编译器在我们忘记了类型检查时告诉我们,就像当我们实现接口或继承抽象类时,它会告诉我们忘记了覆盖一个函数一样。
在这里,sealed 类提供了显着的改进。将 Shape 设置为 sealed 类意味着在 turn() 中的 when(去掉 else 后)要求检查每种类型。接口不能是 sealed,因此我们必须将 Shape 重写为类:
// TypeChecking/TypeCheck3.kt
package typechecking3
import atomictest.eq
import typechecking.name
sealed class Shape {
fun draw() = "$name: Draw"
}
class Circle : Shape()
class Square : Shape() {
fun rotate() = "Square: Rotate"
}
class Triangle : Shape() {
fun rotate() = "Triangle: Rotate"
}
fun turn(s: Shape) = when(s) {
is Circle -> ""
is Square -> s.rotate()
is Triangle -> s.rotate()
}
fun main() {
val shapes = listOf(Circle(), Square())
shapes.map { it.draw() } eq
"[Circle: Draw, Square: Draw]"
shapes.map { turn(it) } eq
"[, Square: Rotate]"
}
如果我们添加一个新的 Shape,编译器会告诉我们在 turn() 中添加一个新的类型检查路径。
但是,让我们看看当我们尝试将 sealed 应用于 BeverageContainer 问题时会发生什么。在此过程中,我们创建了额外的 Can 和 Bottle 子类型:
// TypeChecking/BeverageContainer2.kt
package typechecking2
import atomictest.eq
sealed class BeverageContainer {
abstract fun open(): String
abstract fun pour(): String
}
sealed class Can : BeverageContainer() {
override fun open() = "Pop Top"
override fun pour() = "Can: Pour"
}
class SteelCan : Can()
class AluminumCan : Can()
sealed class Bottle : BeverageContainer() {
override fun open() = "Remove Cap"
override fun pour() = "Bottle: Pour"
}
class GlassBottle : Bottle()
sealed class PlasticBottle : Bottle()
class PETBottle : PlasticBottle()
class HDPEBottle : PlasticBottle()
fun BeverageContainer.recycle() =
when(this) {
is Can -> "Recycle Can"
is Bottle -> "Recycle Bottle"
}
fun BeverageContainer.recycle2() =
when(this) {
is Can -> when(this) {
is SteelCan -> "Recycle Steel"
is AluminumCan -> "Recycle Aluminum"
}
is Bottle -> when(this) {
is GlassBottle -> "Recycle Glass"
is PlasticBottle -> when(this) {
is PETBottle -> "Recycle PET"
is HDPEBottle -> "Recycle HDPE"
}
}
}
fun main() {
val refrigerator = listOf(
SteelCan(), AluminumCan(),
GlassBottle(),
PETBottle(), HDPEBottle()
)
refrigerator.map { it.open() } eq
"[Pop Top, Pop Top, Remove Cap, " +
"Remove Cap, Remove Cap]"
refrigerator.map { it.recycle() } eq
"[Recycle Can, Recycle Can, " +
"Recycle Bottle, Recycle Bottle, " +
"Recycle Bottle]"
refrigerator.map { it.recycle2() } eq
"[Recycle Steel, Recycle Aluminum, " +
"Recycle Glass, " +
"Recycle PET, Recycle HDPE]"
}
请注意,中间类 Can 和 Bottle 也必须是 sealed 类,以使此方法起作用。
只要类是 BeverageContainer 的直接子类,编译器就会保证在 recycle() 中的 when 是全面的。但是,像 GlassBottle 和 AluminumCan 这样的子类并没有进行检查。为了解决这个问题,我们必须在 BeverageContainer2.kt 中的 recycle2() 中显式包含所见的嵌套 when 表达式,此时编译器确实需要进行全面的类型检查(尝试注释一个特定的 Can 或 Bottle 类型以验证此点)。
要创建一个健壮的类型检查解决方案,您必须严格在类层次结构的每个中间级别上使用 sealed,同时确保每个子类级别都有一个相应的嵌套 when。在这种情况下,如果您添加了 Can 或 Bottle 的新子类型,编译器将确保 recycle2() 检查每个子类型。
虽然不如多态那么干净,但这与先前的面向对象语言相比是一个重要的改进,允许您选择是编写多态成员函数还是辅助函数。请注意,只有在您有多个层次的继承时才会出现这个问题。
为了进行比较,让我们将 recycle() 带入 BeverageContainer 中,可以再次将其设置为 interface:
// TypeChecking/BeverageContainer3.kt
package typechecking3
import atomictest.eq
import typechecking.name
interface BeverageContainer {
fun open(): String
fun pour() = "$name: Pour"
fun recycle(): String
}
abstract class Can : BeverageContainer {
override fun open() = "Pop Top"
}
class SteelCan : Can() {
override fun recycle() = "Recycle Steel"
}
class AluminumCan : Can() {
override fun recycle() = "Recycle Aluminum"
}
abstract class Bottle : BeverageContainer {
override fun open() = "Remove Cap"
}
class GlassBottle : Bottle() {
override fun recycle() = "Recycle Glass"
}
abstract class PlasticBottle : Bottle()
class PETBottle : PlasticBottle() {
override fun recycle() = "Recycle PET"
}
class HDPEBottle : PlasticBottle() {
override fun recycle() = "Recycle HDPE"
}
fun main() {
val refrigerator = listOf(
SteelCan(), AluminumCan(),
GlassBottle(),
PETBottle(), HDPEBottle()
)
refrigerator.map { it.open() } eq
"[Pop Top, Pop Top, Remove Cap, " +
"Remove Cap, Remove Cap]"
refrigerator.map { it.recycle() } eq
"[Recycle Steel, Recycle Aluminum, " +
"Recycle Glass, " +
"Recycle PET, Recycle HDPE]"
}
通过将 Can 和 Bottle 设置为 abstract 类,我们强制其子类在相同的方式中重写 recycle(),就像编译器在 BeverageContainer2.kt 中强制每种类型在 recycle2() 中进行检查一样。
现在,recycle() 的行为分布在类之间,这可能是可以接受的设计决策。如果您决定回收行为经常更改,而且希望将其集中在一个地方,那么使用 BeverageContainer2.kt 中的辅助类型检查的 recycle2() 可能更适合您的需求,Kotlin 的特性使这成为了合理的选择。
练习和解决方案可以在 www.AtomicKotlin.com 上找到。
嵌套类
嵌套类可以在对象内创建更精细的结构。
嵌套类就是在外部类的命名空间内部定义的类。这意味着外部类“拥有”嵌套类。这个特性并不是必须的,但将类嵌套可以使您的代码更加清晰。在下面的示例中,Plane 嵌套在 Airport 内部:
// NestedClasses/Airport.kt
package nestedclasses
import atomictest.eq
import nestedclasses.Airport.Plane
class Airport(private val code: String) {
open class Plane {
// 可以访问 private 属性:
fun contact(airport: Airport) =
"Contacting ${airport.code}"
}
private class PrivatePlane : Plane()
fun privatePlane(): Plane = PrivatePlane()
}
fun main() {
val denver = Airport("DEN")
var plane = Plane() // [1]
plane.contact(denver) eq "Contacting DEN"
// 无法进行如下操作:
// val privatePlane = Airport.PrivatePlane()
val frankfurt = Airport("FRA")
plane = frankfurt.privatePlane()
// 无法进行如下操作:
// val p = plane as PrivatePlane // [2]
plane.contact(frankfurt) eq "Contacting FRA"
}
在 contact() 函数中,嵌套类 Plane 可以访问 airport 参数中的 private 属性 code,而普通的类则无法访问。除此之外,Plane 仅仅是位于 Airport 命名空间内部的一个普通类。
创建 Plane 对象并不需要 Airport 对象,但是如果您在 Airport 类体外部创建它,通常需要在 [1] 处限定构造函数调用。通过导入 nestedclasses.Airport.Plane,我们避免了这种限定。
嵌套类可以是 private 的,就像 PrivatePlane 一样。将它设置为 private 意味着 PrivatePlane 在 Airport 外部完全看不见,因此您不能在 Airport 外部调用 PrivatePlane 的构造函数。如果您在成员函数中定义并返回一个 PrivatePlane,如 privatePlane() 中所示,结果必须上转型为一个 public 类型(假设它扩展了一个 public 类型),并且不能将其下转型为 private 类型,就像 [2] 处所示。
这里还有一个嵌套的示例,Cleanable 是封闭类 House 和所有嵌套类的基类。clean() 遍历 parts 列表并为每个部分调用 clean(),从而产生一种递归:
// NestedClasses/NestedHouse.kt
package nestedclasses
import atomictest.*
abstract class Cleanable(val id: String) {
open val parts: List<Cleanable> = listOf()
fun clean(): String {
val text = "$id clean"
if (parts.isEmpty()) return text
return "${parts.joinToString(
" ", "(", ")",
transform = Cleanable::clean)} $text\n"
}
}
class House : Cleanable("House") {
override val parts = listOf(
Bedroom("Master Bedroom"),
Bedroom("Guest Bedroom")
)
class Bedroom(id: String) : Cleanable(id) {
override val parts =
listOf(Closet(), Bathroom())
class Closet : Cleanable("Closet") {
override val parts =
listOf(Shelf(), Shelf())
class Shelf : Cleanable("Shelf")
}
class Bathroom : Cleanable("Bathroom") {
override val parts =
listOf(Toilet(), Sink())
class Toilet : Cleanable("Toilet")
class Sink : Cleanable("Sink")
}
}
}
fun main() {
House().clean() eq """
(((Shelf clean Shelf clean) Closet clean
(Toilet clean Sink clean) Bathroom clean
) Master Bedroom clean
((Shelf clean Shelf clean) Closet clean
(Toilet clean Sink clean) Bathroom clean
) Guest Bedroom clean
) House clean
"""
}
注意多级嵌套的情况。例如,Bedroom 包含 Bathroom,而 Bathroom 包含 Toilet 和 Sink。
局部类
在函数内部定义的类称为局部类:
// NestedClasses/LocalClasses.kt
package nestedclasses
fun localClasses() {
open class Amphibian
class Frog : Amphibian()
val amphibian: Amphibian = Frog()
}
Amphibian 看起来更适合是一个接口而不是一个 open 类。但是,不允许使用局部接口。
局部的 open 类应该很少见;如果您需要这样一个类,那么您要创建的东西可能足够重要,以至于应该创建一个普通类。
Amphibian 和 Frog 在 localClasses() 外部是不可见的,所以您不能从函数中返回它们。要返回局部类的对象,您必须将其上转型为在函数外部定义的类或接口(假设它扩展了一个类或接口),并且不能在 main() 中将其下转型为 Frog,因为 Frog 不可用,所以 Kotlin 报告尝试使用 Frog 作为“未解析的引用”。
接口内部的类
类可以嵌套在接口内部:
// NestedClasses/WithinInterface.kt
package nestedclasses
import atomictest.eq
interface Item {
val type: Type
data class Type(val type: String)
}
class Bolt(type: String) : Item {
override val type = Item.Type(type)
}
fun main() {
val items = listOf(
Bolt("Slotted"), Bolt("Hex")
)
items.map(Item::type) eq
"[Type(type=Slotted), Type(type=Hex)]"
}
在 Bolt 类中,必须重写并使用限
定类名 Item.Type 来分配 val type。
嵌套枚举
枚举是类,因此它们可以嵌套在其他类内部:
// NestedClasses/Ticket.kt
package nestedclasses
import atomictest.eq
import nestedclasses.Ticket.Seat.*
class Ticket(
val name: String,
val seat: Seat = Coach
) {
enum class Seat {
Coach,
Premium,
Business,
First
}
fun upgrade(): Ticket {
val newSeat = values()[
(seat.ordinal + 1)
.coerceAtMost(First.ordinal)
]
return Ticket(name, newSeat)
}
fun meal() = when(seat) {
Coach -> "Bag Meal"
Premium -> "Bag Meal with Cookie"
Business -> "Hot Meal"
First -> "Private Chef"
}
override fun toString() = "$seat"
}
fun main() {
val tickets = listOf(
Ticket("Jerry"),
Ticket("Summer", Premium),
Ticket("Squanchy", Business),
Ticket("Beth", First)
)
tickets.map(Ticket::meal) eq
"[Bag Meal, Bag Meal with Cookie, " +
"Hot Meal, Private Chef]"
tickets.map(Ticket::upgrade) eq
"[Premium, Business, First, First]"
tickets eq
"[Coach, Premium, Business, First]"
tickets.map(Ticket::meal) eq
"[Bag Meal, Bag Meal with Cookie, " +
"Hot Meal, Private Chef]"
}
upgrade() 函数将 seat 的 ordinal 值加一,然后使用库函数 coerceAtMost() 来确保新值不会超过 First.ordinal,最后通过索引到 values() 来得到新的 Seat 类型。遵循函数式编程的原则,升级一个 Ticket 会产生一个新的 Ticket,而不是修改旧的 Ticket。
meal() 使用 when 测试每种 Seat 类型,这暗示我们可以使用多态来替代这种做法。
枚举不能嵌套在函数内部,并且不能继承其他类(包括其他枚举)。
接口可以包含嵌套枚举。FillIt 是一个类似游戏的模拟,它使用随机选择的 X 和 O 标记填充一个方形网格:
// NestedClasses/FillIt.kt
package nestedclasses
import nestedclasses.Game.State.*
import nestedclasses.Game.Mark.*
import kotlin.random.Random
import atomictest.*
interface Game {
enum class State { Playing, Finished }
enum class Mark { Blank, X ,O }
}
class FillIt(
val side: Int = 3, randomSeed: Int = 0
): Game {
val rand = Random(randomSeed)
private var state = Playing
private val grid =
MutableList(side * side) { Blank }
private var player = X
fun turn() {
val blanks = grid.withIndex()
.filter { it.value == Blank }
if(blanks.isEmpty()) {
state = Finished
} else {
grid[blanks.random(rand).index] = player
player = if (player == X) O else X
}
}
fun play() {
while(state != Finished)
turn()
}
override fun toString() =
grid.chunked(side).joinToString("\n")
}
fun main() {
val game = FillIt(8, 17)
game.play()
game eq """
[O, X, O, X, O, X, X, X]
[X, O, O, O, O, O, X, X]
[O, O, X, O, O, O, X, X]
[X, O, O, O, O, O, X, O]
[X, X, O, O, X, X, X, O]
[X, X, O, O, X, X, O, X]
[O, X, X, O, O, O, X, O]
[X, O, X, X, X, O, X, X]
"""
}
为了测试的目的,我们使用 randomSeed 来为 Random 对象设置种子,以便每次程序运行时产生相同的输出。grid 的每个元素都初始化为 Blank。在 turn() 函数中,首先找到所有包含 Blank 的单元格以及它们的索引。如果没有更多的 Blank 单元格,那么模拟就完成了。否则,我们使用带有种子生成器的 random() 来选择一个 Blank 单元格。由于我们之前使用了 withIndex(),我们必须选择 index 属性以获取要更改的单元格的位置。
为了以二维网格的形式显示 List,toString() 使用库函数 chunked() 将 List 分成长度为 side 的块,然后使用换行符将它们连接在一起。
尝试使用不同的 side 和 randomSeed 实验一下 FillIt。
练习和解决方案可以在 www.AtomicKotlin.com 上找到。
对象
object关键字定义了类似类的东西。然而,您不能创建object的实例,它只有一个实例。这有时被称为单例模式。
object 是将逻辑上属于一起的函数和属性组合在一起的一种方式,但此组合不需要多个实例,或者您想明确阻止多个实例。您永远不会创建 object 的实例,因为只有一个实例,并且在定义 object 后可以使用它:
// Objects/ObjectKeyword.kt
package objects
import atomictest.eq
object JustOne {
val n = 2
fun f() = n * 10
fun g() = this.n * 20 // [1]
}
fun main() {
// val x = JustOne() // Error
JustOne.n eq 2
JustOne.f() eq 20
JustOne.g() eq 40
}
在这里,您不能使用 JustOne() 来创建类 JustOne 的新实例。这是因为 object 关键字定义了结构并同时创建了对象。此外,它将元素放置在 object 的命名空间内。如果您只想让 object 在当前文件中可见,您可以将其设置为 private。
- [1] 关键字
this指的是单个对象实例。
您不能为 object 提供参数列表。
在使用 object 时,命名约定略有不同。通常情况下,当我们创建一个类的实例时,我们会将实例名称的第一个字母小写。然而,在创建 object 时,Kotlin 定义类并同时创建该类的单个实例。因此,我们将 object 的名称的第一个字母大写,因为它还表示一个类。
object 可以继承普通类或接口:
// Objects/ObjectInheritance.kt
package objects
import atomictest.eq
open class Paint(val color: String) {
open fun apply() = "Applying $color"
}
object Acrylic: Paint("Blue") {
override fun apply() =
"Acrylic, ${super.apply()}"
}
interface PaintPreparation {
fun prepare(): String
}
object Prepare: PaintPreparation {
override fun prepare() = "Scrape"
}
fun main() {
Prepare.prepare() eq "Scrape"
Paint("Green").apply() eq "Applying Green"
Acrylic.apply() eq "Acrylic, Applying Blue"
}
只有一个 object 实例,因此该实例在使用它的所有代码之间共享。这里是一个位于自己的 package 中的 object:
// Objects/GlobalSharing.kt
package objectsharing
object Shared {
var i: Int = 0
}
现在,我们可以在不同的包中使用 Shared:
// Objects/Share1.kt
package objectshare1
import objectsharing.Shared
fun f() {
Shared.i += 5
}
还可以在第三个包中使用:
// Objects/Share2.kt
package objectshare2
import objectsharing.Shared
import objectshare1.f
import atomictest.eq
fun g() {
Shared.i += 7
}
fun main() {
f()
g()
Shared.i eq 12
}
您可以从结果中看到 Shared 在所有包中都是相同的对象,这是因为 object 创建一个单一的实例。如果将 Shared 设置为 private,它在其他文件中将不可用。
object 不能放在函数内部,但它们可以嵌套在其他 object 或类内部(前提是这些类本身不是在其他类内部嵌套的):
// Objects/ObjectNesting.kt
package objects
import atomictest.eq
object Outer {
object Nested {
val a = "Outer.Nested.a"
}
}
class HasObject {
object Nested {
val a = "HasObject.Nested.a"
}
}
fun main() {
Outer.Nested.a eq "Outer.Nested.a"
HasObject.Nested.a eq "HasObject.Nested.a"
}
还有一种将 object 放在类内部的方法:companion object,您将在 伴生对象 部分中看到。
练习和解决方案可以在 www.AtomicKotlin.com 上找到。
内部类
内部类类似于嵌套类,但内部类的对象会保持对外部类的引用。
一个 inner 类具有与外部类的隐式链接。在下面的示例中,Hotel 类类似于 嵌套类 中的 Airport,但它使用了 inner 类。请注意,reception 是 Hotel 的一部分,但 callReception() 是嵌套类 Room 的成员函数,它在没有限定符的情况下访问 reception:
// InnerClasses/Hotel.kt
package innerclasses
import atomictest.eq
class Hotel(private val reception: String) {
open inner class Room(val id: Int = 0) {
// 从外部类中使用 'reception':
fun callReception() =
"Room $id Calling $reception"
}
private inner class Closet : Room()
fun closet(): Room = Closet()
}
fun main() {
val nycHotel = Hotel("311")
// 需要外部对象来
// 创建内部类的实例:
val room = nycHotel.Room(319)
room.callReception() eq
"Room 319 Calling 311"
val sfHotel = Hotel("0")
val closet = sfHotel.closet()
closet.callReception() eq "Room 0 Calling 0"
}
由于 Closet 继承了内部类 Room,Closet 也必须是一个 inner 类。嵌套类不能继承自 inner 类。
Closet 是 private 的,因此它只在 Hotel 的作用域内可见。
inner 对象会保持对其关联的外部对象的引用。因此,在创建 inner 对象时,必须先有外部对象。您不能在没有 Hotel 对象的情况下创建 Room 对象,就像您在 nycHotel.Room() 中看到的那样。
不允许使用 inner data 类。
限定的 this
类的一个好处是 this 引用。在访问属性或成员函数时,您无需显式地说“当前对象”。
对于简单的类,this 的含义是明显的,但对于 inner 类,this 可能指的是 inner 对象或外部对象。为了解决这个问题,Kotlin 提供了 限定的 this 语法:this 后跟 @ 和目标类的名称。
考虑三个级别的类:一个包含 inner 类 Seed 的外部类 Fruit,Seed 本身包含一个 inner 类 DNA:
// InnerClasses/QualifiedThis.kt
package innerclasses
import atomictest.eq
import typechecking.name
class Fruit { // 隐式标签 @Fruit
fun changeColor(color: String) =
"Fruit $color"
fun absorbWater(amount: Int) {}
inner class Seed { // 隐式标签 @Seed
fun changeColor(color: String) =
"Seed $color"
fun germinate() {}
fun whichThis() {
// 默认为当前类:
this.name eq "Seed"
// 为了明确,可以多余地
// 限定默认的 this:
this@Seed.name eq "Seed"
// 必须明确访问 Fruit:
this@Fruit.name eq "Fruit"
// 无法访问进一步内部的类:
// this@DNA.name
}
inner class DNA { // 隐式标签 @DNA
fun changeColor(color: String) {
// changeColor(color) // 递归
this@Seed.changeColor(color)
this@Fruit.changeColor(color)
}
fun plant() {
// 调用外部类的函数
// 不需要限定:
germinate()
absorbWater(10)
}
// 扩展函数:
fun Int.grow() { // 隐式标签 @grow
// 默认为 Int.grow() 的接收者:
this.name eq "Int"
// 多余的限定:
this@grow.name eq "Int"
// 仍然可以访问所有内容:
this@DNA.name eq "DNA"
this@Seed.name eq "Seed"
this@Fruit.name eq "Fruit"
}
// 外部类的扩展函数:
fun Seed.plant() {}
fun Fruit.plant() {}
fun whichThis() {
// 默认为当前类:
this.name eq "DNA"
// 多余的限定:
this@DNA.name eq "DNA"
// 其他必须是明确的:
this@Seed.name eq "Seed"
this@Fruit.name eq "Fruit"
}
}
}
}
// 扩展函数:
fun Fruit.grow(amount: Int) {
absorbWater(amount)
// 调用 Fruit 的版本 changeColor():
changeColor("Red") eq "Fruit Red"
}
// 内部类的扩展函数:
fun Fruit.Seed.grow(n: Int) {
germinate()
// 调用 Seed 的版本 changeColor():
changeColor("Green") eq "Seed Green"
}
// 内部类的扩展函数:
fun Fruit.Seed.DNA.grow(n: Int) = n.grow()
fun main() {
val fruit = Fruit()
fruit.grow(4)
val seed = fruit.Seed()
seed.grow(9)
seed.whichThis()
val dna = seed.DNA()
dna.plant()
dna.grow(5)
dna.whichThis()
dna.changeColor("Purple")
}
Fruit、Seed 和 DNA 都有名为 changeColor() 的函数,但这不是继承关系。由于它们具有相同的名称和签名,唯一区分它们的方法是使用限定的 this,就像在 DNA 的 changeColor() 中所看到的那样。在 plant() 中,可以在没有名称冲突的情况下无需限定就可以调用两个外部类
中的函数。
尽管它是一个扩展函数,grow() 仍然可以访问外部类中的所有对象。grow() 可以在任何地方调用 Fruit.Seed.DNA 隐式接收者可用的地方,例如在 DNA 的扩展函数内部。
内部类继承
内部类可以从不同的外部类中继承另一个内部类。在这里,BigEgg 中的 Yolk 是从 Egg 中的 Yolk 派生而来的:
// InnerClasses/InnerClassInheritance.kt
package innerclasses
import atomictest.*
open class Egg {
private var yolk = Yolk()
open inner class Yolk {
init { trace("Egg.Yolk()") }
open fun f() { trace("Egg.Yolk.f()") }
}
init { trace("New Egg()") }
fun insertYolk(y: Yolk) { yolk = y }
fun g() { yolk.f() }
}
class BigEgg : Egg() {
inner class Yolk : Egg.Yolk() {
init { trace("BigEgg.Yolk()") }
override fun f() {
trace("BigEgg.Yolk.f()")
}
}
init { insertYolk(Yolk()) }
}
fun main() {
BigEgg().g()
trace eq """
Egg.Yolk()
New Egg()
Egg.Yolk()
BigEgg.Yolk()
BigEgg.Yolk.f()
"""
}
BigEgg.Yolk 明确地将 Egg.Yolk 作为其基类,并覆盖了它的 f() 成员函数。函数 insertYolk() 允许 BigEgg 将其自己的 Yolk 对象向上转型为 Egg 中的 yolk 引用,因此当 g() 调用 yolk.f() 时,使用的是被覆盖的 f() 版本。第二次调用 Egg.Yolk() 是 BigEgg.Yolk 构造函数的基类构造函数调用。您可以看到在调用 g() 时使用了被覆盖的 f() 版本。
作为对象构造的回顾,请研究 trace 输出,直到它变得有意义。
本地和匿名内部类
在成员函数内部定义的类称为本地内部类。这些也可以使用对象表达式匿名创建,或者使用 SAM 转换。在所有情况下,不使用 inner 关键字,但是它被暗示:
// InnerClasses/LocalInnerClasses.kt
package innerclasses
import atomictest.eq
fun interface Pet {
fun speak(): String
}
object CreatePet {
fun home() = " 家!"
fun dog(): Pet {
val say = "汪汪"
// 本地内部类:
class Dog : Pet {
override fun speak() = say + home()
}
return Dog()
}
fun cat(): Pet {
val emit = "喵喵"
// 匿名内部类:
return object: Pet {
override fun speak() = emit + home()
}
}
fun hamster(): Pet {
val squeak = "吱吱"
// SAM 转换:
return Pet { squeak + home() }
}
}
fun main() {
CreatePet.dog().speak() eq "汪汪 家!"
CreatePet.cat().speak() eq "喵喵 家!"
CreatePet.hamster().speak() eq "吱吱 家!"
}
本地内部类可以访问函数中的其他元素以及外部类对象中的元素,因此在 speak() 中可以使用 say、emit、squeak 和 home()。
您可以通过使用对象表达式来识别匿名内部类,就像在 cat() 中所见。它返回一个从 Pet 继承的类的 object,该类覆盖了 speak()。匿名内部类更小、更直接,不会创建只在一个地方使用的命名类。更紧凑的是 SAM 转换,就像在 hamster() 中看到的那样。
由于内部类保持对外部类对象的引用,因此本地内部类可以访问封闭类的所有成员:
// InnerClasses/CounterFactory.kt
package innerclasses
import atomictest.*
fun interface Counter {
fun next(): Int
}
object CounterFactory {
private var count = 0
fun new(name: String): Counter {
// 本地内部类:
class Local : Counter {
init { trace("Local()") }
override fun next(): Int {
// 访问本地标识符:
trace("$name $count")
return count++
}
}
return Local()
}
fun new2(name: String): Counter {
// 匿名内部类的实例:
return object: Counter {
init { trace("Counter()") }
override fun next(): Int {
trace("$name $count")
return count++
}
}
}
fun new3(name: String): Counter {
trace("Counter()")
return Counter { // SAM 转换
trace("$name $count")
count++
}
}
}
fun main() {
fun test(counter: Counter) {
(0..3).forEach { counter.next() }
}
test(CounterFactory.new("Local"))
test(CounterFactory.new2("Anon"))
test(CounterFactory.new3("SAM"))
trace eq """
Local() Local 0 Local 1 Local 2 Local 3
Counter() Anon 4 Anon 5 Anon 6 Anon 7
Counter() SAM 8 SAM 9 SAM 10 SAM 11
"""
}
Counter 跟踪一个 count 并返回下一个 Int 值。new()、new2() 和 new3() 分别创建 Counter 接口的不同实现。new() 返回一个具有命名内部类的实
例,new2() 返回一个匿名内部类的实例,而 new3() 使用 SAM 转换 创建一个匿名对象。所有生成的 Counter 对象都隐含地访问外部对象的元素,因此它们是内部类而不仅仅是嵌套类。从输出中可以看出,count 在所有 Counter 对象之间共享。
对于 init 子句,SAM 转换有限制,例如,它不支持 init 子句。
- -
在 Kotlin 中,文件可以包含多个顶层类和函数。因此,很少需要本地类,因此如果确实需要本地类,它们应该是基本且直观的。例如,可以创建一个简单的 data 类,该类仅在函数内部使用。如果本地类变得复杂,那么您可能应该将其从函数中分离出来,使其成为常规类。
练习和解答可在 www.AtomicKotlin.com 找到。
伴生对象
成员函数作用于特定的类实例。有些函数不涉及“关于”一个对象的操作,因此它们不需要与该对象绑定。
在 companion object 内部定义的函数和字段与该类有关。常规类元素可以访问伴生对象的元素,但伴生对象的元素不能访问常规类的元素。
正如您在对象中看到的那样,可以在类内部定义一个常规的 object,但这不会在 object 和类之间提供关联。特别是,在引用其成员时,您必须显式地为嵌套的 object 命名。如果在类内部定义一个伴生对象,它的元素将透明地对该类可用:
// CompanionObjects/CompanionObject.kt
package companionobjects
import atomictest.eq
class WithCompanion {
companion object {
val i = 3
fun f() = i * 3
}
fun g() = i + f()
}
fun WithCompanion.Companion.h() = f() * i
fun main() {
val wc = WithCompanion()
wc.g() eq 12
WithCompanion.i eq 3
WithCompanion.f() eq 9
WithCompanion.h() eq 27
}
在类外部,您可以使用类名访问伴生对象的成员,就像 WithCompanion.i 和 WithCompanion.f() 中所示。类的其他成员可以在不限定的情况下访问伴生对象的元素,就像 g() 的定义中所示。
h() 是伴生对象的扩展函数。
如果一个函数不需要访问私有类成员,您可以选择将其定义在文件范围内,而不是将其放在伴生对象中。
每个类只允许有一个伴生对象。为了清晰起见,您可以给伴生对象起一个名字:
// CompanionObjects/NamingCompanionObjects.kt
package companionobjects
import atomictest.eq
class WithNamed {
companion object Named {
fun s() = "from Named"
}
}
class WithDefault {
companion object {
fun s() = "from Default"
}
}
fun main() {
WithNamed.s() eq "from Named"
WithNamed.Named.s() eq "from Named"
WithDefault.s() eq "from Default"
// 默认名称是 "Companion":
WithDefault.Companion.s() eq "from Default"
}
即使在给伴生对象起了名字,您仍然可以在不使用该名称的情况下访问其元素。如果不给伴生对象起名称,Kotlin 将为其分配名称 Companion。
如果在伴生对象中创建属性,它将产生一个单一的存储空间,用于该字段,并与关联类的所有实例共享:
// CompanionObjects/ObjectProperty.kt
package companionobjects
import atomictest.eq
class WithObjectProperty {
companion object {
private var n: Int = 0 // 只有一个
}
fun increment() = ++n
}
fun main() {
val a = WithObjectProperty()
val b = WithObjectProperty()
a.increment() eq 1
b.increment() eq 2
a.increment() eq 3
}
main() 中的测试显示,n 只有一个存储空间,不管创建了多少个 WithObjectProperty 实例。a 和 b 都访问相同的内存空间来存储 n。
increment() 显示可以从其封闭类中访问伴生对象的 private 成员。
当一个函数仅访问伴生对象中的属性时,将该函数移到伴生对象中是有意义的:
// CompanionObjects/ObjectFunctions.kt
package companionobjects
import atomictest.eq
class CompanionObjectFunction {
companion object {
private var n: Int = 0
fun increment() = ++n
}
}
fun main() {
CompanionObjectFunction.increment() eq 1
CompanionObjectFunction.increment() eq 2
}
您不再需要一个 CompanionObjectFunction 实例来调用 increment()。
假设您想要保持创建的每个对象的计数,以给每个对象赋予唯一的可读标识符:
// CompanionObjects/ObjectCounter.kt
package companionobjects
import atomictest.eq
class Counted {
companion object {
private var count = 0
}
private val id = count++
override fun toString() = "#$id"
}
fun main() {
List(4) { Counted() } eq "[#0, #1, #2, #3]"
}
伴生对象可以是在其他地方定义的类的实例:
// CompanionObjects/CompanionInstance.kt
package companionobjects
import atomictest.*
interface ZI {
fun f(): String
fun g(): String
}
open class ZIOpen : ZI {
override fun f() = "ZIOpen.f()"
override fun g() = "ZIOpen.g()"
}
class ZICompanion {
companion object: ZIOpen()
fun u() = trace("${f()} ${g()}")
}
class ZICompanionInheritance {
companion object: ZIOpen() {
override fun g() =
"ZICompanionInheritance.g()"
fun h() = "ZICompanionInheritance.h()"
}
fun u() = trace("${f()} ${g()} ${h()}")
}
class ZIClass {
companion object: ZI {
override fun f() = "ZIClass.f()"
override fun g() = "ZIClass.g()"
}
fun u() = trace("${f()} ${g()}")
}
fun main() {
ZIClass.f()
ZIClass.g()
ZIClass().u()
ZICompanion.f()
ZICompanion.g()
ZICompanion().u()
ZICompanionInheritance.f()
ZICompanionInheritance.g()
ZICompanionInheritance().u()
trace eq """
ZIClass.f() ZIClass.g()
ZIOpen.f() ZIOpen.g()
ZIOpen.f()
ZICompanionInheritance.g()
ZICompanionInheritance.h()
"""
}
ZICompanion 使用一个 ZIOpen 对象作为其伴生对象,而 ZICompanionInheritance 在重写和扩展 ZIOpen 的同时创建了一个 ZIOpen 对象。ZIClass 显示了您可以在创建伴生对象的同时实现接口。
如果您想要用作伴生对象的类不是 open,则不能像上面那样直接使用它。然而,如果该类实现了一个接口,您仍然可以通过类委托使用它:
// CompanionObjects/CompanionDelegation.kt
package companionobjects
import atomictest.*
class ZIClosed : ZI {
override fun f() = "ZIClosed.f()"
override fun g() = "ZIClosed.g()"
}
class ZIDelegation {
companion object: ZI by ZIClosed()
fun u() = trace("${f()} ${g()}")
}
class ZIDelegationInheritance {
companion object: ZI by ZIClosed() {
override fun g() =
"ZIDelegationInheritance.g()"
fun h() =
"ZIDelegationInheritance.h()"
}
fun u() = trace("${f()} ${g()} ${h()}")
}
fun main() {
ZIDelegation.f()
ZIDelegation.g()
ZIDelegation().u()
ZIDelegationInheritance.f()
ZIDelegationInheritance.g()
ZIDelegationInheritance().u()
trace eq """
ZIClosed.f() ZIClosed.g()
ZIClosed.f()
ZIDelegationInheritance.g()
ZIDelegationInheritance.h()
"""
}
ZIDelegationInheritance 显示了,您可以采用非 open 类 ZIClosed,将其委托,然后重写和扩展该委托。委托将接口的方法转发给提供实现的实例。即使该实例的类是 final,我们仍然可以对委托接收者进行重写并添加方法。
下面是一个小谜题:
// CompanionObjects/DelegateAndExtend.kt
package companionobjects
import atomictest.eq
interface Extended: ZI {
fun u(): String
}
class Extend : ZI by Companion, Extended {
companion object: ZI {
override fun f() = "Extend.f()"
override fun g() = "Extend.g()"
}
override fun u() = "${f()} ${g()}"
}
private fun test(e: Extended): String {
e.f()
e.g()
return e.u()
}
fun main() {
test(Extend()) eq "Extend.f() Extend.g()"
}
在 Extend 中,ZI 接口是使用它自己的 companion object 来实现的,该对象的默认名称是 Companion。但我们还要实现 Extended 接口,该接口是 ZI 接口加上一个额外的函数 u()。Extended 的 ZI 部分已经通过 Companion 实现,因此我们只需要 override 附加函数 u() 来完成 Extend。现在,Extend 对象可以向上转型为 Extended,作为 test() 的参数。
伴生对象的一个常见用法是控制对象的创建——这就是工厂方法模式。假设您只想允许创建 Numbered2 对象的列表,而不允许单独创建 Numbered2 对象:
// CompanionObjects/CompanionFactory.kt
package companionobjects
import atomictest.eq
class Numbered2
private constructor(private val id: Int) {
override fun toString(): String = "#$id"
companion object Factory {
fun create(size: Int) =
List(size) { Numbered2(it) }
}
}
fun main() {
Numbered2.create(0) eq "[]"
Numbered2.create(5) eq
"[#0, #1, #2, #3, #4]"
}
Numbered2 构造函数是 private 的。这意味着只有一种方式可以创建实例——通过 create() 工厂函数。工厂函数有时可以解决常规构造函数无法解决的问题。
伴生对象中的构造函数在程序中首次实例化封闭类时初始化:
// CompanionObjects/Initialization.kt
package companionobjects
import atomictest.*
class CompanionInit {
companion object {
init {
trace("Companion Constructor")
}
}
}
fun main() {
trace("Before")
CompanionInit()
trace("After 1")
CompanionInit()
trace("After 2")
CompanionInit()
trace("After 3")
trace eq """
Before
Companion Constructor
After 1
After 2
After 3
"""
}
从输出可以看出,在首次创建 CompanionInit() 对象时,伴生对象仅被构造一次。
Exercises and solutions can be found at www.AtomicKotlin.com.
第六部分:预防失败
“如果调试是消除软件缺陷的过程,那么编程必然是引入这些缺陷的过程。” — Edsger Dijkstra
异常处理
失败总是有可能的。
Kotlin在分析您的程序时会发现基本错误。在编译时无法检测到的错误必须在运行时处理。在异常一章中,您已经学习了如何抛出异常。在这篇文章中,我们将学习如何捕获异常。
从历史上看,失败常常是灾难性的。例如,在C语言中编写的程序会突然停止工作,丢失数据,并有可能导致操作系统崩溃。
改进的错误处理是增加代码可靠性的强大方式。在创建可重用的程序组件时,错误处理尤其重要。要创建一个健壮的系统,每个组件都必须是健壮的。通过一致的错误处理,组件可以可靠地将问题传达给客户端代码。
现代应用程序通常使用并发,而并发程序必须能够处理非关键异常。例如,服务器应该在会话被异常终止时进行恢复。
异常将三个活动混为一谈:
- 错误报告
- 恢复
- 资源清理
让我们来考虑每个活动。
报告
标准库中的异常通常足够。要进行更具体的异常处理,您可以从Exception或其子类型继承新的异常类型:
// ExceptionHandling/DefiningExceptions.kt
package exceptionhandling
import atomictest.*
class Exception1(
val value: Int
): Exception("错误的值: $value")
open class Exception2(
description: String
): Exception(description)
class Exception3(
description: String
): Exception2(description)
fun main() {
capture {
throw Exception1(13)
} eq "Exception1: 错误的值: 13"
capture {
throw Exception3("错误")
} eq "Exception3: 错误"
}
如main()中所示,throw表达式需要一个Throwable子类型的实例。要定义新的异常类型,继承Exception(它继承自Throwable)。Exception1和Exception2都继承自Exception,而Exception3继承自Exception2。
恢复
异常处理的目标是恢复。这意味着您要修复问题,将程序恢复到稳定状态,并继续执行。恢复通常包括记录有关错误的信息。
很多情况下,恢复是不可能的。异常可能代表无法恢复的程序故障,无论是编码错误还是环境中无法控制的问题。
当抛出异常时,异常处理机制会寻找一个适当的位置继续执行。异常会向外移动到更高的级别,从抛出异常的function1(),到调用function1()的function2(),再到调用function2()的function3(),以此类推,直到达到main()。匹配的处理程序会捕获异常。这将停止搜索并运行该处理程序。如果程序从未找到匹配的处理程序,将会终止并生成一个控制台堆栈跟踪。
// ExceptionHandling/Stacktrace.kt
package stacktrace
import exceptionhandling.Exception1
fun function1(): Int =
throw Exception1(-52)
fun function2() = function1()
fun function3() = function2()
fun main() {
// function3()
}
取消注释对function3()的调用会产生以下堆栈跟踪:
Exception in thread "main" exceptionhandling.Exception1: 错误的值: -\
52
at stacktrace.StacktraceKt.function1(Stacktrace.kt:6)
at stacktrace.StacktraceKt.function2(Stacktrace.kt:8)
at stacktrace.StacktraceKt.function3(Stacktrace.kt:10)
at stacktrace.StacktraceKt.main(Stacktrace.kt:13)
at stacktrace.StacktraceKt.main(Stacktrace.kt)
function1()、function2()或function3()中的任何一个都可以catch异常并处理它,阻止异常终止程序。
异常处理程序是以catch关键字开头,后面跟着一个参数列表,其中包含您正在处理的异常。然后是一个实现恢复的代码块。
在下面的示例中,函数toss()为参数1-3产生不同的异常,否则返回“OK”。test()包含了throws()函数的完整一组处理程序:
// ExceptionHandling/Handlers.kt
package exceptionhandling
import atomictest.eq
fun toss(which: Int) = when (which) {
1 -> throw Exception1(1)
2 -> throw Exception2("异常2")
3 -> throw Exception3("异常3")
else -> "OK"
}
fun test(which: Int): Any? =
try {
toss(which)
} catch (e: Exception1) {
e.value
} catch (e: Exception3) {
e.message
} catch (e: Exception2) {
e.message
}
fun main() {
test(0) eq "OK"
test(1) eq 1
test(2) eq "异常2"
test(3) eq "异常3"
}
当调用toss()时,您必须catch所有相关的toss()异常,以便非相关的异常“冒泡”并在其他地方被捕获。
test()中的整个try-catch是单个表达式:它返回try主体的最后一个表达式或与异常匹配的catch子句的最后一个表达式。如果没有catch处理异常,该异常会向上传递给堆栈。如果未捕获,它会生成一个堆栈跟踪。
因为Exception3扩展自Exception2,所
以如果Exception2的catch出现在处理程序的顺序中位于Exception3的catch之前,则会将Exception3处理为Exception2:
// ExceptionHandling/Hierarchy.kt
package exceptionhandling
import atomictest.eq
fun testCatchOrder(which: Int) =
try {
toss(which)
} catch (e: Exception2) { // [1]
"处理 Exception2 得到 ${e.message}"
} catch (e: Exception3) { // [2]
"处理 Exception3 得到 ${e.message}"
}
fun main() {
testCatchOrder(2) eq
"处理 Exception2 得到 异常2"
testCatchOrder(3) eq
"处理 Exception2 得到 异常3"
}
catch子句的顺序意味着Exception3会被行 [1] 捕获,尽管在行 [2] 中具有更具体的异常处理程序。
异常子类型
在testCode()中,不正确的code参数会抛出一个IllegalArgumentException:
// ExceptionHandling/LibraryException.kt
package exceptionhandling
import atomictest.*
fun testCode(code: Int) {
if (code <= 1000) {
throw IllegalArgumentException(
"'code' 必须大于 1000: $code")
}
}
fun main() {
try {
// A1在16进制表示法中是161:
testCode("A1".toInt(16))
} catch (e: IllegalArgumentException) {
e.message eq "'code' 必须大于 1000: 161"
}
try {
testCode("0".toInt(1))
} catch (e: IllegalArgumentException) {
e.message eq "radix 1 不在有效范围 2..36 内"
}
}
IllegalArgumentException在testCode()和库函数toInt(radix)中都会被抛出。这导致了在main()中的有些令人困惑的错误消息。问题在于我们正在使用相同的异常来表示两个不同的问题。我们通过为我们的错误引入一个名为IncorrectInputException的新异常类型来解决这个问题:
// ExceptionHandling/NewException.kt
package exceptionhandling
import atomictest.eq
class IncorrectInputException(
message: String
): Exception(message)
fun checkCode(code: Int) {
if (code <= 1000) {
throw IncorrectInputException(
"代码必须大于 1000: $code")
}
}
fun main() {
try {
checkCode("A1".toInt(16))
} catch (e: IncorrectInputException) {
e.message eq "代码必须大于 1000: 161"
} catch (e: IllegalArgumentException) {
"产生错误" eq "如果执行到这里"
}
try {
checkCode("1".toInt(1))
} catch (e: IncorrectInputException) {
"产生错误" eq "如果执行到这里"
} catch (e: IllegalArgumentException) {
e.message eq "radix 1 不在有效范围 2..36 内"
}
}
现在,每个问题都有自己的处理程序。
不要创建过多的异常类型。作为一个经验法则,使用不同的异常类型来区分不同的处理方案,使用不同的构造函数参数为特定的处理方案提供详细信息。
资源清理
当失败不可避免时,自动资源清理有助于使程序的其他部分继续安全运行。
finally关键字确保在异常处理期间进行资源清理。无论您是否正常离开try块,finally子句始终都会运行,不管是正常还是异常情况:
// ExceptionHandling/TryFinally.kt
package exceptionhandling
import atomictest.*
fun checkValue(value: Int) {
try {
trace(value)
if (value <= 0)
throw IllegalArgumentException(
"值必须为正数: $value")
} finally {
trace("在 finally 子句中,用于 $value")
}
}
fun main() {
listOf(10, -10).forEach {
try {
checkValue(it)
} catch (e: IllegalArgumentException) {
trace("在 main() 的 catch 子句中")
trace(e.message)
}
}
trace eq """
10
在 finally 子句中,用于 10
-10
在 finally 子句中,用于 -10
在 main() 的 catch 子句中
值必须为正数: -10
"""
}
finally甚至可以与中间的catch子句一起使用。例如,假设在使用完开关后必须将其关闭:
// ExceptionHandling/GuaranteedCleanup.kt
package exceptionhandling
import atomictest.eq
data class Switch(
var on: Boolean = false,
var result: String = "OK"
)
fun testFinally(i: Int): Switch {
val sw = Switch()
try {
sw.on = true
when (i) {
0 -> throw IllegalStateException()
1 -> return sw // [1]
}
} catch (e: IllegalStateException) {
sw.result = "exception"
} finally {
sw.on = false
}
return sw
}
fun main() {
testFinally(0) eq
"Switch(on=false, result=exception)"
testFinally(1) eq
"Switch(on=false, result=OK)" // [2]
testFinally(2) eq
"Switch(on=false, result=OK)"
}
即使在try块中使用return([1]),finally子句仍然会运行([2])。无论testFinally()是正常完成还是异常完成,finally子句始终会执行。
AtomicTest中的异常处理
本书使用AtomicTest的capture()来确保预期的异常被抛出。capture()接受一个函数参数,并返回一个包含异常类和错误消息的CapturedException对象:
// ExceptionHandling/CaptureImplementation.kt
package exceptionhandling
import atomictest.CapturedException
fun capture(f:
() -> Unit): CapturedException =
try { // [1]
f()
CapturedException(null,
"<Error>: 预期异常") // [2]
} catch (e: Throwable) { // [3]
CapturedException(e::class, // [4]
if (e.message != null) ": ${e.message}"
else "")
}
fun main() {
capture {
throw Exception("!!!")
} eq "Exception: !!!" // [5]
capture {
1
} eq "<Error>: 预期异常"
}
capture()在try块内部调用其函数参数f([1]),通过捕获Throwable([3])处理所有可能的异常。如果没有抛出异常,CapturedException消息表示预期异常([2])。如果捕获了异常,返回的CapturedException将包含异常类和消息([4])。CapturedException可以使用eq与String进行比较([5])。
通常情况下,您不会捕获Throwable,而是会处理每个特定的异常类型。
指南
考虑到恢复最初是意图,异常处理恢复实际上是非常罕见的。Kotlin中异常的主要目的是发现程序错误,而不是恢复。因此,在普通的Kotlin代码中捕获异常是一种“代码异味”。
以下是在Kotlin中使用异常编程的准则:
-
逻辑错误:这些是您的代码中的错误。要么根本不捕获它们(并生成堆栈跟踪),要么在应用程序的顶层捕获它们并报告错误,可能会重新启动受影响的操作。
-
数据错误:这些是来自错误数据的错误,程序员无法控制。应用程序必须以某种方式处理该问题,而不会将其归咎于程序逻辑。例如,我们在本文中使用了
String.toInt(),它会为不合适的String抛出异常。它还具有伴生函数String.toIntOrNull(),在失败时返回null,因此您可以在表达式中使用它,例如val n = string.toIntOrNull() ?: default。Kotlin库的设计围绕着通过返回null来处理坏结果,而不是抛出异常。通常预计会偶尔失败的操作通常会有一个“OrNull”版本,您可以在其中使用异常版本。 -
检查指令:这些检查逻辑错误。当它们发现错误时,它们会抛出异常,但它们看起来像函数调用,因此您不需要在代码中明确抛出异常。
-
输入/输出错误:这些是无法控制且不能忽略的外部条件。然而,使用“OrNull”方法会迅速混淆代码的可读性。更重要的是,您通常可以从I/O错误中恢复,通常是通过重试操作。因此,Kotlin中的I/O操作会抛出异常,因此您的应用程序中会有处理这些异常并尝试从中恢复的代码。
练习和解决方案可在www.AtomicKotlin.com找到。
核对指令
**核对指令(Check Instructions)**用于确保满足约束条件。它们通常用于验证函数参数和结果。
核对指令通过表达非明显的要求来发现编程错误。它们还可以为以后阅读代码的读者提供文档。通常在函数的开头,用于确保参数合法性,以及在函数的末尾,用于检查函数的计算结果。
核对指令通常在失败时抛出异常。通常情况下,您可以使用核对指令代替显式地抛出异常。核对指令更容易编写和思考,并产生更易理解的代码。尽可能使用它们来测试和阐明您的程序。
require()
**设计契约(Design By Contract)**中的*前置条件(preconditions)*保证了初始化约束。Kotlin中的require()通常用于验证函数参数,因此通常出现在函数体的开头。这些测试不能在编译时检查。前置条件相对容易包含在代码中,但有时可以转换为单元测试。
考虑一个表示儒略历月份的数值字段。您知道该值必须始终在1..12的范围内。前置条件在值超出该范围时报告错误:
// CheckInstructions/JulianMonth.kt
package checkinstructions
import atomictest.*
data class Month(val monthNumber: Int) {
init {
require(monthNumber in 1..12) {
"Month out of range: $monthNumber"
}
}
}
fun main() {
Month(1) eq "Month(monthNumber=1)"
capture { Month(13) } eq
"IllegalArgumentException: " +
"Month out of range: 13"
}
我们在构造函数内执行require()。如果其条件不满足,require()会抛出IllegalArgumentException。您总是可以使用require()来代替抛出IllegalArgumentException。
require()的第二个参数是一个生成String的lambda表达式。如果String需要构造,那么除非require()失败,否则不会发生该开销。
在Summary 2中,Quadratic.kt的参数不当时,它会抛出IllegalArgumentException。我们可以使用require()简化代码:
// CheckInstructions/QuadraticRequire.kt
package checkinstructions
import kotlin.math.sqrt
import atomictest.*
class Roots(
val root1: Double,
val root2: Double
)
fun quadraticZeroes(
a: Double,
b: Double,
c: Double
): Roots {
require(a != 0.0) { "a is zero" }
val underRadical = b * b - 4 * a * c
require(underRadical >= 0) {
"Negative underRadical: $underRadical"
}
val squareRoot = sqrt(underRadical)
val root1 = (-b - squareRoot) / 2 * a
val root2 = (-b + squareRoot) / 2 * a
return Roots(root1, root2)
}
fun main() {
capture {
quadraticZeroes(0.0, 4.0, 5.0)
} eq "IllegalArgumentException: " +
"a is zero"
capture {
quadraticZeroes(3.0, 4.0, 5.0)
} eq "IllegalArgumentException: " +
"Negative underRadical: -44.0"
val roots = quadraticZeroes(3.0, 8.0, 5.0)
roots.root1 eq -15.0
roots.root2 eq -9.0
}
这段代码比原始的Quadratic.kt代码要更清晰和简洁。
以下DataFile类允许我们在IDE通过AtomicKotlin课程运行示例,或在独立的书籍构建中运行时,使用文件。所有的DataFile对象都将文件存储在targetDir子目录中:
// CheckInstructions/DataFile.kt
package checkinstructions
import atomictest.eq
import java.io.File
import java.nio.file.Paths
val targetDir = File("DataFiles")
class DataFile(val fileName: String) :
File(targetDir, fileName) {
init {
if (!targetDir.exists())
targetDir.mkdir()
}
fun erase() { if (exists()) delete() }
fun reset(): File {
erase()
createNewFile()
return this
}
}
fun main() {
DataFile("Test.txt").reset() eq
Paths.get("DataFiles", "Test.txt")
.toString()
}
DataFile可以操作底层的操作系统文件,以便读写该文件。DataFile的基类是java.io.File,它是Java库中最古老的类之一;它出现在语言的第一个版本中,当时他们认为使用相同的类(File)来表示文件和目录是个很好的主意。尽管File古老,但Kotlin可以轻松地继承它。
在构造过程中,如果targetDir不存在,则创建它。erase()函数删除文件,而reset()函数会删除文件并创建一个新的空文件。
Java标准库的Paths类只包含一个重载的get()函数。我们想要的get()版本接受任意数量的String,并构建一个Path对象,表示与操作系统无关的目录路径。
打开文件通常有许多前置条件,通常涉及文件路径、命名和内容。考虑一个函数,该函数打开并读取以“file_”开头的文件名的文件。使用require(),我们验证文件名是否正确,并且文件存在且不为空:
// CheckInstructions/GetTrace.kt
package checkinstructions
import atomictest.*
fun getTrace(fileName: String): List<String> {
require(fileName.startsWith("file_")) {
"$fileName must start with 'file_'"
}
val file = DataFile(fileName)
require(file.exists()) {
"$fileName
doesn't exist"
}
val lines = file.readLines()
require(lines.isNotEmpty()) {
"$fileName is empty"
}
return lines
}
fun main() {
DataFile("file_empty.txt").writeText("")
DataFile("file_wubba.txt").writeText(
"wubba lubba dub dub")
capture {
getTrace("wrong_name.txt")
} eq "IllegalArgumentException: " +
"wrong_name.txt must start with 'file_'"
capture {
getTrace("file_nonexistent.txt")
} eq "IllegalArgumentException: " +
"file_nonexistent.txt doesn't exist"
capture {
getTrace("file_empty.txt")
} eq "IllegalArgumentException: " +
"file_empty.txt is empty"
getTrace("file_wubba.txt") eq
"[wubba lubba dub dub]"
}
我们一直使用的是两个参数版本的require(),但也有一个只有一个参数的版本,它会生成一个默认消息:
// CheckInstructions/SingleArgRequire.kt
package checkinstructions
import atomictest.*
fun singleArgRequire(arg: Int): Int {
require(arg > 5)
return arg
}
fun main() {
capture {
singleArgRequire(5)
} eq "IllegalArgumentException: " +
"Failed requirement."
singleArgRequire(6) eq 6
}
失败消息没有两个参数版本那么明确,但在某些情况下足够使用。
requireNotNull()
requireNotNull()测试其第一个参数,并在该参数不为null时返回该参数。否则,它会抛出IllegalArgumentException。
在成功时,requireNotNull()的参数会自动智能转换为非空类型。因此,您通常不需要requireNotNull()的返回值:
// CheckInstructions/RequireNotNull.kt
package checkinstructions
import atomictest.*
fun notNull(n: Int?): Int {
requireNotNull(n) { // [1]
"notNull() argument cannot be null"
}
return n * 9 // [2]
}
fun main() {
val n: Int? = null
capture {
notNull(n)
} eq "IllegalArgumentException: " +
"notNull() argument cannot be null"
capture {
requireNotNull(n) // [3]
} eq "IllegalArgumentException: " +
"Required value was null."
notNull(11) eq 99
}
- [2] 注意,由于调用了
requireNotNull(),n不再需要空检查,因为它变成了非空类型。
与require()一样,有一个两个参数的版本,可以自己构造消息([1]),还有一个带有默认消息的单参数版本([3])。由于requireNotNull()测试的是特定问题(是否为null),因此单参数版本比在require()中更有用。
check()
设计契约的*后置条件(postcondition)*测试函数的结果。对于长而复杂的函数,后置条件对于验证结果的可靠性非常重要。每当您可以描述函数结果的约束时,最好将其表达为后置条件。
check()与require()完全相同,不同之处在于它会抛出IllegalStateException,而不是IllegalArgumentException。通常它在函数的末尾使用,以验证结果(或函数对象中的字段)是否有效,即事物是否变得不好。
假设一个复杂的函数写入一个文件,您不确定所有执行路径是否会创建该文件。在函数的末尾添加一个后置条件有助于确保正确性:
// CheckInstructions/Postconditions.kt
package checkinstructions
import atomictest.*
val resultFile = DataFile("Results.txt")
fun createResultFile(create: Boolean) {
if (create)
resultFile.writeText("Results\n# ok")
// ... other execution paths
check(resultFile.exists()) {
"${resultFile.name} doesn't exist!"
}
}
fun main() {
resultFile.erase()
capture {
createResultFile(false)
} eq "IllegalStateException: " +
"Results.txt doesn't exist!"
createResultFile(true)
}
假设您的前置条件确保了有效的参数,后置条件失败几乎总是表示编程错误。出于这个原因,您可能会更少地看到后置条件,因为一旦程序员确信代码是正确的,后置条件就可以被注释掉或删除,如果它影响性能的话。当然,最好保留这些测试,以便立即检测到由未来的代码更改引起的问题。一种做法是将后置条件移到单元测试中。
assert()
为了避免对check()语句进行注释和取消注释,assert()允许您启用和禁用assert()检查。
assert()来自Java。默认情况下,断言是禁用的,只有在您使用命令行标志明确启用它们时才会启用。在Kotlin中,该标志是-ea。
我们建议始终使用require()和check(),它们在没有特殊配置的情况下始终可用。
练习和解决方案可以在www.AtomicKotlin.com找到。
Nothing 类型
Nothing返回类型表示一个永远不返回的函数
通常这是一个总是抛出异常的函数。
下面是一个产生无限循环(避免使用这种情况)的函数,因为它永远不会返回,其返回类型是 Nothing:
// NothingType/InfiniteLoop.kt
package nothingtype
fun infinite(): Nothing {
while (true) {}
}
Nothing 是一个内置的 Kotlin 类型,没有实例。
一个实际的例子是内置的 TODO(),它的返回类型是 Nothing,并抛出 NotImplementedError:
// NothingType/Todo.kt
package nothingtype
import atomictest.*
fun later(s: String): String = TODO("later()")
fun later2(s: String): Int = TODO()
fun main() {
capture {
later("Hello")
} eq "NotImplementedError: " +
"An operation is not implemented: later()"
capture {
later2("Hello!")
} eq "NotImplementedError: " +
"An operation is not implemented."
}
虽然 later() 和 later2() 的返回类型都不是 Nothing,但是 TODO() 返回的是 Nothing。Nothing 与任何类型都兼容。
later() 和 later2() 可以成功编译。如果调用任何一个,异常会提醒您编写实现。TODO() 是一个有用的工具,用于在填充细节之前“勾勒”代码框架,以验证所有内容是否相互契合。
在下面的代码中,fail() 总是抛出 Exception,因此它的返回类型是 Nothing。请注意,调用 fail() 比显式抛出异常更易读和紧凑:
// NothingType/Fail.kt
package nothingtype
import atomictest.*
fun fail(i: Int): Nothing =
throw Exception("fail($i)")
fun main() {
capture {
fail(1)
} eq "Exception: fail(1)"
capture {
fail(2)
} eq "Exception: fail(2)"
}
fail() 允许您轻松更改错误处理策略。例如,您可以更改异常类型或在抛出异常之前记录附加消息。
如果参数不是 String,则下面的代码会抛出 BadData 异常:
// NothingType/CheckObject.kt
package nothingtype
import atomictest.*
class BadData(m: String) : Exception(m)
fun checkObject(obj: Any?): String =
if (obj is String)
obj
else
throw BadData("Needs String, got $obj")
fun test(checkObj: (obj: Any?) -> String) {
checkObj("abc") eq "abc"
capture {
checkObj(null)
} eq "BadData: Needs String, got null"
capture {
checkObj(123)
} eq "BadData: Needs String, got 123"
}
fun main() {
test(::checkObject)
}
checkObject() 的返回类型是 if 表达式的返回类型。Kotlin 将 throw 视为类型 Nothing,而 Nothing 可以分配给任何类型。在 checkObject() 中,String 优先于 Nothing,因此 if 表达式的类型是 String。
我们可以使用安全转换和 Elvis 运算符重写 checkObject()。checkObject2() 会将 obj 转换为 String,如果可以转换,否则会抛出异常:
// NothingType/CheckObject2.kt
package nothingtype
fun failWithBadData(obj: Any?): Nothing =
throw BadData("Needs String, got $obj")
fun checkObject2(obj: Any?): String =
(obj as? String) ?: failWithBadData(obj)
fun main() {
test(::checkObject2)
}
当给出一个没有附加类型信息的纯粹的 null 时,编译器会推断出一个可空的 Nothing:
// NothingType/ListOfNothing.kt
import atomictest.eq
fun main() {
val none: Nothing? = null
var nullableString: String? = null // [1]
nullableString = "abc"
nullableString = none // [2]
nullableString eq null
val nullableInt: Int? = none // [3]
nullableInt eq null
val listNone: List<Nothing?> = listOf(null)
val ints: List<Int?> = listOf(null) // [4]
ints eq listNone
}
您可以将 null 和 none 都分配给可空类型的 var 或 val,例如 nullableString 或 nullableInt。这是允许的,因为 null 和 none 的类型都是 Nothing?(可空的 Nothing)。就像 Nothing 类型的表达式(例如 fail())可以被解释为“任何类型”一样,Nothing? 类型的表达式,例如 null,可以被解释为“任何可空类型”。在 [1]、[2] 和 [3] 中显示了不同可空类型的分配。
listNone 初始化为只包含 null 值的 List。编译器将其推断为 List<Nothing?>。因此,当您使用只包含 null 的值初始化 List 时,必须显式指定您要存储在 List 中的元素类型([4])。
Exercises and solutions can be found at www.AtomicKotlin.com.
资源清理
使用
try-finally块进行资源清理是繁琐且容易出错的。Kotlin 的库函数可以为您管理清理。
就像您在 异常处理 中学到的一样,finally 子句会在 try 块退出时无论如何清理资源。但是如果在关闭资源时可能发生异常怎么办?你最终会在 finally 子句内部添加另一个 try 块。而且,如果在 try 内部抛出一个异常,并在关闭资源时抛出另一个异常,后者不应该遮盖前者。确保适当的清理变得非常混乱。
为了减少这种复杂性,Kotlin 的 use() 保证关闭资源的适当清理,使您不必编写手动的清理代码。
use() 可以与实现了 Java 的 AutoCloseable 接口的任何对象一起使用。它执行块内的代码,然后在对象上调用 close(),无论您如何退出块,无论是正常退出(包括通过 return),还是通过异常退出。
use() 会重新抛出所有的异常,因此您仍然必须处理这些异常。
与 use() 一起使用的预定义类在 Java 的 AutoCloseable 文档中可以找到。例如,要从 File 中读取行,我们可以将 use() 应用于 BufferedReader。Check Instructions(se06-ch02.md)中的 DataFile 继承了 java.io.File:
// ResourceCleanup/AutoCloseable.kt
import atomictest.eq
import checkinstructions.DataFile
fun main() {
DataFile("Results.txt")
.bufferedReader()
.use { it.readLines().first() } eq
"Results"
}
useLines() 打开一个 File 对象,提取所有的行,并将这些行传递给目标函数(通常是一个 lambda):
// ResourceCleanup/UseLines.kt
import atomictest.eq
import checkinstructions.DataFile
fun main() {
DataFile("Results.txt").useLines {
it.filter { "#" in it }.first() // [1]
} eq "# ok"
DataFile("Results.txt").useLines { lines ->
lines.filter { line -> // [2]
"#" in line
}.first()
} eq "# ok"
}
- [1] 左侧的
it是文件中所有行的集合,而右侧的it是每一行。为了减少混淆,避免编写同时出现两个不同的it的代码。 - [2] 使用命名参数可以避免
it过多引起混淆。
所有操作都在 useLines() lambda 内部完成;在 lambda 之外,文件内容不可用,除非您显式返回它们。当关闭文件时,useLines() 会返回 lambda 的结果。
forEachLine() 使得可以轻松地对文件中的每一行应用一个操作:
// ResourceCleanup/ForEachLine.kt
import checkinstructions.DataFile
import atomictest.*
fun main() {
DataFile("Results.txt").forEachLine {
if (it.startsWith("#"))
trace("$it")
}
trace eq "# ok"
}
forEachLine() 中的 lambda 返回 Unit,这意味着您对行所做的任何操作必须通过副作用实现。在函数式编程中,我们更喜欢返回结果而不是副作用,因此 useLines() 比 forEachLine() 更符合函数式编程的方式。但是,forEachLine() 对于简单的实用程序来说是一种快速的解决方案。
您可以通过实现 AutoCloseable 接口来创建自己的类,以便与 use() 一起使用,该接口仅包含 close() 函数:
// ResourceCleanup/Usable.kt
package resourcecleanup
import atomictest.*
class Usable() : AutoCloseable {
fun func() = trace("func()")
override fun close() = trace("close()")
}
fun main() {
Usable().use { it.func() }
trace eq "func() close()"
}
use() 确保资源在创建资源的位置进行清理,而不是在您完成资源时强制您编写清理代码。
Exercises and solutions can be found at www.AtomicKotlin.com.
日志记录
日志记录 捕获正在运行的程序的信息。
例如,一个安装程序可能会记录:
- 安装过程中采取的步骤。
- 用于文件存储的目录。
- 程序的启动值。
一个 Web 服务器可能会记录每个请求的来源地址和状态。
在调试过程中,日志记录也非常有用。如果没有日志记录,您可能会使用 println() 语句来解析程序的行为。这在没有调试器(比如内置在 IntelliJ IDEA 中的调试器)的情况下可能很有帮助。然而,一旦您确定程序正常工作,您可能会将 println() 语句移除。稍后,如果遇到更多的错误,您可能会再次添加它们。相比之下,日志记录可以在需要时动态启用,否则可以关闭。
对于一些错误,您只能报告问题。某些类型的错误程序可以从中恢复(如 异常处理 中所示),可以记录有关这些错误的详细信息以供后续分析。例如,在 Web 应用程序中,如果出现问题,您不会终止程序。日志记录会捕获这些事件,为程序员和管理员提供一种发现问题的方法。与此同时,应用程序会继续运行。
我们使用一款专为 Kotlin 设计的开源日志记录库称为 Kotlin-logging,它具有 Kotlin 的感觉和简单性。请注意,还有其他可供选择的日志记录库。
您必须在使用日志记录之前创建一个日志记录器。您几乎总是希望在文件范围内创建它,以便在该文件中的所有组件中都可用:
// Logging/BasicLogging.kt
package logging
import mu.KLogging
private val log = KLogging().logger
fun main() {
val msg = "Hello, Kotlin Logging!"
log.trace(msg)
log.debug(msg)
log.info(msg)
log.warn(msg)
log.error(msg)
}
main() 显示了不同的 日志级别:trace()、debug() 和 info() 捕获行为信息,而 warn() 和 error() 表示问题。
启动配置确定实际上报告的日志级别。这可以在执行过程中进行修改。长时间运行的应用程序的操作者可以在不重新启动程序的情况下更改日志级别(通常是不可接受的)。
日志记录库有着相当奇怪的历史。人们不满意 Java 分发的原始日志记录库,因此他们创建了其他库。为了统一日志记录,设计人员开始开发共同的日志记录接口。鉴于组织可能已经投资于现有的日志记录库,这些接口被创建为多个不同日志记录库的 外观。后来,其他程序员创建了(可能是改进的)覆盖 这些 外观的外观。使用日志记录系统通常意味着选择一个外观,然后选择一个或多个基础实现。
Kotlin-logging 库是 Simple Logging Facade for Java (SLF4J) 的外观,SLF4J 是多个日志框架的抽象。您可以选择满足您需求的框架,尽管更有可能是公司的运营团队会做出这个决策,因为他们通常管理日志记录并分析生成的日志文件。
对于这个示例,我们使用 slf4j-simple 作为我们的实现。这是 SLF4J 的一部分,因此我们不需要安装或配置额外的库,有些库有让人讨厌的设置复杂性。slf4j-simple 将其输出发送到控制台错误流。当您运行程序时,您会看到:
[main] INFO mu.KLogging - Hello, Kotlin Logging!
[main] WARN mu.KLogging - Hello, Kotlin Logging!
[main] ERROR mu.KLogging - Hello, Kotlin Logging!
trace() 和 debug() 不产生输出,因为默认配置不报告这些级别。要获取不同的报告级别,请更改日志记录配置。日志记录配置因您使用的日志记录库而异,因此我们不在这里讨论它。
将日志记录到文件的实现通常通过在文件变得太大时自动丢弃最旧部分来管理这些日志文件。还有其他用于读取和分析日志文件的工具。日志记录的实践可能需要相当深入的研究。
对于基本问题,安装、配置和使用日志记录系统的工作可能会诱使您回到 println() 语句。幸运的是,有更简单的策略。
一个快速而肮脏的方法是定义一个全局函数。在您不需要它时,这很容易禁用:
// Logging/SimpleLoggingStrategy.kt
package logging
import checkinstructions.DataFile
val logFile = // 重置以确保文件为空:
DataFile("simpleLogFile.txt").reset()
fun debug(msg: String) =
System.err.println("Debug: $msg")
// 要禁用:
// fun debug(msg: String) = Unit
fun trace(msg: String) =
logFile.appendText("Trace: $msg\n")
fun main() {
debug("Simple Logging Strategy")
trace("Line 1")
trace("Line 2")
println(logFile.readText())
}
/* 输出结果:
Debug: Simple Logging Strategy
Trace: Line 1
Trace: Line 2
*/
debug() 将其输出发送到控制台错误流。trace() 将其输出发送到日志文件。
您还可以创建自己的简单日志类:
// Logging/AtomicLog.kt
package atomiclog
import checkinstructions.DataFile
class Logger(fileName: String) {
val logFile = DataFile(fileName).reset()
private fun log(type: String, msg: String) =
logFile.appendText("$type: $msg\n")
fun trace(msg: String) = log("Trace", msg)
fun debug(msg: String) = log("Debug", msg)
fun info(msg: String) = log("Info", msg)
fun warn(msg: String) = log("Warn", msg)
fun error(msg: String) = log("Error", msg)
// 用于基本测试:
fun report(msg: String) {
trace(msg)
debug(msg)
info(msg)
warn(msg)
error(msg)
}
}
您可以添加对其他功能的支持,比如日志级别和时间戳。
使用这个库很简单:
// Logging/UseAtomicLog.kt
package useatomiclog
import atomiclog.Logger
import atomictest.eq
private val logger = Logger("AtomicLog.txt")
fun main() {
logger.report("Hello, Atomic Log!")
logger.logFile.readText() eq """
Trace: Hello, Atomic Log!
Debug: Hello, Atomic Log!
Info: Hello, Atomic Log!
Warn: Hello, Atomic Log!
Error: Hello, Atomic Log!
"""
}
创建另一个日志记录库可能并不是一个好的时间利用方式。
- -
日志记录并不像调用库函数那么简单 - 它有一个显著的运行时组件。通常情况下,日志记录通常包括在可交付的产品中,运维人员必须能够打开和关闭日志记录,动态地调整日志记录级别,并控制日志文件。对于长时间运行的程序(例如服务器),最后一个问题特别重要,因为它包括了防止日志文件填满的策略。
Exercises and solutions can be found at www.AtomicKotlin.com.
单元测试
单元测试是为函数的每个方面创建正确性测试的实践。单元测试可以快速地揭示出错误的代码,加快开发速度。
关于测试的内容远远超出了这本书的范围,所以本文只是一个基本的介绍。
"单元" 在 "单元测试" 中描述了一个小的代码片段,通常是一个函数,它被单独且独立地测试。这不应与不相关的 Kotlin Unit 类型混淆。
单元测试通常由程序员编写,并在每次构建项目时运行。由于单元测试运行频率非常高,因此它们必须运行得很快。
在阅读本书时,您已经了解了单元测试,通过我们用来验证书中代码的 AtomicTest 库。AtomicTest 使用简洁的 eq 函数来完成单元测试中最常见的模式:将预期结果与生成的结果进行比较。
在众多的单元测试框架中,JUnit 是 Java 中最流行的。还有专门为 Kotlin 创建的框架。Kotlin 标准库中包含了 kotlin.test,它提供了不同测试库的外观。这样,您不会受限于使用特定的库。kotlin.test 还包含了基本断言函数的封装。
要使用 kotlin.test,您必须修改项目的 build.gradle 文件的 dependencies 部分,包括:
testImplementation "org.jetbrains.kotlin:kotlin-test-common"
在单元测试中,程序员调用各种断言函数,以验证待测试函数的预期行为。断言函数包括 assertEquals(),它将实际值与预期值进行比较,以及 assertTrue(),它测试其第一个参数,一个布尔表达式。在此示例中,单元测试是以单词 test 开头的函数:
// UnitTesting/NoFramework.kt
package unittesting
import kotlin.test.assertEquals
import kotlin.test.assertTrue
import atomictest.*
fun fortyTwo() = 42
fun testFortyTwo(n: Int = 42) {
assertEquals(
expected = n,
actual = fortyTwo(),
message = "Incorrect,")
}
fun allGood(b: Boolean = true) = b
fun testAllGood(b: Boolean = true) {
assertTrue(allGood(b), "Not good")
}
fun main() {
testFortyTwo()
testAllGood()
capture {
testFortyTwo(43)
} contains
listOf("expected:", "<43>",
"but was", "<42>")
capture {
testAllGood(false)
} contains listOf("Error", "Not good")
}
在 main() 中,您可以看到一个失败的断言函数会产生一个 AssertionError - 这意味着单元测试失败,将问题通知给程序员。
kotlin.test 包含一系列名称以 assert 开头的函数:
assertEquals(),assertNotEquals()assertTrue(),assertFalse()assertNull(),assertNotNull()assertFails(),assertFailsWith()
类似的函数通常包含在每个单元测试框架中,但名称和参数顺序可能不同。例如,在 assertEquals() 中的 message 参数可能在第一个或最后一个。此外,很容易混淆 expected 和 actual - 使用命名参数可以避免这个问题。
kotlin.test 中的 expect() 函数运行一个代码块,并将该结果与预期值进行比较:
fun <T> expect(
expected: T,
message: String?,
block: () -> T
) {
assertEquals(expected, block(), message)
}
这里将 testFortyTwo() 重写为使用 expect():
// UnitTesting/UsingExpect.kt
package unittesting
import atomictest.*
import kotlin.test.*
fun testFortyTwo2(n: Int = 42) {
expect(n, "Incorrect,") { fortyTwo() }
}
fun main() {
testFortyTwo2()
capture {
testFortyTwo2(43)
} contains
listOf("expected:",
"<43> but was:", "<42>")
assertFails { testFortyTwo2(43) }
capture {
assertFails { testFortyTwo2() }
} contains
listOf("Expected an exception",
"to be thrown",
"but was completed successfully.")
assertFailsWith<AssertionError> {
testFortyTwo2(43)
}
capture {
assertFailsWith<AssertionError> {
testFortyTwo2()
}
} contains
listOf("Expected an exception",
"to be thrown",
"but was completed successfully.")
}
为了添加对边界情况的测试,是很重要的。如果一个函数在某些条件下产生错误,那么这应该通过单元测试进行验证(就像 AtomicTest 的 capture() 那样)。assertFails() 和 assertFailsWith() 确保异常被抛出。assertFailsWith() 还会检查异常的类型。
测试框架
一个典型的测试框架包含一系列断言函数和运行测试并显示结果的机制。大多数测试运行器会用绿色表示成功,用红色表示失败。
本文将 JUnit5 作为 kotlin.test 的底层库
。要将其包含在项目中,您的 build.gradle 的 dependencies 部分应如下所示:
testImplementation "org.jetbrains.kotlin:kotlin-test"
testImplementation "org.jetbrains.kotlin:kotlin-test-junit"
testImplementation "org.jetbrains.kotlin:kotlin-test-junit5"
testImplementation "org.junit.jupiter:junit-jupiter:$junit_version"
如果您使用不同的库,您可以在该框架的说明中找到设置详细信息。
kotlin.test 提供了最常用函数的外观。断言委托给底层测试框架中的适当函数。例如,在 org.junit.jupiter.api.Assertions 类中,assertEquals() 调用了 Assertions.assertEquals()。
Kotlin 支持用于定义和表达式的 注解。注解是 @ 后跟注解名称的符号,表示对注解元素的特殊处理。@Test 注解将普通函数转换为测试函数。我们可以使用 @Test 注解来测试 fortyTwo() 和 allGood():
// Tests/unittesting/SampleTest.kt
package unittesting
import kotlin.test.*
class SampleTest {
@Test
fun testFortyTwo() {
expect(42, "Incorrect,") { fortyTwo() }
}
@Test
fun testAllGood() {
assertTrue(allGood(), "Not good")
}
}
kotlin.test 使用 typealias 来创建 @Test 注解的外观:
typealias Test = org.junit.jupiter.api.Test
这告诉编译器将 @org.junit.jupiter.api.Test 注解替换为 @Test。
一个测试类通常包含多个单元测试。理想情况下,每个单元测试只验证一个行为。当引入新功能时,每个单元测试不仅会添加新的测试来检查其正确性,还会运行所有现有的测试,以确保之前的功能仍然有效。在引入新变更时,您会感到更加安全,系统也更加可预测和稳定。
在修复新错误的过程中,您会为此和类似情况创建额外的单元测试,以便将来不会犯同样的错误。
如果您使用连续集成(CI)服务器,例如 Teamcity,所有可用的测试都会自动运行,并且如果出现问题,您会收到通知。
考虑一个具有多个属性的类:
// UnitTesting/Learner.kt
package unittesting
enum class Language {
Kotlin, Java, Go, Python, Rust, Scala
}
data class Learner(
val id: Int,
val name: String,
val surname: String,
val language: Language
)
通常,在测试中添加用于制造测试数据的实用函数是有帮助的,尤其是当您在测试期间必须使用相同默认值创建多个对象时。在这里,makeLearner() 创建具有默认值的对象:
// Tests/unittesting/LearnerTest.kt
package unittesting
import unittesting.Language.*
import kotlin.test.*
fun makeLearner(
id: Int,
language: Language = Kotlin, // [1]
name: String = "Test Name $id",
surname: String = "Test Surname $id"
) = Learner(id, name, surname, language)
class LearnerTest {
@Test
fun `single Learner`() {
val learner = makeLearner(10, Java)
assertEquals("Test Name 10", learner.name)
}
@Test
fun `multiple Learners`() {
val learners = (1..9).map(::makeLearner)
assertTrue(
learners.all { it.language == Kotlin })
}
}
在 Learner 中添加默认参数,仅用于测试,会引入不必要的复杂性和潜在的混淆。在生成测试实例时,使用 makeLearner() 更简单、更干净,消除了冗余代码。
makeLearner() 参数的顺序简化了其使用。在这种情况下,我们预计更经常为 lang 指定一个非默认值,而不是更改 name 和 surname 的默认测试值,因此 lang 参数是第二个参数([1])。
模拟和集成测试
依赖于其他组件的系统会使得创建隔离测试变得复杂。程序员通常会使用一种称为 模拟 的实践,而不是引入对真实组件的依赖。
在测试期间,模拟将真实实体替换为虚假实体。通常会对数据库进行模拟,以保持存储数据的完整性。模拟可以实现与真实组件相同的接口,也可以使用模拟库(如 MockK)来创建。
在测试时,重要的是独立地测试不同的功能片段 - 这就是单元测试所做的。同时,还需要确保系统的不同部分在与其他部分组合时能够正常工作 - 这就是 集成测试 所做的。单元测试是“内向”测试,而集成测试是“外向”测试。
在 IntelliJ IDEA 中进行测试
IntelliJ IDEA 和 Android Studio 支持创建和运行单元测试。
要创建测试,请右键单击(Mac 上为控制键点击)您想要测试的类或函数,并从弹出菜单中选择 "Generate..."。从 "Generate" 菜单中选择 "Test..."。第二种方法是打开 “意图操作” 列表,然后选择 “创建测试”。
将 "Testing library" 设置为 JUnit5。如果出现 "在模块中未找到 JUnit5 库" 的消息,请单击消息旁边的 "修复" 按钮。"Destination package"
应为 unittesting。结果将放在另一个目录中(始终将测试代码与主要代码分开)。Gradle 的默认设置是 src/test/kotlin 文件夹,但您可以选择其他目标。
选中您想要测试的函数旁边的复选框。您可以自动从源代码导航到相应的测试类,反之亦然;有关详细信息,请参阅文档。
生成测试框架代码后,您可以修改它以适应您的需求。在本文的示例和练习中,将:
import org.junit.Test
import org.junit.Assert.*
替换为:
import kotlin.test.*
在 IntelliJ IDEA 中运行测试时,您可能会收到类似于 "未接收到测试事件" 的错误消息。这是因为 IDEA 的默认配置假定您是在外部运行测试,使用 Gradle。要修复这个问题,使您可以在 IDEA 内运行测试,请从文件菜单开始:
File | Settings | Build, Execution, Deployment | Build Tools | Gradle
在该页面上,您将看到一个下拉列表,标题为 "Run tests using:",默认设置为 "Gradle (Default)"。将其更改为 "IntelliJ IDEA",您的测试将正确运行。
练习和解答可以在 www.AtomicKotlin.com 找到。
第七部分:强大的工具
“任何傻瓜都可以编写计算机能理解的代码。优秀的程序员编写能让人类理解的代码。” — Martin Fowler
扩展 Lambda
扩展 Lambda 类似于扩展函数。它定义了一个 lambda,而不是一个函数。
在这里,va 和 vb 产生相同的结果:
// ExtensionLambdas/Vanbo.kt
package extensionlambdas
import atomictest.eq
val va: (String, Int) -> String = { str, n ->
str.repeat(n) + str.repeat(n)
}
val vb: String.(Int) -> String = {
this.repeat(it) + repeat(it)
}
fun main() {
va("Vanbo", 2) eq "VanboVanboVanboVanbo"
"Vanbo".vb(2) eq "VanboVanboVanboVanbo"
vb("Vanbo", 2) eq "VanboVanboVanboVanbo"
// "Vanbo".va(2) // 不能编译通过
}
va 是一个普通的 lambda,就像在本书中看到的那些一样。它接受两个参数,一个 String 和一个 Int,并返回一个 String。lambda 主体也有两个参数,后面跟随必需的箭头:str, n ->。
vb 将 String 参数移到括号外,并使用扩展函数语法:String.(Int)。就像 扩展函数 一样,被扩展类型的对象(在这种情况下是 String)成为 接收者,可以使用 this 访问它。
在 vb 中的第一个调用使用了显式形式 this.repeat(it)。第二个调用省略了 this,得到了 repeat(it)。与任何 lambda 一样,如果只有一个参数(在这种情况下是 Int),it 将引用该参数。
在 main() 中,对 va() 的调用正是您从 lambda 类型声明 (String, Int) -> String 中所期望的——在传统函数调用中有两个参数。vb() 是一个扩展,因此可以使用扩展形式 "Vanbo".vb(2) 进行调用。vb() 也可以使用传统形式 vb("Vanbo", 2) 进行调用。va() 无法使用扩展形式进行调用。
当您首次看到扩展 lambda 时,似乎 String.(Int) 部分是您应该关注的。但是,String 并不是通过参数列表 (Int) 进行扩展的——它是通过整个 lambda 进行扩展的:String.(Int) -> String
Kotlin 文档通常将扩展 lambda 称为 带接收者的函数字面值。术语 函数字面值 包括 lambda 和匿名函数。术语 带接收者的 lambda 经常与 扩展 lambda 同义使用,以强调它是带有附加隐式参数的 lambda。
与扩展函数一样,扩展 lambda 可以有多个参数:
// ExtensionLambdas/Parameters.kt
package extensionlambdas
import atomictest.eq
val zero: Int.() -> Boolean = {
this == 0
}
val one: Int.(Int) -> Boolean = {
this % it == 0
}
val two: Int.(Int, Int) -> Boolean = {
arg1, arg2 ->
this % (arg1 + arg2) == 0
}
val three: Int.(Int, Int, Int) -> Boolean = {
arg1, arg2, arg3 ->
this % (arg1 + arg2 + arg3) == 0
}
fun main() {
0.zero() eq true
10.one(10) eq true
20.two(10, 10) eq true
30.three(10, 10, 10) eq true
}
在 one() 中,使用 it 替代了参数的命名。如果这产生了不清晰的语法,最好使用显式的参数名。
我们一直通过定义 val 来演示扩展 lambda,但它们通常以函数参数的形式出现,就像 f2() 中的例子:
// ExtensionLambdas/FunctionParameters.kt
package extensionlambdas
class A {
fun af() = 1
}
class B {
fun bf() = 2
}
fun f1(lambda: (A, B) -> Int) =
lambda(A(), B())
fun f2(lambda: A.(B) -> Int) =
A().lambda(B())
fun lambdas() {
f1 { aa, bb -> aa.af() + bb.bf() }
f2 { af() + it.bf() }
}
在 main() 中,注意在传递给 f2() 的 lambda 中更简洁的语法。
如果扩展 lambda 返回 Unit,则忽略 lambda 主体产生的结果:
// ExtensionLambdas/LambdaUnitReturn.kt
package extensionlambdas
fun unitReturn(lambda: A.() -> Unit) =
A().lambda()
fun nonUnitReturn(lambda: A.() -> String) =
A().lambda()
fun lambdaUnitReturn () {
unitReturn {
"Unit ignores the return value" +
"So it can be anything ..."
}
unitReturn { 1 } // ... of any type ...
unitReturn { } // ... or nothing
nonUnitReturn {
"Must return the proper type"
}
// nonUnitReturn { } // 不可行
}
您可以将扩展 lambda 传递给期望普通 lambda 的函数,只要参数列表彼此一致:
// ExtensionLambdas/Transform.kt
package extensionlambdas
import atomictest.eq
fun String.transform1(
n: Int, lambda: (String, Int) -> String
) = lambda(this, n)
fun String.transform2(
n: Int, lambda: String.(Int) -> String
) = lambda(this, n)
val duplicate: String.(Int) -> String = {
repeat(it)
}
val alternate: String.(Int) -> String = {
toCharArray()
.filterIndexed { i, _ -> i % it == 0 }
.joinToString("")
}
fun main() {
"hello".transform1(5, duplicate)
.transform2(3, alternate) eq "hleolhleo"
"hello".transform2(5, duplicate)
.transform1(3, alternate) eq "hleolhleo"
}
transform1() 期望普通的 lambda,而 transform2() 期望扩展 lambda。在 main() 中,扩展 lambda duplicate 和 alternate 都被传递给了 transform1() 和 transform2()。在任一 lambda 传递给 transform1() 时,扩展 lambda 中的 this 接收者变成了第一个 String 参数。
使用 ::,我们可以在期望扩展 lambda 的地方传递函数引用:
// ExtensionLambdas/FuncReferences.kt
package extensionlambdas
import atomictest.eq
fun Int.d1(f: (Int) -> Int) = f(this) * 10
fun Int.d2(f: Int.() -> Int) = f() * 10
fun f1(n: Int) = n + 3
fun Int.f2() = this + 3
fun main() {
74.d1(::f1) eq 770
74.d2(::f1) eq 770
74.d1(Int::f2) eq 770
74.d2(Int::f2) eq 770
}
对于扩展函数的引用与扩展 lambda 具有相同的类型:Int::f2 具有类型 Int.() -> Int。
在调用中 74.d1(Int::f2),我们将一个扩展函数传递给了 d1(),而该函数不声明扩展 lambda 参数。
多态适用于普通扩展函数(Base.g())和扩展 lambda(Base.h() 参数):
// ExtensionLambdas/ExtensionPolymorphism.kt
package extensionlambdas
import atomictest.eq
open class Base {
open fun f() = 1
}
class Derived : Base() {
override fun f() = 99
}
fun Base.g() = f()
fun Base.h(xl: Base.() -> Int) = xl()
fun main() {
val b: Base = Derived() // 向上转型
b.g() eq 99
b.h { f() } eq 99
}
您不会预料到它不起作用,但是通过创建一个示例来测试假设总是值得的。
您可以使用匿名函数语法(在 Local Functions 中描述)来替代扩展 lambda。在这里,我们使用了匿名扩展函数:
// ExtensionLambdas/AnonymousFunction.kt
package extensionlambdas
import atomictest.eq
fun exec(
arg1: Int, arg2: Int,
f: Int.(Int) -> Boolean
) = arg1.f(arg2)
fun main() {
exec(10, 2, fun Int.(d: Int): Boolean {
return this % d == 0
}) eq true
}
在 main() 中,对 exec() 的调用显示匿名扩展函数被接受为扩展 lambda。
Kotlin 标准库中包含许多使用扩展 lambda 的函数。例如,StringBuilder 是一个可修改的对象,当您调用 toString() 时,它会生成一个不可变的 String。相比之下,更现代的 buildString() 接受一个扩展 lambda。它创建自己的 StringBuilder 对象,将扩展 lambda 应用于该对象,然后调用 toString() 产生结果:
// ExtensionLambdas/StringCreation.kt
package extensionlambdas
import atomictest.eq
private fun messy(): String {
val built = StringBuilder() // [1]
built.append("ABCs: ")
('a'..'x').forEach { built.append(it) }
return built.toString() // [2]
}
private fun clean() = buildString {
append("ABCs: ")
('a'..'x').forEach { append(it) }
}
private fun cleaner() =
('a'..'x').joinToString("", "ABCs: ")
fun main() {
messy() eq "ABCs: abcdefghijklmnopqrstuvwx"
messy() eq clean()
clean() eq cleaner()
}
在 messy() 中,我们多次重复了名称 built。我们还必须创建一个 StringBuilder([1]),并产生结果([2])。在 clean() 中使用 buildString(),您不需要为 append() 调用创建和管理接收者,这使得一切更加简洁。
cleaner() 显示了,如果您愿意,有时可以找到一个更直接的解决方案,跳过构建器。
有与 buildString() 类似的标准库函数,它们使用扩展 lambda 生成已初始化的只读 List 和 Map:
// ExtensionLambdas/ListsAndMaps.kt
@file:OptIn(ExperimentalStdlibApi::class)
package extensionlambdas
import atomictest.eq
val characters: List<String> = buildList {
add("Chars:")
('a'..'d').forEach { add("$it") }
}
val charmap: Map<Char, Int> = buildMap {
('A'..'F').forEachIndexed { n, ch ->
put(ch, n)
}
}
fun main() {
characters eq "[Chars:, a, b, c, d]"
// characters eq characters2
charmap eq "{A=0, B=1, C=2, D=3, E=4, F=5}"
}
在扩展 lambda 内部,List 和 Map 是可变的,但是 buildList 和 buildMap 的结果是只读的 List 和 Map。
使用扩展 Lambda 编写构建器
假设您可以创建构造函数来生成所有必要的对象配置。有时候,可能的可能性太多,使得这变得混乱且不实际。构建器模式 具有以下几个优点:
- 它以多步过程创建对象。这在对象构建复杂的情
况下有时会很有帮助。 2. 它使用相同的基本构建代码来生成不同的对象变体。 3. 它将常见构建代码与特定代码分开,使编写和阅读各个对象变体的代码更加容易。
使用扩展 lambda 实现构建器提供了一个额外的好处,即创建了一个 领域特定语言(DSL)。DSL 的目标是对领域专家而非编程专家来说,具有舒适和合理的语法。这使得该用户只需了解一个小的语言子集,即可生成工作解决方案,同时从该语言的结构和安全性中受益。
例如,考虑一个捕获准备不同种类三明治的操作和成分的系统。我们可以使用类来建模 Recipe 的各个部分:
// ExtensionLambdas/Sandwich.kt
package sandwich
import atomictest.eq
open class Recipe : ArrayList<RecipeUnit>()
open class RecipeUnit {
override fun toString() =
"${this::class.simpleName}"
}
open class Operation : RecipeUnit()
class Toast : Operation()
class Grill : Operation()
class Cut : Operation()
open class Ingredient : RecipeUnit()
class Bread : Ingredient()
class PeanutButter : Ingredient()
class GrapeJelly : Ingredient()
class Ham : Ingredient()
class Swiss : Ingredient()
class Mustard : Ingredient()
open class Sandwich : Recipe() {
fun action(op: Operation): Sandwich {
add(op)
return this
}
fun grill() = action(Grill())
fun toast() = action(Toast())
fun cut() = action(Cut())
}
fun sandwich(
fillings: Sandwich.() -> Unit
): Sandwich {
val sandwich = Sandwich()
sandwich.add(Bread())
sandwich.toast()
sandwich.fillings()
sandwich.cut()
return sandwich
}
fun main() {
val pbj = sandwich {
add(PeanutButter())
add(GrapeJelly())
}
val hamAndSwiss = sandwich {
add(Ham())
add(Swiss())
add(Mustard())
grill()
}
pbj eq "[Bread, Toast, PeanutButter, " +
"GrapeJelly, Cut]"
hamAndSwiss eq "[Bread, Toast, Ham, " +
"Swiss, Mustard, Grill, Cut]"
}
sandwich() 捕获了生成任何 Sandwich 所需的基本成分和操作(在这里,我们假设所有三明治都是烤过的,但是在练习中,您将看到如何使其可选)。fillings 扩展 lambda 允许调用者以多种不同的方式配置 Sandwich,但不需要为每个配置创建构造函数。
main() 中的语法显示了该系统可能如何用作 DSL——用户只需要理解通过调用 sandwich() 并在大括号中提供成分和操作的语法,即可创建 Sandwich。
Exercises and solutions can be found at www.AtomicKotlin.com.
作用域函数
作用域函数 创建了一个临时作用域,您可以在其中访问对象而无需使用其名称。
作用域函数存在的目的仅在于使您的代码更简洁和可读。它们不提供额外的功能。
有五个作用域函数:let()、run()、with()、apply() 和 also()。它们设计用于与 lambda 一起工作,不需要 import。它们在访问 上下文对象 方面存在差异,使用 it 或 this,以及它们返回的内容。with() 使用与其他作用域函数不同的调用语法。下面您可以看到它们之间的区别:
// ScopeFunctions/Differences.kt
package scopefunctions
import atomictest.eq
data class Tag(var n: Int = 0) {
var s: String = ""
fun increment() = ++n
}
fun main() {
// let(): 使用 'it' 访问对象
// 返回 lambda 中的最后一个表达式的结果
Tag(1).let {
it.s = "let: ${it.n}"
it.increment()
} eq 2
// 带有命名 lambda 参数的 let():
Tag(2).let { tag ->
tag.s = "let: ${tag.n}"
tag.increment()
} eq 3
// run(): 使用 'this' 访问对象
// 返回 lambda 中的最后一个表达式的结果
Tag(3).run {
s = "run: $n" // 隐式 'this'
increment() // 隐式 'this'
} eq 4
// with(): 使用 'this' 访问对象
// 返回 lambda 中的最后一个表达式的结果
with(Tag(4)) {
s = "with: $n"
increment()
} eq 5
// apply(): 使用 'this' 访问对象
// 返回修改后的对象
Tag(5).apply {
s = "apply: $n"
increment()
} eq "Tag(n=6)"
// also(): 使用 'it' 访问对象
// 返回修改后的对象
Tag(6).also {
it.s = "also: ${it.n}"
it.increment()
} eq "Tag(n=7)"
// 带有命名 lambda 参数的 also():
Tag(7).also { tag ->
tag.s = "also: ${tag.n}"
tag.increment()
} eq "Tag(n=8)"
}
有多个作用域函数是因为它们满足不同的需求组合:
- 使用
this访问上下文对象的作用域函数(run()、with()和apply())在其作用域块中产生最干净的语法。 - 使用
it访问上下文对象的作用域函数(let()和also())允许您提供命名的 lambda 参数。 - 返回其 lambda 中的最后一个表达式的作用域函数(
let()、run()和with())用于创建结果。 - 返回修改后的上下文对象的作用域函数(
apply()和also())用于将表达式链接在一起。
run() 是一个常规函数,而 with() 是一个扩展函数;除此之外,它们是相同的。对于调用链和接收者可为空的情况,优先选择 run()。
下面是作用域函数特性的总结:
this 上下文 | it 上下文 | |
|---|---|---|
| 生成最后一个表达式的结果 | with、run | let |
| 生成接收者 | apply | also |
您可以使用 安全访问运算符 ?. 将作用域函数应用于可空接收者,只有在接收者不为 null 时才会调用作用域函数:
// ScopeFunctions/AndNullability.kt
package scopefunctions
import atomictest.eq
import kotlin.random.Random
fun gets(): String? =
if (Random.nextBoolean()) "str!" else null
fun main() {
gets()?.let {
it.removeSuffix("!") + it.length
}?.eq("str4")
}
在 main() 中,如果 gets() 产生非空结果,则会调用 let。let 的非空接收者变为 lambda 内部的非空 it。
将安全访问运算符应用于上下文对象会对整个作用域进行 null 检查,如下所示的 [1]-[4]。否则,在作用域内的每个调用都必须单独进行 null 检查:
// ScopeFunctions/Gnome.kt
package scopefunctions
class Gnome(val name: String) {
fun who() = "Gnome: $name"
}
fun whatGnome(gnome: Gnome?) {
gnome?.let { it.who() } // [1]
gnome.let { it?.who() }
gnome?.run { who() } // [2]
gnome.run { this?.who() }
gnome?.apply { who() } // [3]
gnome.apply { this?.who() }
gnome?.also { it.who() } // [4]
gnome.also { it?.who() }
// 对于 nullability 没有帮助:
with(gnome) { this?.who() }
}
当在 let()、run()、apply() 或 also() 上使用安全访问运算符时,如果上下文对象为 null,则整个作用域都将被忽略:
// ScopeFunctions/NullGnome.kt
package scopefunctions
import atomictest.*
fun whichGnome(gnome: Gnome?) {
trace(gnome?.name)
gnome?.let { trace(it.who()) }
gnome?.run { trace(who()) }
gnome?.apply { trace(who()) }
gnome?.also { trace(it.who()) }
}
fun main() {
whichGnome(Gnome("Bob"))
whichGnome(null)
trace eq """
Bob
Gnome: Bob
Gnome: Bob
Gnome: Bob
Gnome: Bob
null
"""
}
trace 显示,当 whichGnome() 接收到 null 参数时,没有作用域函数会执行。
尝试从 Map 中检索对象会产生可空的结果,因为没有保证它会找到该键的条目。在下面的示例中,我们展示了不同作用域函数应用于 Map 查找结果的情况:
// ScopeFunctions/MapLookup.kt
package scopefunctions
import atomictest.*
data class Plumbus(var id: Int)
fun display(map: Map<String, Plumbus>) {
trace("displaying $map")
val pb1: Plumbus = map["main"]?.let {
it.id += 10
it
} ?: return
trace(pb1)
val pb2: Plumbus? = map["main"]?.run {
id += 9
this
}
trace(pb2)
val pb3: Plumbus? = map["main"]?.apply {
id += 8
}
trace(pb3)
val pb4: Plumbus? = map["main"]?.also {
it.id += 7
}
trace(pb4)
}
fun main() {
display(mapOf("main" to Plumbus(1)))
display(mapOf("none" to Plumbus(2)))
trace eq """
displaying {main=Plumbus(id=1)}
Plumbus(id=11)
Plumbus(id=20)
Plumbus(id=28)
Plumbus(id=35)
displaying {none=Plumbus(id=2)}
"""
}
尽管 with() 可以在此示例中强制使用,但结果太难看,难以考虑。
在 trace 中,您可以看到在第一次调用 display() 时创建了每个 Plumbus 对象,但在第二次调用中没有创建任何对象。查看 pb1 的定义并回想起 Elvis 操作符。如果 ?: 左侧的表达式不为 null,则它变为结果并赋值给 pb1。但是,如果该表达式为 null,则 ?: 的右侧变为结果,即 return,因此在完成初始化 pb1 之前,display() 返回,因此 pb1-pb4 的任何值都不会创建。
在可链式调用中,作用域函数可以与可空类型一起使用:
// ScopeFunctions/NameTag.kt
package scopefunctions
import atomictest.trace
val functions = listOf(
fun(name: String?) {
name
?.takeUnless { it.isBlank() }
?.let { trace("$it in let") }
},
fun(name: String?) {
name
?.takeUnless { it.isBlank() }
?.run { trace("$this in run") }
},
fun(name: String?) {
name
?.takeUnless { it.isBlank() }
?.apply { trace("$this in apply") }
},
fun(name: String?) {
name
?.takeUnless { it.isBlank() }
?.also { trace("$it in also") }
},
)
fun main() {
functions.forEach { it(null) }
functions.forEach { it(" ") }
functions.forEach { it("Yumyulack") }
trace eq """
Yumyulack in let
Yumyulack in run
Yumyulack in apply
Yumyulack in also
"""
}
functions 是一个函数引用的 List,由 main() 中的 forEach 调用应用,使用 it 与函数调用语法。functions 中的每个函数都使用不同的作用域函数。对于 null 或空白输入,forEach 调用 it(null) 和 it(" ") 会被忽略。
在嵌套作用域函数时,在给定上下文中可能会有多个 this 或 it 对象可用。有时很难知道选择了哪个对象:
// ScopeFunctions/Nesting.kt
package scopefunctions
import atomictest.eq
fun nesting(s: String, i: Int): String =
with(s) {
with(i) {
toString()
}
} +
s.let {
i.let {
it.toString()
}
} +
s.run {
i.run {
toString()
}
} +
s.apply {
i.apply {
toString()
}
} +
s.also {
i.also {
it.toString()
}
}
fun main() {
nesting("X", 7) eq "777XX"
}
在所有情况下,对 toString() 的调用都是应用于 Int,因为最近的隐式 this 或 it 是 Int。apply() 和 also() 返回修改后的对象 s,而不是计算结果。由于作用域函数旨在提高可读性,因此嵌套作用域函数是一个值得怀疑的做法。
没有作用域函数提供类似于 use() 的 资源清理 功能:
// ScopeFunctions/Blob.kt
package scopefunctions
import atomictest.*
data class Blob(val id: Int) : AutoCloseable {
override fun toString() = "Blob($id)"
fun show() { trace("$this")}
override fun close() = trace("Close $this")
}
fun main() {
Blob(1).let { it.show() }
Blob(2).run { show() }
with(Blob(3)) { show() }
Blob(4).apply { show() }
Blob(5).also { it.show() }
Blob(6).use { it.show() }
Blob(7).use { it.run { show() } }
Blob(8).apply { show() }.also { it.close() }
Blob(9).also { it.show() }.apply { close() }
Blob(10).apply { show() }.use { }
trace eq """
Blob(1)
Blob(
2)
Blob(3)
Blob(4)
Blob(5)
Blob(6)
Close Blob(6)
Blob(7)
Close Blob(7)
Blob(8)
Close Blob(8)
Blob(9)
Close Blob(9)
Blob(10)
Close Blob(10)
"""
}
尽管 use() 在视觉上与 let() 和 also() 相似,但 use() 不允许从其 lambda 中返回任何内容。这防止了表达式链接或生成结果。
没有 use(),对于任何作用域函数,close() 都不会被调用。要使用作用域函数并保证清理,将作用域函数置于 use() lambda 内部,如 Blob(7) 所示。Blob(8) 和 Blob(9) 展示了如何显式调用 close(),以及如何交替使用 apply() 和 also()。
Blob(10) 使用 apply(),结果传递给 use(),在其 lambda 结束时调用 close()。
作用域函数是内联的
通常,将 lambda 作为参数传递会将 lambda 代码存储在辅助对象中,与常规函数调用相比,会增加一些运行时开销,但考虑到 lambda 的好处(可读性和代码结构),这种开销通常不是一个问题。此外,JVM 中包含许多优化,通常可以弥补开销。
不管开销有多小,只要有运行时开销,无论多么小,都会产生“谨慎使用某个功能”的建议。通过将作用域函数定义为 inline,可以消除所有的运行时开销。这样,就可以毫不犹豫地使用作用域函数。
当编译器看到 inline 函数调用时,它将函数体替换为函数调用,将所有参数替换为实际参数。
内联对于小型函数效果很好,其中函数调用的开销可能是整个调用的重要部分。随着函数变得越来越大,与整个调用所需的时间相比,调用的成本会缩小,从而降低了内联的价值。与此同时,生成的字节码会增加,因为在每个调用点都插入了整个函数体。
当内联函数接受一个 lambda 参数时,编译器将 lambda 体与函数体一起内联。因此,在将 lambda 直接调用或传递给另一个 inline 函数时,不会创建其他类或对象来传递 lambda。 (这仅在直接调用 lambda 或传递给另一个 inline 函数时才有效)。
尽管可以将其应用于任何函数,但 inline 用于内联 lambda 体或创建 具体化泛型 是有意义的。您可以在 这里 找到有关内联函数的更多信息。
练习和解答可在 www.AtomicKotlin.com 找到。
创建泛型
泛型代码可以与“稍后指定的类型”一起工作。
普通的类和函数适用于特定的类型。如果您希望代码适用于更多类型,这种刚性可能过于约束性。
多态 是一种面向对象的泛化工具。您编写一个接受基类对象作为参数的函数,然后使用来自该基类派生的任何类的对象调用该函数,包括尚未创建的类。现在,您的函数变得更加通用,在更多地方变得有用。
单个继承层次结构可能过于局限,因为您必须从该继承层次结构中继承以生成适合函数参数的对象。如果函数参数是接口而不是类,则限制会放松,以包括任何实现该接口的内容。这使客户程序员有机会在现有类与接口的组合中实现接口,即将现有类“适配”到函数中。以这种方式使用接口可以跨类层次结构。
有时,甚至接口也过于限制,因为它强制您只能使用该接口。如果代码与“某种未指定的类型”一起工作,而不是特定的接口或类,那么您的代码可以更加通用。这个“未指定的类型”是 泛型类型参数。
创建泛型类型和函数是一个相当复杂的主题,其中大部分内容超出了本书的范围。这篇文章试图为您提供足够的背景,以便在遇到泛型概念和关键字时不会感到惊讶。如果您想认真编写泛型类型和函数,您需要学习更高级的资源。
Any
Any 是 Kotlin 类层次结构的根。每个 Kotlin 类都有 Any 作为其超类。一种处理未指定类型的方法是通过传递 Any 参数来实现的,这有时可能会混淆何时使用泛型。如果 Any 可行,它是更简单的解决方案,而简单通常更好。
使用 Any 有两种方法。第一种方法是当您只需要对 Any 进行操作,仅此而已。这非常有限 - Any 仅具有三个成员函数:equals()、hashCode() 和 toString()。还有扩展函数,但这些函数无法对类型执行任何直接操作。例如,apply() 仅将其函数参数应用于 Any。
如果您知道 Any 的类型,可以将其转换并执行特定于类型的操作。因为这涉及运行时类型信息(如向下转型所示),所以如果将错误类型传递给函数,就会产生运行时错误(还会有轻微的性能影响)。有时,为了消除代码重复,这是合理的。
例如,假设三种类型都有通信的能力。它们来自不同的库,因此您不能将它们放在同一个层次结构中,并且它们具有不同的通信函数名称:
// CreatingGenerics/Speakers.kt
package creatinggenerics
import atomictest.eq
class Person {
fun speak() = "Hi!"
}
class Dog {
fun bark() = "Ruff!"
}
class Robot {
fun communicate() = "Beep!"
}
fun talk(speaker: Any) = when (speaker) {
is Person -> speaker.speak()
is Dog -> speaker.bark()
is Robot -> speaker.communicate()
else -> "Not a talker" // Or exception
}
fun main() {
talk(Person()) eq "Hi!"
talk(Dog()) eq "Ruff!"
talk(Robot()) eq "Beep!"
talk(11) eq "Not a talker"
}
when 表达式发现了 speaker 的类型并调用了适当的函数。如果您认为 talk() 永远不需要与其他类型一起工作,那么这是一个可以容忍的解决方案。否则,它要求您为每种添加的新类型修改 talk(),并且依赖于运行时信息来发现何时遗漏了某些内容。
定义泛型
重复的代码可以转换为泛型函数或类型。您可以通过添加带有一个或多个泛型占位符的尖括号(<>)来实现此目的。在这里,泛型占位符 T 代表未知类型:
// CreatingGenerics/DefiningGenerics.kt
package creatinggenerics
fun <T> gFunction(arg: T): T = arg
class GClass<T>(val x: T) {
fun f(): T = x
}
class GMemberFunction {
fun <T> f(arg: T): T = arg
}
interface GInterface<T> {
val x: T
fun f(): T
}
class GImplementation<T>(
override val x: T
) : GInterface<T> {
override fun f(): T = x
}
class ConcreteImplementation
: GInterface<String> {
override val x: String
get() = "x"
override fun f() = "f()"
}
fun basicGenerics() {
gFunction("Yellow")
gFunction(1)
gFunction(Dog()).bark() // [1]
gFunction<Dog>(Dog()).bark()
GClass("Cyan").f()
GClass(11).f()
GClass(Dog()).f().bark() // [2]
GClass<Dog>(Dog()).f().bark()
GMemberFunction().f("Amber")
GMemberFunction().f(111)
GMemberFunction().f(Dog()).bark() // [3]
GMemberFunction().f<Dog>(Dog()).bark()
GImplementation("Cyan").f()
GImplementation(11).f()
GImplementation(Dog()).f().bark()
ConcreteImplementation().f()
ConcreteImplementation().x
}
basicGenerics() 显示了每个泛型如何处理不同类型:
gFunction()接受类型为T的参数并返回类型为T的结果。GClass存储T。其成员函数f()返回T。GMemberFunction在类内部参数化成员函数,而不是在整个类内部参数化。- 您还可以定义具有泛型参数的
interface,如GInterface所示。GInterface的实现可以重新定义类型参数,如GImplementation所示,也可以提供特定的类型参数,如ConcreteImplementation所示。
注意在 [1]、[2] 和 [3] 中,我们能够在结果上调用 bark(),因为该结果出现为类型 Dog。
考虑 [1]、[2] 和 [3],以及紧随其后的行。类型 T 是通过 [1]、[2] 和 [3] 的类型推断确定的。有时,如果泛型或其调用过于复杂,编译器无法解析它,则无法确定类型(类型推断)。在这种情况下,必须使用紧随 [1]、[2] 和 [3] 的行中所示的语法指定类型。
保留类型信息
正如您将在本文档后面看到的那样,泛型类和函数中的代码无法知道 T 的类型 - 这称为 擦除。泛型可以被认为是一种保留返回值类型信息的方式。这样,您就不必编写代码来显式检查和将返回值强制转换为所需的类型。
泛型代码的一个常见用途是用于保存其他对象的容器。考虑一个 CarCrate 类,它作为一个简单的集合,通过保存和生成一个类型为 Car 的单个元素来运作:
// CreatingGenerics/CarCrate.kt
package creatinggenerics
import atomictest.eq
class Car {
override fun toString() = "Car"
}
class CarCrate(private var c: Car) {
fun put(car: Car) { c = car }
fun get(): Car = c
}
fun main() {
val cc = CarCrate(Car())
val car: Car = cc.get()
car eq "Car"
}
当我们调用 cc.get() 时,结果以类型 Car 返回。我们想要将此工具提供给比仅仅是 Car 的更多对象,因此我们将这个类泛化为 Crate<T>:
// CreatingGenerics/Crate.kt
package creatinggenerics
import atomictest.eq
open class Crate<T>(private var contents: T) {
fun put(item: T) { contents = item }
fun get(): T = contents
}
fun main() {
val cc = Crate(Car())
val car: Car = cc.get()
car eq "Car"
}
Crate<T> 确保只能将 T 放入 Crate,并且在对该 Crate 调用 get() 时,结果以类型 T 返回。
我们可以通过定义一个泛型扩展函数来为 Crate 制作一个 map() 版本:
// CreatingGenerics/MapCrate.kt
package creatinggenerics
import atomictest.eq
fun <T, R> Crate<T>.map(f:(T) -> R): List<R> =
listOf(f(get()))
fun main() {
Crate(Car()).map { it.toString() + "x" } eq
"[Carx]"
}
map() 返回通过将 f() 应用于输入序列中的每个元素而产生的结果的 List。由于 Crate 仅包含一个元素,因此结果始终是一个只包含一个元素的 List。有两个泛型参数:T 用于输入值,R 用于结果,允许 f() 生成与输入类型不同的结果类型。
类型参数约束
类型参数约束 表示泛型参数类型必须从约束继承。<T : Base> 表示 T 必须是类型 Base 或从 Base 派生的类型。本节展示了使用约束与继承 Base 的非泛型类型是不同的。
考虑一种类型层次结构,该层次结构模拟了不同的物品以及处理它们的方式:
// CreatingGenerics/Disposable.kt
package creatinggenerics
import atomictest.eq
interface Disposable {
val name: String
fun action(): String
}
class Compost(override val name: String) :
Disposable {
override fun action() = "Add to composter"
}
interface Transport : Disposable
class Donation(override val name: String) :
Transport {
override fun action() = "Call for pickup"
}
class Recyclable(override val name: String) :
Transport {
override fun action() = "Put in bin"
}
class Landfill(override val name: String) :
Transport {
override fun action() = "Put in dumpster"
}
val items = listOf(
Compost("Orange Peel"),
Compost("Apple Core"),
Donation("Couch"),
Donation("Clothing"),
Recyclable("Plastic"),
Recyclable("Metal"),
Recyclable("Cardboard"),
Landfill("Trash"),
)
val recyclables =
items.filterIsInstance<Recyclable>()
通过约束,我们可以在泛型函数内访问约束类型的属性和函数:
// CreatingGenerics/Constrained.kt
package creatinggenerics
import atomictest.eq
fun <T: Disposable> nameOf(disposable: T) =
disposable.name
// 作为扩展:
fun <T: Disposable> T.name() = name
fun main() {
recyclables.map { nameOf(it) } eq
"[Plastic, Metal, Cardboard]"
recyclables.map { it.name() } eq
"[Plastic, Metal, Cardboard]"
}
我们不能在没有约束的情况下访问 name。
这实现了相同的结果,但不使用泛型约束:
// CreatingGenerics/NonGenericConstraint.kt
package creatinggenerics
import atomictest.eq
fun nameOf2(disposable: Disposable) =
disposable.name
fun Disposable.name2() = name
fun main() {
recyclables.map { nameOf2(it) } eq
"[Plastic, Metal, Cardboard]"
recyclables.map { it.name2() } eq
"[Plastic, Metal, Cardboard]"
}
为什么要使用约束而不是普通的多态性?答案在于返回类型。使用泛型时,返回类型可以是精确的,而不是将其向上转换为基础类型:
// CreatingGenerics/SameReturnType.kt
package creatinggenerics
import kotlin.random.Random
private val rnd = Random(47)
fun List<Disposable>.aRandom(): Disposable =
this[rnd.nextInt(size)]
fun <T: Disposable> List<T>.bRandom(): T =
this[rnd.nextInt(size)]
fun <T> List<T>.cRandom(): T =
this[rnd.nextInt(size)]
fun sameReturnType() {
val a: Disposable = recyclables.aRandom()
val b: Recyclable = recyclables.bRandom()
val c: Recyclable = recyclables.cRandom()
}
在没有泛型的情况下,aRandom() 只能生成一个基类 Disposable,而
bRandom() 和 cRandom() 都生成一个 Recyclable。bRandom() 从不访问 T 的任何元素,因此它的约束是无意义的,最终它与不使用约束的 cRandom() 相同,后者不使用约束。
只有在满足以下 两个 条件时,您才需要约束:
- 访问函数或属性。
- 保留在返回时的类型。
// CreatingGenerics/Constraints.kt
package creatinggenerics
import kotlin.random.Random
private val rnd = Random(47)
// 访问 action() 但不能
// 返回确切的类型:
fun List<Disposable>.inexact(): Disposable {
val d: Disposable = this[rnd.nextInt(size)]
d.action()
return d
}
// 不能在没有约束的情况下访问 action():
fun <T> List<T>.noAccess(): T {
val d: T = this[rnd.nextInt(size)]
// d.action()
return d
}
// 访问 action() 并返回确切的类型:
fun <T: Disposable> List<T>.both(): T {
val d: T = this[rnd.nextInt(size)]
d.action()
return d
}
fun constraints() {
val i: Disposable = recyclables.inexact()
val n: Recyclable = recyclables.noAccess()
val b: Recyclable = recyclables.both()
}
类型擦除
Java 的兼容性是 Kotlin 的一个重要部分。在 Java 中,泛型不是原始语言的一部分 - 它们是在许多代码已经编写后的几年后添加的。将泛型强行引入 Java 而不破坏现有代码需要一个重要的妥协:泛型类型仅在编译期间可用,但在运行时不保留类型 - 类型被 擦除。这个 擦除 影响了 Kotlin。
让我们假设不会发生擦除:
// CreatingGenerics/Erasure.kt
package creatinggenerics
fun main() {
val strings = listOf("a", "b", "c")
val all: List<Any> = listOf(1, 2, "x")
useList(strings)
useList(all)
}
fun useList(list: List<Any>) {
// if (list is List<String>) {} // [1]
}
取消注释 [1] 行,您会看到以下错误:“Cannot check for instance of erased type: List<String>”。您无法在运行时检查泛型类型,因为类型信息已被擦除。
如果擦除 没有发生,列表可能如下所示,假设附加的类型信息放在列表末尾(实际上不是这样工作的!):
具体化的泛型
因为泛型类型被擦除,类型信息 不会 存储在 List 中。相反,strings 和 all 都只是 List,没有附加的类型信息:
擦除的泛型
您无法从 List 的内容中猜测出类型信息,而不需要分析所有元素。仅检查第二个列表的第一个元素会让您错误地认为它是 List<Int>。
Kotlin 设计者决定遵循 Java 并使用擦除,原因有两点:
- Java 兼容性。
- 开销。存储泛型类型信息会显著增加泛型
List或Map占用的内存。例如,标准的Map由许多Map.Entry对象组成,而Map.Entry是一个泛型类。因此,如果默认情况下在每个Map.Entry的键和值中都包含附加的类型信息,每个Map.Entry都会包含额外的类型信息。
泛型函数类型参数的具体化
泛型函数调用的类型信息也会被擦除,这意味着您无法在函数内部对泛型参数做太多操作。
要保留函数参数的类型信息,可以添加 reified 关键字。考虑一个需要类信息来执行任务的函数 a():
// CreatingGenerics/ReificationA.kt
package creatinggenerics
import kotlin.reflect.KClass
fun <T: Any> a(kClass: KClass<T>) {
// 使用 KClass<T>
}
当我们在第二个泛型函数 b() 内调用 a() 时,我们希望在泛型参数的类型信息中使用:
// CreatingGenerics/ReificationB.kt
package creatinggenerics
// 由于类型擦除,无法编译:
// fun <T: Any> b() = a(T::class)
当这段代码运行时,T 的类型信息被擦除,因此 b() 将无法编译。您无法在函数体内访问泛型类型参数的类。
Java 的解决方案是手动将类型信息传递到函数内部:
// CreatingGenerics/ReificationC.kt
package creatinggenerics
import kotlin.reflect.KClass
fun <T: Any> c(kClass: KClass<T>) = a(kClass)
class K
val kc = c(K::class)
显式传递类型信息应该是多余的,因为编译器知道 T 的类型,可以自动为您传递它。这实际上就是 reified 关键字的作用。
要使用 reified,函数还必须是 inline 的:
// CreatingGenerics/ReificationD.kt
package creatinggenerics
inline fun <reified T: Any> d() = a(T::class)
val kd = d<K>()
d() 产生与 c() 相同的效果,但 d() 不需要作为参数传递类引用。
reified 告诉编译器保留与相应类型参数的信息。现在,类型信息在运行时可用,因此您可以在函数体内访问它。
具体化允许在泛型参数类型上使用 is:
// CreatingGenerics/CheckType.kt
package creatinggenerics
import atomictest.eq
inline fun <reified T> check(t: Any) = t is T
// fun <T> check1(t: Any) = t is T // [1]
fun main() {
check<String>("1") eq true
check<Int>("1") eq false
}
- [1] 没有
reified,类型信息被擦除,因此无法检查给定的元素是否是T的实例。
在下面的示例中,select() 为特定子类型的每个 Disposable 项生成 name。它使用 reified 结合约束:
// CreatingGenerics/Select
.kt
package creatinggenerics
import atomictest.eq
inline fun <reified T : Disposable> select() =
items.filterIsInstance<T>().map { it.name }
fun main() {
select<Compost>() eq
"[Orange Peel, Apple Core]"
select<Donation>() eq "[Couch, Clothing]"
select<Recyclable>() eq
"[Plastic, Metal, Cardboard]"
select<Landfill>() eq "[Trash]"
}
库函数 filterIsInstance() 本身就是使用 reified 关键字定义的。
变异
将泛型与继承相结合会产生两个维度的变化。如果您有一个 Container<T>,并且想要将其分配给一个 Container<U>,其中 T 和 U 之间有继承关系,那么必须使用 in 或 out 变异注解 对 Container 进行约束,具体取决于您希望如何使用 Container。
这里有三个版本的 Box 容器:一个基本的 Box<T>,一个使用 <in T>,一个使用 <out T>:
// CreatingGenerics/InAndOutBoxes.kt
package variance
class Box<T>(private var contents: T) {
fun put(item: T) { contents = item }
fun get(): T = contents
}
class InBox<in T>(private var contents: T) {
fun put(item: T) { contents = item }
}
class OutBox<out T>(private var contents: T) {
fun get(): T = contents
}
in T 表示类的成员函数只能接受类型为 T 的参数,但不能返回类型为 T 的值。也就是说,可以将 T 对象放入 InBox 中,但不能取出。
out T 表示成员函数可以返回 T 对象,但不能接受类型为 T 的参数 - 您不能将 T 对象放入 OutBox。
为什么我们需要这些约束?考虑以下层次结构:
// CreatingGenerics/Pets.kt
package variance
open class Pet
class Cat : Pet()
class Dog : Pet()
Cat 和 Dog 都是 Pet 的子类型。在 Box<Cat> 和 Box<Pet> 之间是否存在子类型关系?似乎我们应该能够将 Cat 的 Box 分配给 Pet 的 Box 或分配给 Any 的 Box(因为 Any 是一切的超类型):
// CreatingGenerics/BoxAssignment.kt
package variance
val catBox = Box<Cat>(Cat())
// val petBox: Box<Pet> = catBox
// val anyBox: Box<Any> = catBox
如果 Kotlin 允许这样做,petBox 将具有 put(item: Pet)。Dog 也是一个 Pet,这将允许您将 Dog 放入 catBox,违反了 catBox 的“猫性”。
更糟糕的是,anyBox 将具有 put(item: Any),因此您可以将 Any 放入 catBox - 容器将完全没有类型安全性。
如果我们阻止使用 put(),这些分配就是安全的,因为没有人可以将 Dog 放入 OutBox<Cat>。编译器允许我们将 OutBox<Cat> 分配给 OutBox<Pet> 或 OutBox<Any>,因为 out 注解防止它们具有 put() 函数:
// CreatingGenerics/OutBoxAssignment.kt
package variance
val outCatBox: OutBox<Cat> = OutBox(Cat())
val outPetBox: OutBox<Pet> = outCatBox
val outAnyBox: OutBox<Any> = outCatBox
fun getting() {
val cat: Cat = outCatBox.get()
val pet: Pet = outPetBox.get()
val any: Any = outAnyBox.get()
}
没有 put(),我们无法将 Dog 放入 OutBox<Cat>,因此其“猫性”得以保留。
没有 get(),InBox<Any> 可以分配给 InBox<Pet>、InBox<Cat> 或 InBox<Dog>:
// CreatingGenerics/InBoxAssignment.kt
package variance
val inBoxAny: InBox<Any> = InBox(Any())
val inBoxPet: InBox<Pet> = inBoxAny
val inBoxCat: InBox<Cat> = inBoxAny
val inBoxDog: InBox<Dog> = inBoxAny
fun main() {
inBoxAny.put(Any())
inBoxAny.put(Pet())
inBoxAny.put(Cat())
inBoxAny.put(Dog())
inBoxPet.put(Pet())
inBoxPet.put(Cat())
inBoxPet.put(Dog())
inBoxCat.put(Cat())
inBoxDog.put(Dog())
}
可以将 Any、Pet、Cat 或 Dog 放入 InBox<Any> 中,而只能将 Pet、Cat 或 Dog 放入 InBox<Pet>。inBoxCat 和 inBoxDog 只能接受 Cat 和 Dog。这是我们希望拥有这些类型参数的盒子的行为,编译器强制执行它。
以下是 Box、OutBox 和 InBox 的子类型关系摘要:
变异性
Box<T>是 不变 的。这意味着Box<Cat>和Box<Pet>之间都不是子类型,因此不能相互分配。OutBox<out T>是 协变 的。这意味着OutBox<Cat>是OutBox<Pet>的子类型。将OutBox<Cat>向上转换为OutBox<Pet>时,它以与将
Cat 向上转换为 Pet 相同的方式变化。
InBox<in T>是 逆变 的。这意味着InBox<Pet>是InBox<Cat>的子类型。将InBox<Pet>向上转换为InBox<Cat>时,它以与将Cat向上转换为Pet相反的方式变化。
Kotlin 标准库中的只读 List 是协变的。您可以将 List<Cat> 分配给 List<Pet>。MutableList 是不变的,因为它包含一个 add():
// CreatingGenerics/CovariantList.kt
package variance
fun main() {
val catList: List<Cat> = listOf(Cat())
val petList: List<Pet> = catList
var mutablePetList: MutableList<Pet> =
mutableListOf(Cat())
mutablePetList.add(Dog())
// 类型不匹配:
// mutablePetList =
// mutableListOf<Cat>(Cat()) // [1]
}
- [1] 如果此赋值有效,我们可以通过将
Dog添加到mutableListOf<Cat>来违反mutableListOf<Cat>的“猫性”。
函数可以具有 协变返回类型。这意味着覆盖函数可以返回比其覆盖的函数更具体的类型:
// CreatingGenerics/CovariantReturnTypes.kt
package variance
interface Parent
interface Child : Parent
interface X {
fun f(): Parent
}
interface Y : X {
override fun f(): Child
}
请注意,Y 中覆盖的 f() 返回 Child,而 X 中的 f() 返回 Parent。
本小节只是对 变异性 主题的初步介绍。
- -
重复的代码适合使用泛型类型或函数。本文仅提供了基本的理解,如果您需要更深入的了解,您必须在更高级的教程中找到它。
练习和解答可以在 www.AtomicKotlin.com 上找到。
操作符重载
在计算机编程的上下文中,重载 意味着“为已经存在的东西添加额外的含义”。
操作符重载 允许你为类似 + 这样的操作符赋予你的新类型一定的意义,或者为现有类型赋予额外的含义。
操作符重载经历了一个风雨飘摇的历史。它在C++中得到了推广,但由于C++没有垃圾回收机制,编写重载的操作符变得困难。因此,早期的Java设计者认为操作符重载是“不好的”,并且没有在Java中允许操作符重载,尽管Java的垃圾回收机制本应使其相对容易实现。在垃圾回收支持下,操作符重载的简单性在Python语言中得以展示,该语言限制了你可以使用的一组有限(熟悉的)操作符,类似于C++。随后,Scala尝试允许你发明自己的操作符,导致一些程序员滥用此功能并编写了难以理解的代码。Kotlin从这些语言中汲取了经验教训,简化了操作符重载的过程,但限制了你的选择,将其限制在一个合理且熟悉的操作符集合中。此外,操作符优先级的规则是不能改变的。
我们将创建一个小型类 Num,并通过重载的扩展函数添加一个 + 操作符。要重载一个操作符,你需要在 fun 前使用 operator 关键字,后跟该操作符的特殊预定义函数名。例如,+ 操作符的特殊函数名是 plus():
// OperatorOverloading/Num.kt
package operatoroverloading
import atomictest.eq
data class Num(val n: Int)
operator fun Num.plus(rval: Num) =
Num(n + rval.n)
fun main() {
Num(4) + Num(5) eq Num(9)
Num(4).plus(Num(5)) eq Num(9)
}
如果你正在为在两个操作数之间使用的普通(非操作符)函数进行定义,你可以使用 infix 关键字,但操作符本身已经是 infix 了。因为 plus() 是一个普通的函数,你也可以以常规方式调用它。
当你将操作符定义为成员函数时,你可以访问类中的 private 元素,而扩展函数则不能:
// OperatorOverloading/MemberOperator.kt
package operatoroverloading
import atomictest.eq
data class Num2(private val n: Int) {
operator fun plus(rval: Num2) =
Num2(n + rval.n)
}
// 无法访问 'n':它在 'Num2' 中是私有的:
// operator fun Num2.minus(rval: Num2) =
// Num2(n - rval.n)
fun main() {
Num2(4) + Num2(5) eq Num2(9)
}
在某些情况下,为操作符创建特殊含义是有帮助的。在这里,我们模拟了一个 Molecule,使用 + 将其附加到另一个 Molecule 上。attached 属性是连接两个 Molecule 的链接:
// OperatorOverloading/Molecule.kt
package operatoroverloading
import atomictest.eq
data class Molecule(
val id: Int = idCount++,
var attached: Molecule? = null
) {
companion object {
private var idCount = 0
}
operator fun plus(other: Molecule) {
attached = other
}
}
fun main() {
val m1 = Molecule()
val m2 = Molecule()
m1 + m2 // [1]
m1 eq "Molecule(id=0, attached=" +
"Molecule(id=1, attached=null))"
}
- [1] 读起来像一个熟悉的数学表达式,但对于使用该模型的人来说,这可能是一个特别有意义的语法。
这个示例还不完整;如果你添加了一行 m2 + m1,然后尝试显示 m2,你将会遇到堆栈溢出问题(你能解决这个问题吗?)。
相等性
调用 ==(相等性)或 !=(不相等性)会调用 equals() 成员函数。data 类会自动重新定义 equals() 来比较存储的数据,但是如果你不为非 data 类重新定义 equals(),默认版本将比较引用而不是内容:
// OperatorOverloading/DefaultEquality.kt
package operatoroverloading
import atomictest.eq
class A(val i: Int)
data class D(val i: Int)
fun main() {
// 普通类:
val a = A(1)
val b = A(1)
val c = a
(a == b) eq false
(a == c) eq true
// data 类:
val d = D(1)
val e = D(1)
(d == e) eq true
}
a 和 b 引用了内存中的不同对象,所以引用是不同的,a == b 是 false,即使这两个对象存储了相同的数据。a 和 c 引用了内存中的相同对象,所以比较它们会产生 true。因为 data class D 自动生成了一个比较 D 内容的 equals(),所以 d == e 会产生 true。
equals() 是唯一一个不能作为扩展函数的操作符;它必须作为一个成员函数进行覆盖。在
覆盖自己的 equals() 时,你会重写默认的 equals(other: Any?) 函数。注意 other 的类型是 Any?,而不是你的类的具体类型。这允许你将你的类型与其他类型进行比较,这意味着你必须选择允许比较的类型:
// OperatorOverloading/DefiningEquality.kt
package operatoroverloading
import atomictest.eq
class E(var v: Int) {
override fun equals(other: Any?) = when {
this === other -> true // [1]
other !is E -> false // [2]
else -> v == other.v // [3]
}
override fun hashCode(): Int = v
override fun toString() = "E($v)"
}
fun main() {
val a = E(1)
val b = E(2)
(a == b) eq false // a.equals(b)
(a != b) eq true // !a.equals(b)
// 引用相等性:
(E(1) === E(1)) eq false
}
- [1] 这是一个优化:如果
other引用了内存中的同一个对象,结果自动为true。三重等号符号===用于测试引用相等性。 - [2] 这确定
other的类型必须与当前类型相同。为了将E与其他类型进行比较,你可以添加更多的匹配表达式。 - [3] 这比较了存储的数据。此时编译器已经知道
other的类型是E,因此我们可以在没有强制转换的情况下访问other.v。
在覆盖 equals() 时,你还应该覆盖 hashCode()。这是一个复杂的话题,但基本规则是,如果两个对象相等,它们必须产生相同的 hashCode() 值。标准的数据结构如 Map 和 Set 在没有这个规则的情况下将无法正常工作。对于一个 open 类来说,情况会变得更加复杂,因为你必须将一个实例与所有可能的子类进行比较。你可以在Wikipedia上了解更多有关哈希的概念。
定义适当的 equals() 和 hashCode() 超出了本书的范围,我们在这里所做的只是演示了概念,并适用于我们简单示例的情况,但不适用于更复杂的情况。这种复杂性是为什么 data 类会创建自己的 equals() 和 hashCode() 的原因。如果你必须定义自己的 equals() 和 hashCode(),我们建议使用IntelliJ IDEA或Android Studio自动生成这些方法,方法是使用操作 Generate -> equals and hashCode。
当你使用 == 比较可为空的对象时,Kotlin 强制执行 null 检查。你可以使用 if 或 Elvis 操作符来实现这一点:
// OperatorOverloading/EqualsForNullable.kt
package operatoroverloading
import atomictest.eq
fun equalsWithIf(a: E?, b: E?) =
if (a === null)
b === null
else
a == b
fun equalsWithElvis(a: E?, b: E?) =
a?.equals(b) ?: (b === null)
fun main() {
val x: E? = null
val y = E(0)
val z: E? = null
(x == y) eq false
(x == z) eq true
equalsWithIf(x, y) eq false
equalsWithIf(x, z) eq true
equalsWithElvis(x, y) eq false
equalsWithElvis(x, z) eq true
}
equalsWithIf() 首先检查引用 a 是否为 null,在这种情况下,只有在引用 b 也是 null 时它们才会相等。如果 a 不是 null 引用,就使用成员 equals() 来比较两者。equalsWithElvis() 则使用 ?. 和 ?: 来实现相同的效果,更加简洁。
在Kotlin中,你可以通过扩展函数来定义基本的算术操作符,让它们适用于类 E:
// OperatorOverloading/ArithmeticOperators.kt
package operatoroverloading
import atomictest.eq
// 一元操作符:
operator fun E.unaryPlus() = E(v)
operator fun E.unaryMinus() = E(-v)
operator fun E.not() = this
// 增加/减少:
operator fun E.inc() = E(v + 1)
operator fun E.dec() = E(v - 1)
fun unary(a: E) {
+a // unaryPlus()
-a // unaryMinus()
!a // not()
var b = a
b++ // inc()(必须是 var)
b-- // dec()(必须是 var)
}
// 二元操作符:
operator fun E.plus(e: E) = E(v + e.v)
operator fun E.minus(e: E) = E(v - e.v)
operator fun E.times(e: E) = E(v * e.v)
operator fun E.div(e: E) = E(v % e.v)
operator fun E.rem(e: E) = E(v / e.v)
fun binary(a: E, b: E) {
a + b // a.plus(b)
a - b // a.minus(b)
a * b // a.times(b)
a / b // a.div(b)
a % b // a.rem(b)
}
// 增强赋值:
operator fun E.plusAssign(e: E) { v += e.v }
operator fun E.minusAssign(e: E) { v - e.v }
operator fun E.timesAssign(e: E) { v *= e.v }
operator fun E.divAssign(e: E) { v /= e.v }
operator fun E.remAssign(e: E) { v %= e.v }
fun assignment(a: E, b: E) {
a += b // a.plusAssign(b)
a -= b // a.minusAssign(b)
a *= b // a.timesAssign(b)
a /= b // a.divAssign(b)
a %= b // a.remAssign(b)
}
fun main() {
val a = E(2)
val b = E(3)
a + b eq E(5)
a * b eq E(6)
val x = E(1)
x += b * b
x eq E(10)
}
在编写扩展时,记住扩展类型的属性和函数是隐式可用的。例如,在 unaryPlus() 的定义中,E(v) 中的 v 是正在被扩展的 E 的属性。
请注意,x += e 可以解析为 x = x.plus(e),如果 x 是一个 var,或者解析为 x.plusAssign(e),如果 x 是 val,并且相应的 plusAssign() 成员可用。如果两个选项都可以工作,编译器将发出错误,指示它无法选择。
参数可以与扩展操作符所扩展的类型不同。在这里,E 的 + 操作符扩展接受一个 Int 参数:
// OperatorOverloading/DifferentTypes.kt
package operatoroverloading
import atomictest.eq
operator fun E.plus(i: Int) = E(v + i)
fun main() {
E(1) + 10 eq E(11)
}
操作符的优先级是固定的,对于内置类型和自定义类型来说是相同的。例如,乘法的优先级高于加法,二者的优先级都高于相等性。因此,1 + 2 * 3 == 7 是 true。你可以在文档中找到操作符优先级表。
有时在混合使用算术和编程操作符时,结果并不明显。在下面的示例中,我们结合了 + 操作符和 Elvis 操作符:
// OperatorOverloading/ConfusingPrecedence.kt
package operatoroverloading
import atomictest.eq
fun main() {
val x: Int? = 1
val y: Int = 2
val sum = x ?: 0 + y
sum eq 1
(x ?: 0) + y eq 3 // [1]
x ?: (0 + y) eq 1 // [2]
}
在 sum 中,+ 操作符的优先级高于 Elvis 操作符 ?:,所以结果是 1 ?: (0 + 2) == 1。这可能不是程序员想要的结果。当混合使用优先级不明显的不同操作时,建议添加括号,如 [1] 和 [2] 行所示。
比较操作
当你定义 compareTo() 时,所有的比较操作符 <、>、<=、>= 会自动可用:
// OperatorOverloading/Comparison.kt
package operatoroverloading
import atomictest.eq
operator fun E.compareTo(e: E): Int =
v.compareTo(e.v)
fun main() {
val a = E(2)
val b = E(3)
(a < b) eq true // a.compareTo(b) < 0
(a > b) eq false // a.compareTo(b) > 0
(a <= b) eq true // a.compareTo(b) <= 0
(a >= b) eq false // a.compareTo(b) >= 0
}
compareTo() 必须返回一个 Int 值,表示:
- 如果两个元素相等,返回
0。 - 如果第一个元素(接收者)大于第二个元素(参数),返回正值。
- 如果第一个元素小于第二个元素,返回负值。
区间和容器
rangeTo() 可以为 .. 操作符创建范围,而 contains() 可以指示一个值是否在范围内:
// OperatorOverloading/Ranges.kt
package operatoroverloading
import atomictest.eq
data class R(val r: IntRange) { // 范围
override fun toString() = "R($r)"
}
operator fun E.range
To(e: E) = R(v..e.v)
operator fun R.contains(e: E): Boolean =
e.v in r
fun main() {
val a = E(2)
val b = E(3)
val r = a..b // a.rangeTo(b)
(a in r) eq true // r.contains(a)
(a !in r) eq false // !r.contains(a)
r eq R(2..3)
}
容器访问
通过重载 contains(),你可以检查一个值是否在容器中,而 get() 和 set() 支持使用方括号读取和分配容器中的元素:
// OperatorOverloading/ContainerAccess.kt
package operatoroverloading
import atomictest.eq
data class C(val c: MutableList<Int>) {
override fun toString() = "C($c)"
}
operator fun C.contains(e: E) = e.v in c
operator fun C.get(i: Int): E = E(c[i])
operator fun C.set(i: Int, e: E) {
c[i] = e.v
}
fun main() {
val c = C(mutableListOf(2, 3))
(E(2) in c) eq true // c.contains(E(2))
(E(4) in c) eq false // c.contains(E(4))
c[1] eq E(3) // c.get(1)
c[1] = E(4) // c.set(2, E(4))
c eq C(mutableListOf(2, 4))
}
在 IntelliJ IDEA 或 Android Studio 中,你可以从使用处导航到函数或类的声明中。这也适用于操作符:你可以将光标放在 .. 上,然后导航到其定义,以查看调用了哪个操作符函数。
调用操作
在对象后面加上括号会生成对 invoke() 的调用,因此 invoke() 操作符使对象看起来像一个函数。你可以定义带有任意数量参数的 invoke():
// OperatorOverloading/Invoke.kt
package operatoroverloading
import atomictest.eq
class Func {
operator fun invoke() = "invoke()"
operator fun invoke(i: Int) = "invoke($i)"
operator fun invoke(i: Int, j: String) =
"invoke($i, $j)"
operator fun invoke(
i: Int, j: String, k: Double
) = "invoke($i, $j, $k)"
}
fun main() {
val f = Func()
f() eq "invoke()"
f(22) eq "invoke(22)"
f(22, "Hi") eq "invoke(22, Hi)"
f(22, "Three", 3.1416) eq
"invoke(22, Three, 3.1416)"
}
你还可以将带有 vararg 的 invoke() 定义为与相同类型的任意数量的参数一起使用(详见可变参数列表)。
invoke() 也可以定义为扩展函数。在这里,它是一个对 String 的扩展,接受一个函数作为参数,并在该函数上调用 String:
// OperatorOverloading/StringInvoke.kt
package operatoroverloading
import atomictest.eq
operator fun String.invoke(
f: (s: String) -> String
) = f(this)
fun main() {
"mumbling" { it.toUpperCase() } eq
"MUMBLING"
}
由于 lambda 是最终的 invoke() 参数,可以在不使用括号的情况下直接调用它。
如果你有一个函数引用,可以使用它通过括号直接调用函数,或通过 invoke() 调用:
// OperatorOverloading/InvokeFunctionType.kt
package operatoroverloading
import atomictest.eq
fun main() {
val func: (String) -> Int = { it.length }
func("abc") eq 3
func.invoke("abc") eq 3
val nullableFunc: ((String) -> Int)? = null
if (nullableFunc != null) {
nullableFunc("abc")
}
nullableFunc?.invoke("abc") // [1]
}
- [1] 如果函数引用可为空,可以将
invoke()和安全访问组合使用。
自定义 invoke() 最常见的用途是在创建 DSL 时。
用反引号括起来的函数名
Kotlin 允许在函数名前后使用反引号来包含空格、特定的非标准字符和保留字:
// OperatorOverloading/Backticks.kt
package operatoroverloading
fun `A long name with spaces`() = Unit
fun `*how* is this working?`() = Unit
fun `'when' is a keyword`() = Unit
// fun `Illegal characters :<>`() = Unit
fun main() {
`A long name with spaces`()
`*how* is this working?`()
`'when' is a keyword`()
}
这在单元测试中特别有用,因为你可以创建包含关于测试细节的可读性良好的测试名称。它还简化了与 Java 代码的交互。
你可以轻松地创建难以理解的代码:
// OperatorOverloading/Swearing.kt
package operatoroverloading
import atomictest.eq
infix fun String.`#!%`(s: String) =
"$this Rowzafrazaca $s"
fun main() {
"howdy" `#!%` "Ma'am!" eq
"howdy Rowzafrazaca Ma'am!"
}
Kotlin 接受这种代码,但是对于读者来说这意味着什么呢?因为代码被阅读的次数远远多于编写的次数,所以你应该使你的程序尽可能易于理解。
- -
操作符重载不是一个必要的特性,但它是一个很好的例子,说明了语言不仅仅是操作底层计算机的方式。挑战在于通过精心设计语言来提供更好的方式来表达抽象概念,从而使人们更容易理解代码,而不会被不必要的细节所
困扰。虽然可以以使意义变得晦涩难懂的方式定义操作符,但请谨慎行事。
一切都是语法糖。卫生纸也是语法糖,但我仍然需要它。 —— 巴里·霍金斯
练习和解答可在 www.AtomicKotlin.com 找到。
使用操作符
在实际应用中,你很少会重载操作符 - 通常只有在创建自己的库时才会这样做。
然而,你经常会使用重载的操作符,通常是在不经意间使用。例如,Kotlin 标准库定义了许多操作符,可以改进集合的使用体验。以下是从新角度看待的一些熟悉代码:
// UsingOperators/NewAngle.kt
import atomictest.eq
fun main() {
val list = MutableList(10) { 'a' + it }
list[7] eq 'h' // operator get()
list.get(8) eq 'i' // 显式调用
list[9] = 'x' // operator set()
list.set(9, 'x') // 显式调用
list[9] eq 'x'
('d' in list) eq true // operator contains()
list.contains('e') eq true // 显式调用
}
使用方括号访问列表元素会调用重载的 get() 和 set() 操作符,而 in 运算符则调用了 contains()。
在可变集合上调用 += 会修改它,而调用 + 则返回一个新的集合,其中包含旧元素和新元素:
// UsingOperators/OperatorPlus.kt
import atomictest.eq
fun main() {
val mutableList = mutableListOf(1, 2, 3)
mutableList += 4 // operator plusAssign()
mutableList.plusAssign(5) // 显式调用
mutableList eq "[1, 2, 3, 4, 5]"
mutableList + 99 eq "[1, 2, 3, 4, 5, 99]"
mutableList eq "[1, 2, 3, 4, 5]"
val list = listOf(1) // 只读
val newList = list + 2 // operator plus()
list eq "[1]"
newList eq "[1, 2]"
val another = list.plus(3) // 显式调用
another eq "[1, 3]"
}
在只读集合上调用 += 可能不会产生你期望的结果:
// UsingOperators/Unexpected.kt
import atomictest.eq
fun main() {
var list = listOf(1, 2)
list += 3 // 可能是意外的
list eq "[1, 2, 3]"
}
在可变集合中,a += b 调用 plusAssign() 来修改 a。然而,对于只读集合,plusAssign() 是不可用的,因此 Kotlin 会将 a += b 重写为 a = a + b。这会调用 plus(),它不会改变集合,而是创建一个新的集合并将结果分配给 var list 引用。总体效果是 a += b 仍然为我们所期望的 a 的结果 - 至少对于像 Int 这样的简单类型来说。
// UsingOperators/ReadOnlyAndPlus.kt
import atomictest.eq
fun main() {
var list = listOf(1, 2)
val initial = list
list += 3
list eq "[1, 2, 3]"
list = list.plus(4)
list eq "[1, 2, 3, 4]"
initial eq "[1, 2]"
}
最后一行显示了 initial 集合保持不变。为每个添加的元素创建一个新集合可能不是你的意图。如果你在 list 上使用 val 而不是 var,则使用 += 将无法编译。这是使用 val 的另一个原因 - 只有在必要时使用 var。
compareTo() 在 操作符重载 中作为独立的扩展函数被引入。然而,如果你的类实现了 Comparable 接口并且重写了其 compareTo(),则会获得更大的好处:
// UsingOperators/CompareTo.kt
package usingoperators
import atomictest.eq
data class Contact(
val name: String,
val mobile: String
): Comparable<Contact> {
override fun compareTo(
other: Contact
): Int = name.compareTo(other.name)
}
fun main() {
val alice = Contact("Alice", "0123456789")
val bob = Contact("Bob", "9876543210")
val carl = Contact("Carl", "5678901234")
(alice < bob) eq true
(alice <= bob) eq true
(alice > bob) eq false
(alice >= bob) eq false
val contacts = listOf(bob, carl, alice)
contacts.sorted() eq
listOf(alice, bob, carl)
contacts.sortedDescending() eq
listOf(carl, bob, alice)
}
任何两个 Comparable 都可以使用 <、<=、> 和 >= 进行比较(请注意,== 和 != 不包括在内)。Kotlin 不需要在重写 compareTo() 时使用 operator 修饰符,因为它在 Comparable 接口中已经被定义为 operator。
实现 Comparable 也使得类具有可排序性,可以创建一个实例的范围而无需重新定义 .. 操作符。然后,你可以检查一个值是否在该范围内:
// UsingOperators/ComparableRange.kt
package usingoperators
import atomictest.eq
class F(val i: Int): Comparable<F> {
override fun compareTo(other: F) =
i.compareTo(other.i)
}
fun main() {
val range = F(1)..F(7)
(F(3) in range) eq true
(F(9) in range) eq false
}
最好是实现 Comparable。只有在使用你无法控制的类时,才将 compareTo() 定义为扩展函数。
解构操作符
另一组通常不会定义
的操作符是 componentN() 函数(component1()、component2() 等),用于 解构声明。在 main() 中,Kotlin 静默地生成了对解构赋值的 component1() 和 component2() 的调用:
// UsingOperators/DestructuringDuo.kt
package usingoperators
import atomictest.*
class Duo(val x: Int, val y: Int) {
operator fun component1(): Int {
trace("component1()")
return x
}
operator fun component2(): Int {
trace("component2()")
return y
}
}
fun main() {
val (a, b) = Duo(1, 2)
a eq 1
b eq 2
trace eq "component1() component2()"
}
相同的方法也适用于 Map,它们使用包含 component1() 和 component2() 成员函数的 Entry 类型:
// UsingOperators/DestructuringMap.kt
import atomictest.eq
fun main() {
val map = mapOf("a" to 1)
for ((key, value) in map) {
key eq "a"
value eq 1
}
// 解构赋值变成了:
for (entry in map) {
val key = entry.component1()
val value = entry.component2()
key eq "a"
value eq 1
}
}
你可以在任何 data 类上使用解构声明,因为 componentN() 函数会被自动生成:
// UsingOperators/DestructuringData.kt
package usingoperators
import atomictest.eq
data class Person(
val name: String,
val age: Int
) {
// 编译器生成:
// fun component1() = name
// fun component2() = age
}
fun main() {
val person = Person("Alice", 29)
val (name, age) = person
// 解构赋值变成了:
val name_ = person.component1()
val age_ = person.component2()
name eq "Alice"
age eq 29
name_ eq "Alice"
age_ eq 29
}
Kotlin 会为每个属性生成一个 componentN() 函数。
练习和解答可在 www.AtomicKotlin.com 找到。
属性委托
属性可以委托其访问器逻辑。
你可以使用 by 关键字将属性连接到一个委托:
val/var property by delegate
委托的类必须包含一个 getValue() 函数,如果属性是 val(只读),或者同时包含 getValue() 和 setValue() 函数,如果属性是 var(读/写)。首先考虑只读的情况:
// PropertyDelegation/BasicRead.kt
package propertydelegation
import atomictest.eq
import kotlin.reflect.KProperty
class Readable(val i: Int) {
val value: String by BasicRead()
}
class BasicRead {
operator fun getValue(
r: Readable,
property: KProperty<*>
) = "getValue: ${r.i}"
}
fun main() {
val x = Readable(11)
val y = Readable(17)
x.value eq "getValue: 11"
y.value eq "getValue: 17"
}
Readable 中的 value 被委托给了一个 BasicRead 对象。getValue() 接受一个 Readable 参数,使其能够访问 Readable 对象 - 当你使用 by 时,它会将 BasicRead 绑定到整个 Readable 对象。注意,getValue() 访问了 Readable 中的 i。
因为 getValue() 返回一个 String,所以 value 的类型也必须是 String。
第二个 getValue() 参数 property 是特殊类型 KProperty,它提供了关于委托属性的反射信息。
如果委托属性是一个 var,它必须处理读和写,因此委托类需要同时包含 getValue() 和 setValue():
// PropertyDelegation/BasicReadWrite.kt
package propertydelegation
import atomictest.eq
import kotlin.reflect.KProperty
class ReadWriteable(var i: Int) {
var msg = ""
var value: String by BasicReadWrite()
}
class BasicReadWrite {
operator fun getValue(
rw: ReadWriteable,
property: KProperty<*>
) = "getValue: ${rw.i}"
operator fun setValue(
rw: ReadWriteable,
property: KProperty<*>,
s: String
) {
rw.i = s.toIntOrNull() ?: 0
rw.msg = "setValue to ${rw.i}"
}
}
fun main() {
val x = ReadWriteable(11)
x.value eq "getValue: 11"
x.value = "99"
x.msg eq "setValue to 99"
x.value eq "getValue: 99"
}
前两个 setValue() 参数与 getValue() 相同,第三个是 = 右侧的值,即我们要设置的值。getValue() 和 setValue() 必须就读和写的类型达成一致,本例中为 String(ReadWriteable 中 value 的类型)。
注意,setValue() 访问了 ReadWriteable 中的 i 和 msg。
BasicRead.kt 和 BasicReadWrite.kt 并没有实现一个 interface。一个类可以作为委托使用,只要它符合具有必要的函数和必要签名的约定即可。然而,你也可以像在 BasicRead2 中看到的那样实现 ReadOnlyProperty interface:
// PropertyDelegation/BasicRead2.kt
package propertydelegation
import atomictest.eq
import kotlin.properties.ReadOnlyProperty
import kotlin.reflect.KProperty
class Readable2(val i: Int) {
val value: String by BasicRead2()
// SAM 转换:
val value2: String by
ReadOnlyProperty { _, _ -> "getValue: $i" }
}
class BasicRead2 :
ReadOnlyProperty<Readable2, String> {
override operator fun getValue(
thisRef: Readable2,
property: KProperty<*>
) = "getValue: ${thisRef.i}"
}
fun main() {
val x = Readable2(11)
val y = Readable2(17)
x.value eq "getValue: 11"
x.value2 eq "getValue: 11"
y.value eq "getValue: 17"
y.value2 eq "getValue: 17"
}
实现 ReadOnlyProperty 向读者传达了 BasicRead2 可以作为委托使用,并确保了适当的 getValue() 定义。
由于 ReadOnlyProperty 只有一个成员函数(并且它在标准库中被定义为 fun interface),value2 可以使用 SAM 转换 更简洁地定义。
BasicReadWrite.kt 可以修改为实现 ReadWriteProperty,以确保适当的 getValue() 和 setValue() 定义:
// PropertyDelegation/BasicReadWrite2.kt
package propertydelegation
import atomictest.eq
import kotlin.properties.ReadWriteProperty
import kotlin.reflect.KProperty
class ReadWriteable2(var i: Int) {
var msg = ""
var value: String by BasicReadWrite2()
}
class BasicReadWrite2 :
ReadWriteProperty<ReadWriteable2, String> {
override operator fun getValue(
rw: ReadWriteable2,
property: KProperty<*>
) = "getValue: ${rw.i}"
override operator fun setValue(
rw: ReadWriteable2,
property: KProperty<*>,
s: String
) {
rw.i = s.toIntOrNull() ?: 0
rw.msg = "setValue to ${rw.i}"
}
}
fun main() {
val x = ReadWriteable2(11)
x.value eq "getValue: 11"
x.value = "99"
x.msg eq "setValue to 99"
x.value eq "getValue: 99"
}
因此,委托类必须包含以下函数中的一个或两个,当访问委托属性时将调用这些函数:
-
用于读取:
operator fun getValue(thisRef: T, property: KProperty<*>): V -
用于写入:
setValue(thisRef: T, property: KProperty<*>, value: V)
如果委托属性是 val,则只需要第一个函数,可以使用 [SAM 转换](se
05-ch01.md#sam-转换) 实现 ReadOnlyProperty。
参数是:
thisRef: T指向委托对象,其中T是该委托的类型。如果你在函数中不想使用thisRef,你可以使用Any?作为T来有效地禁用它。property: KProperty<*>提供有关属性本身的信息。最常用的是name,它产生委托属性的字段名。value是setValue()存储到委托属性中的值。V是该属性的类型。
getValue() 和 setValue() 可以按照约定进行定义,也可以作为 ReadOnlyProperty 或 ReadWriteProperty 的实现编写。
要启用对 private 元素的访问,嵌套委托类:
// PropertyDelegation/Accessibility.kt
package propertydelegation
import atomictest.eq
import kotlin.properties.ReadOnlyProperty
import kotlin.reflect.KProperty
class Person(
private val first: String,
private val last: String
) {
val name by // SAM 转换:
ReadOnlyProperty<Person, String> { _, _ ->
"$first $last"
}
}
fun main() {
val alien = Person("Floopy", "Noopers")
alien.name eq "Floopy Noopers"
}
假设在委托类中有足够的访问权限,getValue() 和 setValue() 可以编写为扩展函数:
// PropertyDelegation/Add.kt
package propertydelegation2
import atomictest.eq
import kotlin.reflect.KProperty
class Add(val a: Int, val b: Int) {
val sum by Sum()
}
class Sum
operator fun Sum.getValue(
thisRef: Add,
property: KProperty<*>
) = thisRef.a + thisRef.b
fun main() {
val addition = Add(144, 12)
addition.sum eq 156
}
这样,您可以使用一个无法修改或继承的现有类,并仍然使用它来委托属性。
在这里,当您设置属性的值时,存储的数字是该值的斐波那契数,使用来自 Recursion 一节的 fibonacci() 函数:
// PropertyDelegation/FibonacciProperty.kt
package propertydelegation
import kotlin.properties.ReadWriteProperty
import kotlin.reflect.KProperty
import recursion.fibonacci
import atomictest.eq
class Fibonacci :
ReadWriteProperty<Any?, Long> {
private var current: Long = 0
override operator fun getValue(
thisRef: Any?,
property: KProperty<*>
) = current
override operator fun setValue(
thisRef: Any?,
property: KProperty<*>,
value: Long
) {
current = fibonacci(value.toInt())
}
}
fun main() {
var fib by Fibonacci()
fib eq 0L
fib = 22L
fib eq 17711L
fib = 90L
fib eq 2880067194370816120L
}
main() 中的 fib 是一个 本地委托属性 - 它是在函数中而不是类中定义的。委托属性也可以在文件范围内定义。
ReadWriteProperty 的第一个泛型参数可以是 Any?,因为我们在 Fibonacci 内部不使用它来访问任何东西,这需要特定的类型信息。相反,我们在任何成员函数中一样操作 current 属性。
在我们迄今为止看到的大多数示例中,getValue() 和 setValue() 的第一个参数都是特定类型的。那些委托与该特定类型绑定。有时,可以通过将第一个类型忽略为 Any? 来创建一个通用的委托。例如,假设我们希望将每个委托的 String 属性存储在以该属性命名的文本文件中:
// PropertyDelegation/FileDelegate.kt
package propertydelegation
import kotlin.properties.ReadWriteProperty
import kotlin.reflect.KProperty
import checkinstructions.DataFile
class FileDelegate :
ReadWriteProperty<Any?, String> {
override fun getValue(
thisRef: Any?,
property: KProperty<*>
): String {
val file =
DataFile(property.name + ".txt")
return if (file.exists())
file.readText()
else ""
}
override fun setValue(
thisRef: Any?,
property: KProperty<*>,
value: String
) {
DataFile(property.name + ".txt")
.writeText(value)
}
}
这个委托只需要与文件交互,并且不需要通过 thisRef 访问任何东西。我们通过将 thisRef 类型定义为 Any? 来忽略 thisRef,因为 Any? 没有有趣的操作。我们对 property.name 感兴趣,它是字段的名称。现在,我们可以自动创建与每个属性关联的文件,并将该属性的数据存储在该文件中:
// PropertyDelegation/Configuration.kt
package propertydelegation
import checkinstructions.DataFile
import atomictest.eq
class Configuration {
var user by FileDelegate()
var id by FileDelegate()
var project by FileDelegate()
}
fun main() {
val config = Configuration()
config.user = "Luciano"
config.id = "Ramalho47"
config.project = "MyLittlePython"
DataFile("user.txt").readText() eq "Luciano"
DataFile("id.txt").readText() eq "Ramalho47"
DataFile("project.txt").readText() eq
"MyLittlePython"
}
因为它可以忽略周围的类型,所以 FileDelegate 是可重用的。
练习和解答可在 www.AtomicKotlin.com 找到。
属性委托工具
标准库包含特殊的属性委托操作。
Map 是 Kotlin 标准库中少数几种预配置用作委托属性的类型之一。一个 Map 可以用于存储类中的所有属性。每个属性标识符都成为映射的 String 键,属性的类型则在关联的值中捕获:
// DelegationTools/CarService.kt
package propertydelegation
import atomictest.eq
class Driver(
map: MutableMap<String, Any?>
) {
var name: String by map
var age: Int by map
var id: String by map
var available: Boolean by map
var coord: Pair<Double, Double> by map
}
fun main() {
val info = mutableMapOf<String, Any?>(
"name" to "Bruno Fiat",
"age" to 22,
"id" to "X97C111",
"available" to false,
"coord" to Pair(111.93, 1231.12)
)
val driver = Driver(info)
driver.available eq false
driver.available = true
info eq "{name=Bruno Fiat, age=22, " +
"id=X97C111, available=true, " +
"coord=(111.93, 1231.12)}"
}
注意,当设置 driver.available = true 时,原始的 Map info 被修改。这是因为 Kotlin 标准库包含了 Map 扩展函数 getValue() 和 setValue(),它们使得属性委托成为可能。以下是它们的简化版本,展示了它们的工作原理:
// DelegationTools/MapAccessors.kt
package delegationtools
import kotlin.reflect.KProperty
operator fun MutableMap<String, Any>.getValue(
thisRef: Any?, property: KProperty<*>
): Any? {
return this[property.name]
}
operator fun MutableMap<String, Any>.setValue(
thisRef: Any?, property: KProperty<*>,
value: Any
) {
this[property.name] = value
}
要查看实际的库定义,在 IntelliJ IDEA 或 Android Studio 中将光标放在 by 关键字上,然后调用 “转到声明”。
Delegates.observable() 可以观察可变属性的修改。在这里,我们追踪旧值和新值:
// DelegationTools/Team.kt
package delegationtools
import kotlin.properties.Delegates.observable
import atomictest.eq
class Team {
var msg = ""
var captain: String by observable("<0>") {
prop, old, new ->
msg += "${prop.name} $old to $new "
}
}
fun main() {
val team = Team()
team.captain = "Adam"
team.captain = "Amanda"
team.msg eq "captain <0> to Adam " +
"captain Adam to Amanda"
}
observable() 接受两个参数:
- 属性的初始值;在这里是
"<0>"。 - 一个函数,当属性被修改时要执行的操作。在这里,我们使用了一个 lambda。函数的参数是正在更改的属性、该属性当前的值以及正在更改为的值。
Delegates.vetoable() 允许您在新属性值不满足给定谓词时阻止对属性的更改。在这里,aName() 坚持要求团队队长的名字以字母 “A” 开头:
// DelegationTools/TeamWithTraditions.kt
package delegationtools
import atomictest.*
import kotlin.properties.Delegates
import kotlin.reflect.KProperty
fun aName(
property: KProperty<*>,
old: String,
new: String
) = if (new.startsWith("A")) {
trace("$old -> $new")
true
} else {
trace("Name must start with 'A'")
false
}
interface Captain {
var captain: String
}
class TeamWithTraditions : Captain {
override var captain: String
by Delegates.vetoable("Adam", ::aName)
}
class TeamWithTraditions2 : Captain {
override var captain: String
by Delegates.vetoable("Adam") {
_, old, new ->
if (new.startsWith("A")) {
trace("$old -> $new")
true
} else {
trace("Name must start with 'A'")
false
}
}
}
fun main() {
listOf(
TeamWithTraditions(),
TeamWithTraditions2()
).forEach {
it.captain = "Amanda"
it.captain = "Bill"
it.captain eq "Amanda"
}
trace eq """
Adam -> Amanda
Name must start with 'A'
Adam -> Amanda
Name must start with 'A'
"""
}
Delegates.vetoable() 接受两个参数:属性的初始值,以及一个 onChange() 函数,这在这个例子中是 ::aName。onChange() 接受三个参数:property: KProperty<*>,属性当前持有的 old 值,以及放置在属性中的 new 值。该函数返回一个 Boolean,指示更改是否成功或被阻止。
TeamWithTraditions2 使用了一个 lambda 定义了 Delegates.vetoable(),而不是函数 aName()。
properties.Delegates 中剩余的工具是 notNull(),它生成一个必须在读取之前初始化的属性:
// DelegationTools/NeverNull.kt
package delegationtools
import atomictest.*
import kotlin.properties.Delegates
class NeverNull {
var nn: Int by Delegates.notNull()
}
fun main() {
val non = NeverNull()
capture {
non.nn
} eq "IllegalStateException: Property " +
"nn should be initialized before get."
non.nn = 11
non.nn eq 11
}
在为 nn 分配值之前尝试读取 non.nn 会产生异常。在为 nn 分配值之后,可以成功读取它。
练习和解答可在 www.AtomicKotlin.com 找到。
惰性初始化
到目前为止,你学习了两种初始化属性的方式。
- 在定义点或构造函数中存储初始值。
- 定义一个自定义的 getter,每次访问时计算属性的值。
这个章节探讨了第三种用例:昂贵的初始化,你可能不需要立即进行,甚至可能永远都不需要。例如:
- 复杂且耗时的计算
- 网络请求
- 数据库访问
这可能会产生两个问题:
- 长时间的应用程序启动时间。
- 为从未使用过的属性执行不必要的工作,或者为具有延迟访问的属性执行工作。
这种情况经常发生,Kotlin 包含了一个内置的解决方案。lazy 属性是在第一次使用时初始化的,而不是在创建时初始化。如果我们从不使用 lazy 属性,它就永远不会执行那个昂贵的初始化。
lazy 属性的概念在 Kotlin 中并不是唯一的。无论编程语言是否直接提供支持,惰性都可以在其他语言中实现。Kotlin 使用 属性委托 提供了一种一致且可识别的惯用法来处理这类属性。对于 lazy 属性,by 后面跟着对 lazy() 的调用:
val lazyProperty by lazy { initializer }
lazy() 接受一个包含初始化逻辑的 lambda。像往常一样,lambda 中的最后一个表达式将成为结果,然后赋值给属性:
// LazyInitialization/LazySyntax.kt
package lazyinitialization
import atomictest.*
val idle: String by lazy {
trace("Initializing 'idle'")
"I'm never used"
}
val helpful: String by lazy {
trace("Initializing 'helpful'")
"I'm helping!"
}
fun main() {
trace(helpful)
trace eq """
Initializing 'helpful'
I'm helping!
"""
}
idle 属性不会被初始化,因为从未访问过它。
请注意,helpful 和 idle 都是 val。如果没有 lazy 初始化,你将被迫将它们定义为 var,从而产生不太可靠的代码。
我们可以通过为 Int 属性实现与 lazy 初始化相同的行为,来看看 lazy 初始化为我们做了哪些工作:
// LazyInitialization/LazyInt.kt
package lazyinitialization
import atomictest.*
class LazyInt(val init: () -> Int) {
private var helper: Int? = null
val value: Int
get() {
if (helper == null)
helper = init()
return helper!!
}
}
fun main() {
val later = LazyInt {
trace("Initializing 'later'")
5
}
trace("First 'value' access:")
trace(later.value)
trace("Second 'value' access:")
trace(later.value)
trace eq """
First 'value' access:
Initializing 'later'
5
Second 'value' access:
5
"""
}
value 属性不存储值,而是具有从 helper 属性中检索值的 getter。这与 Kotlin 为 lazy 生成的代码类似。
现在我们可以比较三种初始化属性的方式——在定义点、使用 getter,以及使用 lazy 初始化:
// LazyInitialization/PropertyOptions.kt
package lazyinitialization
import atomictest.trace
fun compute(i: Int): Int {
trace("Compute $i")
return i
}
object Properties {
val atDefinition = compute(1)
val getter
get() = compute(2)
val lazyInit by lazy { compute(3) }
val never by lazy { compute(4) }
}
fun main() {
listOf(
Properties::atDefinition,
Properties::getter,
Properties::lazyInit
).forEach {
trace("${it.name}:")
trace("${it.get()}")
trace("${it.get()}")
}
trace eq """
Compute 1
atDefinition:
1
1
getter:
Compute 2
2
Compute 2
2
lazyInit:
Compute 3
3
3
"""
}
atDefinition在创建Properties实例时初始化。- “Compute 1” 出现在 “atDefinition:” 之前,显示初始化发生在任何访问之前。
getter每次访问时都会重新计算。两次访问属性时都会出现一次 “Compute 2”。lazyInit的初始化值仅在首次访问时计算。如果不访问该属性,初始化永远不会发生,注意在跟踪中从未出现 “Compute 4”。
练习和解答可在 www.AtomicKotlin.com 找到。
延迟初始化
有时候,你想在创建类的实例后才初始化属性,但是想在一个单独的成员函数中进行初始化,而不是使用
lazy。
例如,一个框架或库可能要求在特殊函数中进行初始化。如果你扩展了该库的类,你可以提供自己的特殊函数的实现。
考虑一个具有 setUp() 函数来初始化实例的 Bag 接口:
// LateInitialization/Bag.kt
package lateinitialization
interface Bag {
fun setUp()
}
假设我们想要重用一个创建和操作 Bag 的库,并保证调用了 setUp()。该库要求在 setUp() 中进行子类初始化,而不是在构造函数中:
// LateInitialization/Suitcase.kt
package lateinitialization
import atomictest.eq
class Suitcase : Bag {
private var items: String? = null
override fun setUp() {
items = "socks, jacket, laptop"
}
fun checkSocks(): Boolean =
items?.contains("socks") ?: false
}
fun main() {
val suitcase = Suitcase()
suitcase.setUp()
suitcase.checkSocks() eq true
}
Suitcase 通过覆盖 setUp() 来初始化 items。然而,我们不能仅仅将 items 定义为一个 String —— 如果这样做,我们必须在构造函数中提供一个非空的初始化值。使用空字符串等存根值是一个不好的做法,因为你永远不知道它是否实际被初始化过。null 表示尚未初始化。
将 items 定义为可为空的 String? 意味着我们必须在所有成员函数中检查 null,如 checkSocks()。然而,我们知道我们正在重用的库通过调用 setUp() 来初始化 items,因此 null 检查不应该是必要的。
lateinit 属性修饰符可以解决这个问题 —— 在创建 BetterSuitcase 实例后,我们初始化 items:
// LateInitialization/BetterSuitcase.kt
package lateinitialization
import atomictest.eq
class BetterSuitcase : Bag {
lateinit var items: String
override fun setUp() {
items = "socks, jacket, laptop"
}
fun checkSocks() = "socks" in items
}
fun main() {
val suitcase = BetterSuitcase()
suitcase.setUp()
suitcase.checkSocks() eq true
}
将这个版本的 checkSocks() 与 Suitcase.kt 中的版本进行比较。lateinit 意味着 items 被安全地定义为非空属性。
lateinit 可以用于类体内的属性、顶层属性或局部 var。
限制:
lateinit只能用于var属性,不能用于val。- 属性必须是非空类型。
- 属性不能是原始类型。
abstract类或interface中的abstract属性不允许使用lateinit。- 具有自定义
get()或set()的属性不允许使用lateinit。
如果你忘记初始化这样的属性会发生什么?你不会得到编译时的错误或警告,因为初始化逻辑可能很复杂,并且可能依赖于 Kotlin 无法监视的其他属性:
// LateInitialization/FaultySuitcase.kt
package lateinitialization
import atomictest.*
class FaultySuitcase : Bag {
lateinit var items: String
override fun setUp() {}
fun checkSocks() = "socks" in items
}
fun main() {
val suitcase = FaultySuitcase()
suitcase.setUp()
capture {
suitcase.checkSocks()
} eq
"UninitializedPropertyAccessException" +
": lateinit property items " +
"has not been initialized"
}
这个运行时异常提供了足够的细节,让你能够轻松地发现并修复问题。通常情况下,跟踪由于 null 指针异常引起的错误要困难得多。
.isInitialized 可以告诉你一个 lateinit 属性是否被初始化。该属性必须在当前作用域中,使用 :: 运算符访问:
// LateInitialization/IsInitialized.kt
package lateinitialization
import atomictest.*
class WithLate {
lateinit var x: String
fun status() = "${::x.isInitialized}"
}
lateinit var y: String
fun main() {
trace("${::y.isInitialized}")
y = "Ready"
trace("${::y.isInitialized}")
val withlate = WithLate()
trace(withlate.status())
withlate.x = "Set"
trace(withlate.status())
trace eq "false true false true"
}
虽然可以创建一个局部的 lateinit var,但你不能在其上调用 .isInitialized,因为不支持对局部 var 或 val 的引用。
练习和解答可在 www.AtomicKotlin.com 找到。
附录 A:AtomicTest
这个简洁的测试框架用于验证书中的例子。它还有助于在学习过程中早期引入和推广单元测试。
该框架在以下原子中进行了描述:
- 测试 介绍了该框架,并描述了
eq和neq函数以及trace对象。 - 异常 介绍了
capture()函数。 - 异常处理 描述了
capture()函数的实现。 - 单元测试 使用 AtomicTest 来帮助引入单元测试的概念。
// AtomicTest/AtomicTest.kt
package atomictest
import kotlin.math.abs
import kotlin.reflect.KClass
const val ERROR_TAG = "[Error]: "
private fun <L, R> test(
actual: L,
expected: R,
checkEquals: Boolean = true,
predicate: () -> Boolean
) {
println(actual)
if (!predicate()) {
print(ERROR_TAG)
println("$actual " +
(if (checkEquals) "!=" else "==") +
" $expected")
}
}
/**
* Compares the string representation
* of this object with the string `rval`.
*/
infix fun Any.eq(rval: String) {
test(this, rval) {
toString().trim() == rval.trimIndent()
}
}
/**
* Verifies this object is equal to `rval`.
*/
infix fun <T> T.eq(rval: T) {
test(this, rval) {
this == rval
}
}
/**
* Verifies this object is != `rval`.
*/
infix fun <T> T.neq(rval: T) {
test(this, rval, checkEquals = false) {
this != rval
}
}
/**
* Verifies that a `Double` number is equal
* to `rval` within a positive delta.
*/
infix fun Double.eq(rval: Double) {
test(this, rval) {
abs(this - rval) < 0.0000001
}
}
/**
* Holds captured exception information:
*/
class CapturedException(
private val exceptionClass: KClass<*>?,
private val actualMessage: String
) {
private val fullMessage: String
get() {
val className =
exceptionClass?.simpleName ?: ""
return className + actualMessage
}
infix fun eq(message: String) {
fullMessage eq message
}
infix fun contains(parts: List<String>) {
if (parts.any { it !in fullMessage }) {
print(ERROR_TAG)
println("Actual message: $fullMessage")
println("Expected parts: $parts")
}
}
override fun toString() = fullMessage
}
/**
* Captures an exception and produces
* information about it. Usage:
* capture {
* // Code that fails
* } eq "FailureException: message"
*/
fun capture(f:() -> Unit): CapturedException =
try {
f()
CapturedException(null,
"$ERROR_TAG Expected an exception")
} catch (e: Throwable) {
CapturedException(e::class,
(e.message?.let { ": $it" } ?: ""))
}
/**
* Accumulates output when called as in:
* trace("info")
* trace(object)
* Later compares accumulated to expected:
* trace eq "expected output"
*/
object trace {
private val trc = mutableListOf<String>()
operator fun invoke(obj: Any?) {
trc += obj.toString()
}
/**
* Compares trc contents to a multiline
* `String` by ignoring white space.
*/
infix fun eq(multiline: String) {
val trace = trc.joinToString("\n")
val expected = multiline.trimIndent()
.replace("\n", " ")
test(trace, multiline) {
trace.replace("\n", " ") == expected
}
trc.clear()
}
}
附录 B:Java 互操作性
本附录描述了在 Kotlin 和 Java 之间进行接口调用的问题和技巧。
Kotlin 的一个重要设计目标是为 Java 程序员创建无缝的体验。如果你想逐步迁移到 Kotlin,你可以轻松地在现有的 Java 项目中添加一些 Kotlin 代码。这样,你可以在现有的 Java 代码基础上编写新的 Kotlin 代码,享受 Kotlin 语言的特性,而无需在不合适的情况下强制重写 Java 代码。
不仅可以轻松地从 Kotlin 调用 Java 代码,还可以直接在 Java 程序中调用 Kotlin 代码。
从 Kotlin 调用 Java
要从 Kotlin 中使用 Java 类,只需像在 Java 中一样,导入它,创建一个实例,并调用函数。下面的示例演示了如何使用 java.util.Random():
// interoperability/Random.kt
import atomictest.eq
import java.util.Random
fun main() {
val rand = Random(47)
rand.nextInt(100) eq 58
}
与在 Kotlin 中创建任何实例一样,你不需要使用 Java 中的 new 关键字。Java 库中的类可以像本地的 Kotlin 类一样工作。
Java 类中的 JavaBean 风格的 getter 和 setter 方法在 Kotlin 中变成属性:
// interoperability/Chameleon.java
package interoperability;
import java.io.Serializable;
public
class Chameleon implements Serializable {
private int size;
private String color;
public int getSize() {
return size;
}
public void setSize(int newSize) {
size = newSize;
}
public String getColor() {
return color;
}
public void setColor(String newColor) {
color = newColor;
}
}
在使用 Java 时,包名必须与目录名相同(包括大小写)。Java 包名通常只包含小写字母。为了符合这个约定,本附录中的示例子目录名interoperability仅使用小写字母。
导入的 Chameleon 类的使用方式类似于具有属性的 Kotlin 类:
// interoperability/UseBeanClass.kt
import interoperability.Chameleon
import atomictest.eq
fun main() {
val chameleon = Chameleon()
chameleon.size = 1
chameleon.size eq 1
chameleon.color = "green"
chameleon.color eq "green"
chameleon.color = "turquoise"
chameleon.color eq "turquoise"
}
当你使用一个现有的缺少所需成员函数的 Java 库时,扩展函数尤其有用。例如,我们可以给 Chameleon 添加一个 adjustToTemperature() 操作:
// interoperability/ExtensionsToJavaClass.kt
package interop
import interoperability.Chameleon
import atomictest.eq
fun Chameleon.adjustToTemperature(
isHot: Boolean
) {
color = if (isHot) "grey" else "black"
}
fun main() {
val chameleon = Chameleon()
chameleon.size = 2
chameleon.size eq 2
chameleon.adjustToTemperature(isHot = true)
chameleon.color eq "grey"
}
Kotlin 标准库中包含了许多针对 Java 标准库中的类(如 List 和 String)的扩展函数。
从 Java 调用 Kotlin
Kotlin 生成的库可以在 Java 中使用。对于 Java 程序员来说,一个 Kotlin 库看起来就像一个 Java 库。
由于在 Java 中一切都是类,让我们从一个包含属性和函数的 Kotlin 类开始:
// interoperability/KotlinClass.kt
package interop
class Basic {
var property1 = 1
fun value() = property1 * 10
}
如果你将这个类导入到 Java 中,它看起来就像一个普通的 Java 类:
// interoperability/UsingKotlinClass.java
package interoperability;
import interop.Basic;
import static atomictest.AtomicTestKt.eq;
public class UsingKotlinClass {
public static void main(String[] args) {
Basic b = new Basic();
eq(b.getProperty1(), 1);
b.setProperty1(12);
eq(b.value(), 120);
}
}
property1 变成了一个包含 JavaBean 风格的 getter 和 setter 的 private 字段。value() 成员函数变成了一个同名的 Java 方法。
我们还导入了 AtomicTest,在 Java 中需要额外的步骤:我们必须使用 static 关键字导入它,并指定包名。eq() 只能作为普通函数调用,因为 Java 不支持中缀表示法。
如果一个 Kotlin 类与 Java 代码位于同一个包中,你就不需要导入它:
// interoperability/KotlinDataClass.kt
package interoperability
data class Staff(
var name: String,
var role: String
)
data 类会生成额外的成员函数,比如 equals()、hashCode() 和 toString(),在 Java 中都能无缝使用。在 main() 的末尾,我们通过将一个 Data 对象放入 HashMap,然后检索它,来验证 equals() 和 hashCode() 的实现:
// interoperability/UseDataClass.java
package interoperability;
import java.util.HashMap;
import static atomictest.AtomicTestKt.eq;
public class UseDataClass {
public static void main(String[] args) {
Staff e = new Staff(
"Fluffy", "Office Manager");
eq(e.getRole(), "Office Manager");
e.setName("Uranus");
e.setRole("Assistant");
eq(e,
"Staff(name=Uranus, role=Assistant)");
// Call copy() from the data class:
Staff cf = e.copy("Cornfed", "Sidekick");
eq(cf,
"Staff(name=Cornfed, role=Sidekick)");
HashMap<Staff, String> hm =
new HashMap<>();
// Employees work as hash keys:
hm.put(e, "Cheerful");
eq(hm.get(e), "Cheerful");
}
}
如果你使用命令行来运行包含 Kotlin 代码的 Java 代码,你必须将 kotlin-runtime.jar 作为依赖项包含进来,否则你将会遇到运行时异常,指出找不到某些库实用类。IntelliJ IDEA 会自动包含 kotlin-runtime.jar
。
Kotlin 顶层函数会映射到一个以 Kotlin 文件命名的 Java 类中的 static 方法:
// interoperability/TopLevelFunction.kt
package interop
fun hi() = "Hello!"
要导入该函数,需要指定 Kotlin 生成的类名。在调用该 static 方法时,也必须使用这个类名:
// interoperability/CallTopLevelFunction.java
package interoperability;
import interop.TopLevelFunctionKt;
import static atomictest.AtomicTestKt.eq;
public class CallTopLevelFunction {
public static void main(String[] args) {
eq(TopLevelFunctionKt.hi(), "Hello!");
}
}
如果你不想用包名限定 hi(),可以像我们在 AtomicTest 中所做的那样使用 import static:
// interoperability/CallTopLevelFunction2.java
package interoperability;
import static interop.TopLevelFunctionKt.hi;
import static atomictest.AtomicTestKt.eq;
public class CallTopLevelFunction2 {
public static void main(String[] args) {
eq(hi(), "Hello!");
}
}
如果你不喜欢 Kotlin 生成的类名,可以使用 @JvmName 注解来改变它:
// interoperability/ChangeName.kt
@file:JvmName("Utils")
package interop
fun salad() = "Lettuce!"
现在,我们使用 Utils 来代替 ChangeNameKt:
// interoperability/MakeSalad.java
package interoperability;
import interop.Utils;
import static atomictest.AtomicTestKt.eq;
public class MakeSalad {
public static void main(String[] args) {
eq(Utils.salad(), "Lettuce!");
}
}
你可以在文档中找到更多细节。
适应 Java 到 Kotlin
Kotlin 的一个设计目标是将现有的 Java 类型适应到你的需求中。这种能力不仅限于库设计者,相同的逻辑也可以应用于任何外部代码库。
在 Recursion 中,我们创建了 Fibonacci.kt 来高效地生成斐波那契数。该实现受到它返回的 Long 大小的限制。如果你想返回更大的值,Java 标准库中包含了 BigInteger 类。只需几行代码就可以将 BigInteger 转换成感觉像是本机 Kotlin 类的东西:
// interoperability/BigInt.kt
package biginteger
import java.math.BigInteger
fun Int.toBigInteger(): BigInteger =
BigInteger.valueOf(toLong())
fun String.toBigInteger(): BigInteger =
BigInteger(this)
operator fun BigInteger.plus(
other: BigInteger
): BigInteger = add(other)
toBigInteger() 扩展函数通过调用 BigInteger 构造函数并将接收者字符串作为参数来将任何 Int 或 String 转换为 BigInteger。
通过重载 BigInteger.plus() 操作符,你可以写成 number + other。这
使得与 BigInteger 的处理相比 Java 中笨拙的 number.plus(other) 更加愉快。
使用 BigInteger,Recursion/Fibonacci.kt 轻松转换为生成更大的结果:
// interoperability/BigFibonacci.kt
package interop
import atomictest.eq
import java.math.BigInteger
import java.math.BigInteger.ONE
import java.math.BigInteger.ZERO
fun fibonacci(n: Int): BigInteger {
tailrec fun fibonacci(
n: Int,
current: BigInteger,
next: BigInteger
): BigInteger {
if (n == 0) return current
return fibonacci(
n - 1, next, current + next) // [1]
}
return fibonacci(n, ZERO, ONE)
}
fun main() {
(0..7).map { fibonacci(it) } eq
"[0, 1, 1, 2, 3, 5, 8, 13]"
fibonacci(22) eq 17711.toBigInteger()
fibonacci(150) eq
"9969216677189303386214405760200"
.toBigInteger()
}
所有的 Long 都被替换为 BigInteger。在 main() 中,你可以看到使用不同的 toBigInteger() 扩展函数将 Int 和 String 转换为 BigInteger。在第 [1] 行中,我们使用 plus 操作符来计算 current + next 的和;这与使用 Long 的原始版本完全相同。
fibonacci(150) 在 Recursion/Fibonacci.kt 版本中会溢出,但在转换为 BigInteger 后可以正常工作。
Java Checked Exceptions & Kotlin
Java引入了被称为“checked exceptions”的特性,这使得在调用函数时必须捕获每个指定的异常。在Java中,如果你不在try块中处理这些异常,编译时会产生错误。这在某种程度上增加了代码的安全性,但也增加了编码的复杂性。
下面是一个在Java中打开、读取和关闭文件的示例,演示了checked exceptions的使用:
// interoperability/JavaChecked.java
package interoperability;
import java.io.*;
import java.nio.file.*;
import static atomictest.AtomicTestKt.eq;
public class JavaChecked {
// 根据在Gradle调用的目录构建当前源文件的路径:
static Path thisFile = Paths.get(
"DataFiles", "file_wubba.txt");
public static void main(String[] args) {
BufferedReader source = null;
try {
source = new BufferedReader(
new FileReader(thisFile.toFile()));
} catch(FileNotFoundException e) {
// 从文件打开错误中恢复
}
try {
String first = source.readLine();
eq(first, "wubba lubba dub dub");
} catch(IOException e) {
// 从读取错误中恢复
}
try {
source.close();
} catch(IOException e) {
// 从关闭错误中恢复
}
}
}
上述代码中的每个操作都涉及到checked exceptions,必须将其放在try块中,否则Java会产生编译时错误。
在这个示例中,异常的处理方式似乎不太合理,但你仍然被迫编写try-catch块。
让我们在Kotlin中重写这个示例:
// interoperability/KotlinChecked.kt
import atomictest.eq
import java.io.File
fun main() {
File("DataFiles/file_wubba.txt")
.readLines()[0] eq
"wubba lubba dub dub"
}
Kotlin允许我们将操作简化为一行代码,因为它为Java的File类添加了扩展函数。同时,Kotlin消除了checked exceptions。如果需要,我们可以在中间操作中使用try-catch块,但Kotlin不强制要求使用checked exceptions,这样就可以在不增加额外噪音代码的情况下提供错误报告。
Java库经常在程序员无法控制且通常无法恢复的情况下使用checked exceptions。在这些情况下,最好在顶层捕获异常并重新启动进程(如果可能)。要求所有中间层都传递异常只会增加理解代码时的认知负担。
如果你正在编写从Java调用的Kotlin代码,并且必须指定一个checked exception,Kotlin提供了@Throws注解,以便将此信息传递给Java调用者:
// interoperability/AnnotateThrows.kt
package interop
import java.io.IOException
@Throws(IOException::class)
fun hasCheckedException() {
throw IOException
()
}
以下是如何从Java中调用hasCheckedException()的示例:
// interoperability/CatchChecked.java
package interoperability;
import interop.AnnotateThrowsKt;
import java.io.IOException;
import static atomictest.AtomicTestKt.eq;
public class CatchChecked {
public static void main(String[] args) {
try {
AnnotateThrowsKt.hasCheckedException();
} catch(IOException e) {
eq(e, "java.io.IOException");
}
}
}
如果你不处理异常,Java编译器会报错。
尽管Kotlin包括异常处理的语言支持,但它更注重错误报告,并将异常处理保留给那些在实际情况下可以从问题中恢复的情况(几乎只限于I/O操作)。
Nullable类型和Java
Kotlin确保纯粹的 Kotlin代码不会出现null错误,但是当你调用Java代码时,就没有这样的保证。在下面的Java代码中,get()有时会返回null:
// interoperability/JTool.java
package interoperability;
public class JTool {
public static JTool get(String s) {
if(s == null) return null;
return new JTool();
}
public String method() {
return "Success";
}
}
要在Kotlin中使用JTool,你必须了解get()的行为。在下面的示例中,我们提供了三种选择,分别对应于a、b和c的定义:
// interoperability/PlatformTypes.kt
package interop
import interoperability.JTool
import atomictest.eq
object KotlinCode {
val a: JTool? = JTool.get("") // [1]
val b: JTool = JTool.get("") // [2]
val c = JTool.get("") // [3]
}
fun main() {
with(KotlinCode) {
a?.method() eq "Success" // [4]
b.method() eq "Success"
c.method() eq "Success" // [5]
::a.returnType eq
"interoperability.JTool?"
::b.returnType eq
"interoperability.JTool"
::c.returnType eq
"interoperability.JTool!" // [6]
}
}
- [1] 将类型指定为可为空。
- [2] 将类型指定为非空。
- [3] 使用类型推断。
main()中的with()允许我们在不使用KotlinCode限定的情况下引用a、b和c。由于这些标识符在object内部,我们可以使用成员引用语法和returnType属性来确定它们的类型。
要初始化a、b和c,我们向get()传递了一个非空字符串,因此a、b和c最终都具有非空引用,并且每个引用都可以成功调用method()。
- [4] 由于
a可为空,因此在调
用成员函数时必须使用?.。
- [5]
c的行为类似于非空引用,可以直接解引用而无需进行额外的检查。 - [6] 注意,
c既不返回可空类型也不返回非空类型,而是返回完全不同的类型:JTool!。
Type!是Kotlin的平台类型,它没有表示法,你不能将其写入代码中。它用于Kotlin必须推断其域之外的类型时。
如果一个类型来自Java,访问它可能会产生空指针异常(NPE)。下面是当JTool.get()返回null引用时会发生的情况:
// interoperability/NPEOnPlatformType.kt
import interoperability.JTool
import atomictest.*
fun main() {
val xn: JTool? = JTool.get(null) // [1]
xn?.method() eq null
val yn = JTool.get(null) // [2]
yn?.method() eq null // [3]
capture {
yn.method() // [4]
} contains listOf("NullPointerException")
capture {
val zn: JTool = JTool.get(null) // [5]
} eq "NullPointerException: " +
"JTool.get(null) must not be null"
}
当你在Kotlin中调用像JTool.get()这样的Java方法时,其返回值(除非通过下一节中解释的注解进行了标注)是一个平台类型,在这种情况下是JTool!。
- [1] 由于
xn是可为空类型JTool?,因此可以成功接收null。将值分配给可为空类型是安全的,因为Kotlin要求你在调用method()时使用?.进行null检查。 - [2] 在定义的时候,
yn可以成功接收null而不会产生警告,因为Kotlin将其推断为平台类型JTool!。 - [3] 你可以使用安全访问调用
?.来解引用yn,这种情况下它返回null。 - [4] 但是,使用
?.并不是必需的。你可以直接解引用yn。在这种情况下,你会得到一个空指针异常,而没有任何有用的信息。 - [5] 分配给非空类型可能会导致空指针异常。Kotlin在赋值点检查null性。初始化
zn失败,因为声明的类型JTool承诺zn不可为空,但它接收到了null,从而产生了空指针异常,这次带有一个有用的错误信息。
异常消息包含有关产生null的表达式的详细信息:NullPointerException: JTool.get(null) must not be null。即使它是一个运行时异常,但是全面的错误消息使问题比修复常规空指针异常更
容易。
总之,当在Kotlin中调用Java代码时,你需要考虑平台类型和可能的空指针异常。通过使用安全访问操作符?.并进行适当的空值检查,可以减少空指针异常的风险。
空值注解
如果你控制Java代码库,你可以为Java代码添加空值注解,从而避免微妙的空指针异常错误。@Nullable和@NotNull告诉Kotlin将Java类型视为可为空或不可为空。以下是我们在JTool.java中为Kotlin添加空值注解的示例:
// interoperability/AnnotatedJTool.java
package interoperability;
import org.jetbrains.annotations.NotNull;
import org.jetbrains.annotations.Nullable;
public class AnnotatedJTool {
@Nullable
public static JTool
getUnsafe(@Nullable String s) {
if(s == null) return null;
return getSafe(s);
}
@NotNull
public static JTool
getSafe(@NotNull String s) {
return new JTool();
}
public String method() {
return "Success";
}
}
在Java参数前应用注解仅影响该参数。在Java方法前应用注解则修改了返回类型。
当你在Kotlin中调用getUnsafe()和getSafe()时,Kotlin会将AnnotatedJTool成员函数视为本机Kotlin可空或非空类型:
// interoperability/AnnotatedJava.kt
package interop
import interoperability.AnnotatedJTool
import atomictest.eq
object KotlinCode2 {
val a = AnnotatedJTool.getSafe("")
// 不会编译通过:
// val b = AnnotatedJTool.getSafe(null)
val c = AnnotatedJTool.getUnsafe("")
val d = AnnotatedJTool.getUnsafe(null)
}
fun main() {
with(KotlinCode2) {
::a.returnType eq
"interoperability.JTool"
::c.returnType eq
"interoperability.JTool?"
::d.returnType eq
"interoperability.JTool?"
}
}
@NotNull JTool被转换为Kotlin的不可为空类型JTool,而带注解的@Nullable JTool则被转换为Kotlin的JTool?。你可以在main()中查看a、c和d的类型展示。
当期望一个非可空参数时,无法传递可为空的参数,即使它是用@NotNull注解的Java类型。因此,Kotlin不会编译通过AnnotatedJTool.getSafe(null)。
支持不同种类的空值注解,它们使用不同的名称:
@Nullable和@CheckForNull是由JSR-305标准指定的。@Nullable和@NonNull在Android中使用。@Nullable和@NotNull由JetBrains工具支持。- 还有其他的注解。你可以在Kotlin 文档中找到完整的列表。
Kotlin可以检测Java包或类的默认空值注解,这些注解在JSR-305标准中指定。如果默认情况下是@NotNull,则应该明确指定@Nullable注解。如果默认情况下是@Nullable,则应该明确指定@NotNull注解。文档中包含选择默认注解的技术细节。
如果您开发混合Kotlin和Java的项目,使用Java代码中的空值注解可以使您的应用程序更安全。
集合与Java
这本书不需要Java知识。然而,当您在Java虚拟机(JVM)上编写Kotlin代码时,熟悉Java标准集合库会很有帮助,因为Kotlin使用它来创建自己的集合。
Java集合库是一组实现集合数据结构(如列表、集合和映射)的类和接口。这些数据结构通常具有清晰简单的接口,但为了提高速度可能有复杂的实现。
新的编程语言通常会从头开始创建自己的集合库。例如,Scala语言有自己的集合库,在许多方面超越了Java集合库,但也增加了在Scala和Java之间混合使用的挑战。
Kotlin的集合库有意地没有从头开始重新编写。相反,它在Java集合库的基础上进行了改进。例如,当您创建一个可变的List时,实际上是使用Java的ArrayList:
// interoperability/HiddenArrayList.kt
import atomictest.eq
fun main() {
val list = mutableListOf(1, 2, 3)
list.javaClass.name eq
"java.util.ArrayList"
}
为了与Java代码无缝互操作,Kotlin使用Java标准库中的接口和常用实现。这带来了三个好处:
- Kotlin代码可以轻松与Java代码混合使用。在将Kotlin集合传递给Java代码时,不需要进行额外的转换。
- Java标准库中多年的性能调优对Kotlin程序员来说自动可用。
- Kotlin应用程序附带的标准库很小,因为它使用Java集合而不是定义自己的集合。Kotlin标准库主要包含改进Java集合的扩展函数。
此外,Kotlin还修复了一个设计问题。在Java中,所有的集合接口都是可变的。例如,java.util.List具有修改列表的add()和remove()方法。正如本书中所展示的那样,可变性是许多编程问题的根源。因此,在Kotlin中,默认的Collection类型是只读的:
// interoperability/ReadOnlyByDefault.kt
package interop
data class Animal(val name: String)
interface Zoo {
fun viewAnimals(): Collection<Animal>
}
fun visitZoo(zoo: Zoo) {
val animals = zoo.viewAnimals()
// Compile-time error:
// animals.add(Animal("Grumpy Cat"))
}
只读集合更安全、更不容易出错,因为它们防止了意外修改。
Java提供了一种部分解决集合不可变性的方法:当返回一个集合时,你可以将其放在一个特殊的包装器中,对任何试图修改底层集合的操作抛出异常。这虽然不能产生静态类型检查,但仍然可以防止出现微妙的错误。然而,你必须记住在返回集合时进行包装,使其成为只读的,而在Kotlin中,你必须在想要一个可变集合时明确声明。
Kotlin有用于可变和只读集合的不同接口:
Collection/MutableCollectionList/MutableListSet/MutableSetMap/MutableMap
这些接口与Java标准库中的接口相对应:
java.util.Collectionjava.util.Listjava.util.Setjava.util.Map
在Kotlin中,与Java一样,Collection是List和Set的超类型。MutableCollection扩展自Collection,是MutableList和MutableSet的超类型。以下是基本结构的示例:
// interoperability/CollectionStructure.kt
package collectionstructure
interface Collection<E>
interface List<E>: Collection<E>
interface Set<E>: Collection<E>
interface Map<K, V>
interface MutableCollection<E>
interface MutableList<E>:
List<E>, MutableCollection<E>
interface MutableSet<E>:
Set<E>, MutableCollection<E>
interface MutableMap<K, V>: Map<K, V>
为简单起见,我们只显示了Kotlin标准库中的名称,而没有显示完整的声明。
Kotlin的可变集合与其Java对应物相匹配。如果你将kotlin.collections中的MutableCollection与java.util.List进行比较,你会发现它们声明了相同的成员函数(在Java术语中称为方法)。Kotlin的Collection、List、Set和Map也复制了Java的接口,但没有包含任何修改方法。
kotlin.collections.List和kotlin.collections.MutableList都可以从Java中看到,它们被视为java.util.List。这些接口是特殊的:它们只存在于Kotlin中,但在字节码级别上,它们都被替换为Java的List。
Kotlin的List可以转换为Java的List:
// interoperability/JavaList.kt
import atomictest.eq
fun main() {
val list = listOf(1, 2, 3)
(list is java.util.List<*>) eq true
}
这段代码会产生一个警告:
- 在Kotlin中不应使用这个类。
- 请使用kotlin.collections.List或kotlin.collections.MutableList代替。
这是提醒在Kotlin编程时要使用Kotlin的接口而不是Java的接口。
请记住,只读不等同于不可变。通过只读引用,无法修改集合,但是它仍然可以被改变:
// interoperability/ReadOnlyCollections.kt
import atomictest.eq
fun main() {
val mutable = mutableListOf(1, 2, 3)
// 只读引用指向可变列表:
val list: List<Int> = mutable
mutable += 4
// list已经改变:
list eq "[1, 2, 3, 4]"
}
在这个例子中,只读的list引用了一个MutableList,然后通过操作mutable对其进行修改。因为所有的Java集合都是可变的,所以Java代码可以修改只读的Kotlin集合,即使你通过只读引用传递给它。
Kotlin集合并不能完全确保安全性,但在提供更好的库和保持与Java的兼容性之间提供了一个良好的平衡。
Java基本类型
在Kotlin中,你调用构造函数来创建一个对象,但在Java中,你必须使用new关键字来生成一个对象。new会将结果对象放在堆上。这些类型被称为引用类型。
对于基本类型(如数字),在堆上创建对象可能效率较低。对于这些类型,Java采用了C和C++的方法:不使用new关键字创建变量,而是创建一个非引用的“自动”变量,直接保存该值。自动变量被放置在栈上,使其更高效。这些类型在JVM上得到了特殊处理,被称为原始类型。
原始类型有固定的数量:boolean、int、long、char、byte、short、float和double。原始类型总是包含非null值,不能用作泛型参数。如果需要存储null或将这些类型用作泛型参数,可以使用Java标准库中定义的相应引用类型,如java.lang.Boolean或java.lang.Integer。这些类型通常被称为包装类型或装箱类型,以强调它们仅包装原始值并将其存储在堆上。
// interoperability/JavaWrapper.java
package interoperability;
import java.util.*;
public class JavaWrapper {
public static void main(String[] args) {
// 原始类型
int i = 10;
// 包装类型
Integer iOrNull = null;
List<Integer> list = new ArrayList<>();
}
}
Java区分引用类型和原始类型,但Kotlin不区分。你在定义整数的var/val或在使用它作为泛型参数时使用相同的Int类型。在JVM级别,Kotlin使用相同的原始类型支持。在生成字节码时,Kotlin会尽可能地将Int替换为原始类型int。只有使用包装类型才能表示可空的Int?或用作泛型参数的Int:
// interoperability/KotlinWrapper.kt
package interop
fun main() {
// 生成原始类型int:
val i = 10
// 生成包装类型:
val iOrNull: Int? = null
val list: List<Int> = listOf(1, 2, 3)
}
通常情况下,你不需要过多考虑Kotlin编译器生成的是原始类型还是包装类型,但了解它在JVM上的实现方式是有用的。
文档详细解释了Kotlin/Java互操作性的细微差别。